Process Step Reference Guide – Library
All Process Steps are in the Process Step Toolbox located in the upper right hand corner of the Business Process Designer. When Process Steps are initially placed onto a Business Process, or when they are mis-configured, they will display a yellow warning icon indicating that configuration of the Process Step is required or incorrect (see Figure 69). Once configured correctly, the icon will be automatically removed.

Process Steps can be added to any Execution Block within a Process Step by dragging them from the Process Step Toolbox and placing them onto the Execution Block or, by right clicking on the Execution Block and selecting the Process Step from the short cut menu displayed. Selecting any of the Process Steps in the short cut menu will insert the selected Process Step into the Execution Block.
Library
Error Handling
Exception
| Category: | Error Handling |
| Class: | ExceptionPipelineStep |
| Namespace: | Neuron.Pipelines |
| Assembly: | Neuron.Pipelines.dll |
Description:
An Exception Process Step is comprised of three execution blocks: Try, Catch and Finally. Encapsulating process steps inside an Exception step allows for further processing in the event of any errors, similar to the .NET-programming model. For instance, several Process Steps could be placed within the Try Execution Block. If any exception occurs either during design time testing, or run time, control will immediately go to the Catch Execution Block, rather than fault the entire Business Process. Within the Catch Execution Block, the current exception could be examined and corrective action could be taken. Alternatively, the exception could be re-thrown by using the Rethrow Process Step, automatically faulting the entire Business Process, providing that the Exception Step is not contained within another Exception Step.
Catch Block
If a Process Step encounters an exception while processing a message it will throw the exception as the inner exception of a new PipelineException object. The PipelineException object will contain the name of the Business Process and Process Step that generated the exception. If the Process Step is located in the Try Block of the Exception Process Step, flow control will move to the Catch Block.
Within the Catch Block, the exception information can be retrieved by accessing the Properties collection of the context object as shown below:
var ex =
(PipelineException)context.Properties["PipelineException"];
If an Audit Process Step is used and its Action property is set to Failure, its Failure Type and Failure Detail properties will be auto populated by the PipelineException objects inner exception property (i.e. the original exception thrown by the Process Step).
Developers can use a .NET Language Code Process Step to implement custom tracing of the information as shown in the example below:
var ex =
(PipelineException)context.Properties["PipelineException"];
if(context.Instance.IsErrorEnabled)
{
context.Instance.TraceError("Business Process name = " + ex.Pipeline);
context.Instance.TraceError("Process Step name = " + ex.PipelineStep);
context.Instance.TraceError(ex.ToString());
}
Finally Block
All Process Steps placed within the Finally Execution Block will always run regardless of how the exception is handled or if an exception is encountered. The Finally execution block would normally be used if there was any necessary cleanup work to be done before the process exits. Any steps contained in the Finally execution block will be executed regardless of whether or not any previous step is executed.
Design Time Properties
| Name | Dynamic | Description |
| Name | User provided name for the Process Step. Will replace default name of Step when placed on the Design Canvas. | |
| Disable | Boolean flag to determine whether the step should be executed at runtime or design time. | |
| Bindings | Launches the Binding Expressions dialog for specifying Environment Variables. NOTE: THERE ARE NO BINDABLE PROPERTIES FOR THIS PROCESS STEP. |
Sample
The sample below demonstrates a common reusable exception pattern. The Validate Customer Purchases Business Process has all its business logic encapsulated within the Exception Process Step (Try block). The Catch block has a single Execute Process Step. This calls the Business Process, Exception_Handler_ReThrow. This Business Process is used to enrich the current exception information, call the Audit Process Step with the Action set to Failed, and then re-throw the exception for the Neuron ESB to capture and process normally.
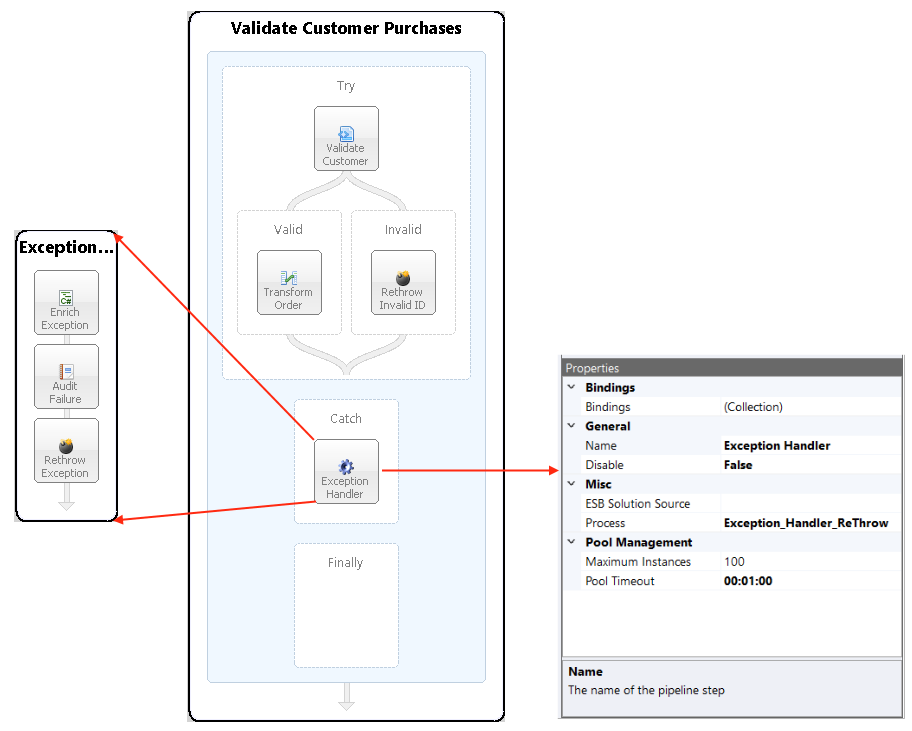
Developers can enrich the current exception information and reset the inner exception so that it will be reported by the Audit Process Step or other parts of the Neuron ESB system or processes. In the sample above, A Business Process named “Validate Customer Purchases” is constructed with a “Validate Customer” Process Step. When that process throws an exception, the current information about what process and step generated the information is retrieved within the “Enrich Exception” C# Process Step located in the “Exception_Handler_ReThrow” sub process. A new business friendly message (accessing the PipelineException is optional) and exception object is composed and created. The “CurrentException” property located in the Properties Collection of the context object is then set with this new object and message. The “CurrentException” property is used internally to reset the current PipelineException object’s inner exception property.
var ex = (PipelineException)context.Properties["PipelineException"];
var errorMessage = String.Format(System.Globalization.CultureInfo.InvariantCulture,
"The order process could not reconcile the customer id " +
"with the customer name.{0}{1}" + "Error Message: {2}{3}Source Process: {4}{5}" +
"Source Process Step: {6}",
Environment.NewLine,
ex.InnerException.Message,
ex.Pipeline,
ex.PipelineStep);
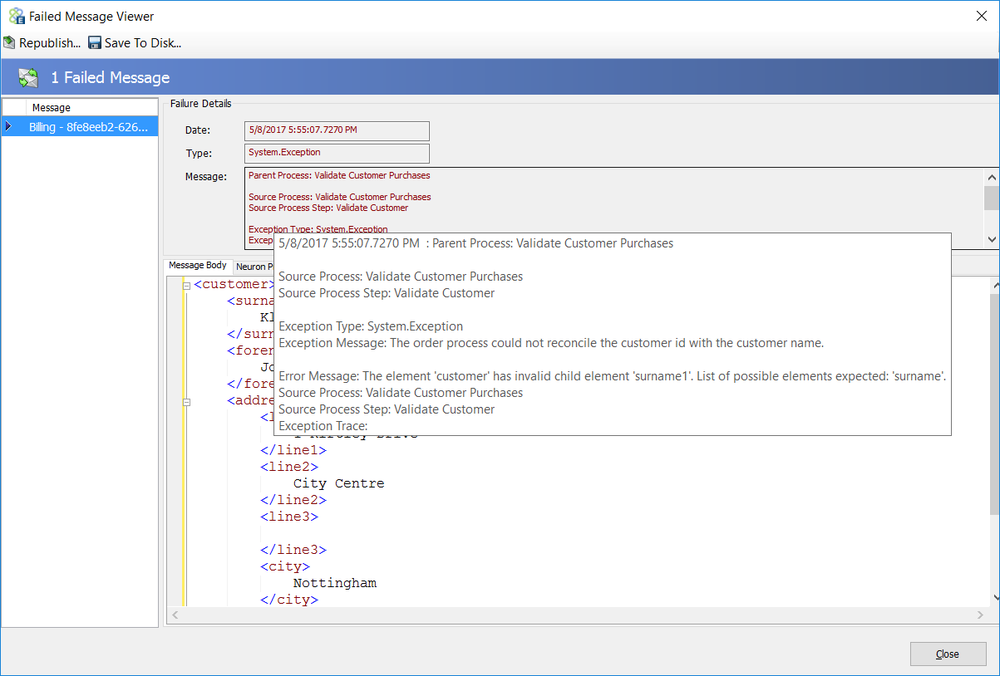
context.Properties["CurrentException"] = new System.Exception(errorMessage);In the example above, the “PipelineException” property is retrieved so that the name of the Business Process and Process Step that generated the exception could be used as part of the new exception message. However, if that information was not needed, the “CurrentException” property could be retrieved instead. When an Audit Process Step that has its Action property set to Failure follows the sample above, the following message will be recorded in the Neuron ESB Failed Messages Report:
Rethrow

| Category: | Error Handling |
| Class: | RethrowPipelineStep |
| Namespace: | Neuron.Pipelines |
| Assembly: | Neuron.Pipelines.dll |
Description:
The Rethrow Process Step can be placed within the Catch Execution Block of the Exception Process Step or the Invalid branch of the Validate Schema Pipeline Step. When added to a Business Process the current exception that is generated will be re-thrown and, if not caught in another Exception Process Step, will stop and fault the Business Process execution immediately.
Remarks
Business Processes can be used as the sole business logic for a Neuron ESB hosted service (i.e. Client Connector in Request/Reply mode). To configure this, the Business Process must be attached to the OnPublish event of the Party configured for the Neuron ESB Client Connector. By adding the Cancel Step as the last Process Step to an existing Business Process, Neuron ESB will forward the final processed ESB Message back to the calling client as the Reply message rather than to the Topic specified in the ESB Message Headers Topic property. This will only work if the Business Process is attached to the OnPublish event of the Party. For instance, if the same Business Process was attached to the OnReceive event of the Party, the Cancel Step would silently terminate the Reply message that it was processing and the Neuron ESB Client Connector would return a TimeoutException to the calling client.
If an exception is thrown by this Business Process either because the exception was not caught or was re-thrown by the ReThrow Process Step, that exception will be converted to a message with the Semantic set to Reply. The exception details will become the body of the message and that message will be forwarded to the original caller.
There are Process Steps that, by design, accept messages with the Semantic set to Request. In many cases, if an error is generated during processing, the error is converted to a Reply message and returned to the calling Business Process. Directly after the Process Step, developers can inspect the FaultType property of the ESB Message Header to determine if the message body of the returned Reply message contains the contents of an exception. FaultType can be set to the following enumeration from the Neuron.Esb namespace:
public enum FaultType
{
None,
Communication,
Server,
Exception
}
However, if the message processed has a Semantic of Mulitcast, the exception will not be converted to a Reply message. Instead the error will be thrown back to the Party (and any Endpoint hosting it) executing the Business Process.
Design Time Properties
| Name | Dynamic | Description |
| Name | User provided name for the Process Step. Will replace default name of Step when placed on the Design Canvas. | |
| Disable | Boolean flag to determine whether the step should be executed at runtime or design time. | |
| Bindings | Launches the Binding Expressions dialog for specifying Environment Variables. NOTE: THERE ARE NO BINDABLE PROPERTIES FOR THIS PROCESS STEP. |
Sample
In the Sample below, an incoming message (Semantic == Multicast) is received by the Validate Customer Order Business Process via the OnPublish event of a Party. It uses the Validate Customer (Validate-Schema) Process Step to validate the customer information against an XSD Schema. If valid, control flows to the Valid branch. From there it is forwarded (by the Neuron ESB runtime) to the Topic specified in the ESB Message Headers Topic property. If the message fails validation, it flows to the Invalid branch.
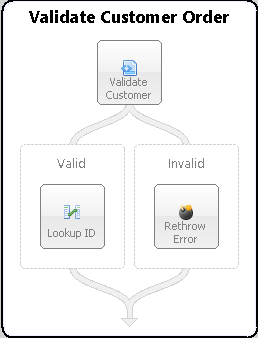
The Invalid branch does not throw an exception. Instead, the Validate-Schema Process Step populates the CurrentException context property with a PipelineException object that contains the original exception generated by the Process Step so its available for developers and the ReThrow Process Step to access:
context.Properties["CurrentException"] = new PipelineException(ex.Message, ex)
{
Pipeline = context.Pipeline.Name,
PipelineStep = this.Name
};
The ReThrow Process will see that the CurrentException property is populated, retrieve the inner exception object and throw that back to the calling party. If this Business Process is executed through the use of a Neuron ESB Test Client submitting an XML message other than the one received, an error message would appear similar to the one below:
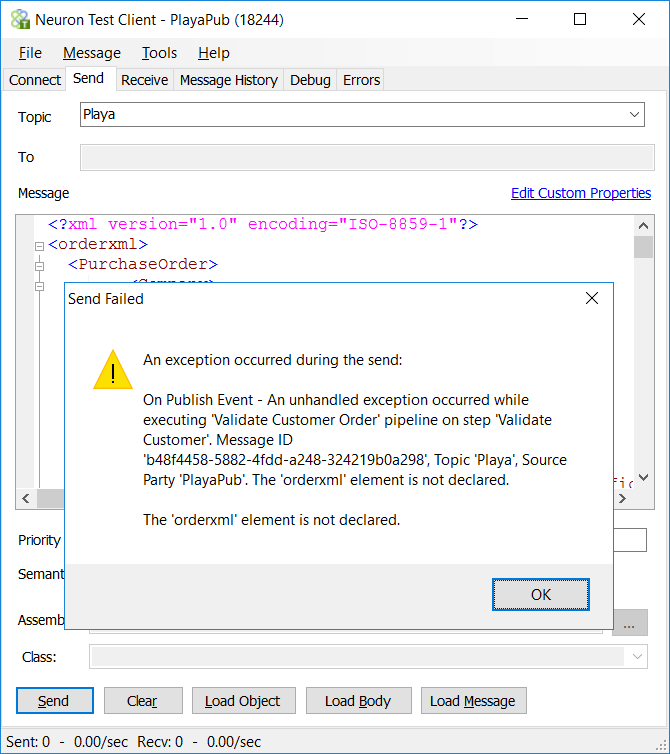
Flow Control
Break

| Category: | Flow Control |
| Class: | BreakPipelineStep |
| Namespace: | Neuron.Pipelines |
| Assembly: | Neuron.Pipelines.dll |
Description:
The Break process step causes a For, For Each or While Process Step (i.e. Loop) to stop, breaking out of their respective execution blocks and, beginning execution at the Process Step immediately following the Loop.
Internally, the Break Process Step throws the BreakLoopException exception, passing the name of the Business Process as well as the name assigned to the Loop Step. The exception does not cause an abnormal abort, nor will it be reported as an error within the system. It is caught internally by the Loop Steps.
Rather than use the Break Process Step, a developer could throw a BreakLoopException in a .NET Language Code Editor enabled Process Step using the syntax below:
throw new BreakLoopException
{
Pipeline = context.Pipeline.Name,
PipelineStep = this.Name
};
The BreakLoopException class definition follows:
public class BreakLoopException : PipelineException
{
public BreakLoopException() { }
public BreakLoopException (string message) :
base(message) { }
public BreakLoopException (string message,
Exception inner) : base(message, inner) { }
protected BreakLoopException (
SerializationInfo info,
StreamingContext context)
: base(info, context) { }
}
Sample
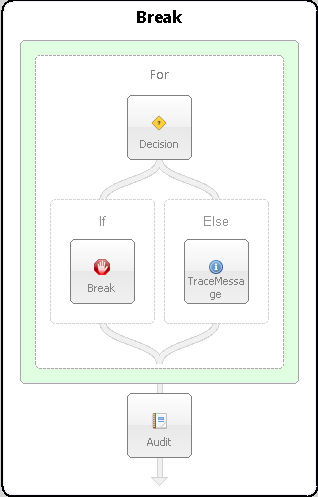
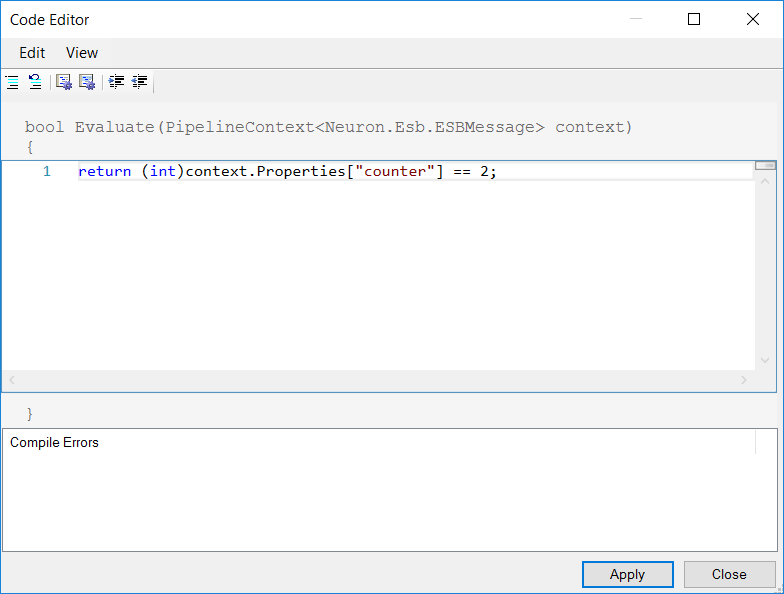
In the Sample below, the steps in the process demonstrate the use of a For Process Step with a Decision Step to determine when the For Loop should break. The For Process Step initializes a counter to zero and increments by one for each iteration. The Decision Step checks the counter, and when it is equal to two the Break Step will execute, and process execution will move to the Audit Process Step.
Cancel
| Category: | Flow Control |
| Class: | CancelPipelineStep |
| Namespace: | Neuron.Pipelines |
| Assembly: | Neuron.Pipelines.dll |
Description:
The Cancel Process Step explicitly ends the execution of a Business Process, terminating the publishing of the message to the Topic specified in the ESB Message Headers Topic property. This is most commonly used to end a branch in a Decision step or it is used to directly follow a Publish step.
Internally, the Cancel Process Step throws the CancelPipelineException exception, passing the name of the Business Process as well as the name assigned to the Cancel step. The exception does not cause an abnormal abort, nor will it be reported as an error within the system.
Rather than use the Cancel Process Step, a developer could throw a CancelPipelineException in a .NET Language Code Editor enabled Process Step using the syntax below:
throw new CancelPipelineException
{
Pipeline = context.Pipeline.Name,
PipelineStep = this.Name
};
The CancelPipelineException class definition follows:
public class CancelPipelineException : PipelineException
{
public CancelPipelineException() { }
public CancelPipelineException(string message) :
base(message) { }
public CancelPipelineException(string message,
Exception inner) : base(message, inner) { }
protected CancelPipelineException(
SerializationInfo info,
StreamingContext context)
: base(info, context) { }
}
Remarks
Business Processes can be used as the sole business logic for a Neuron ESB hosted service (i.e. Client Connector in Request/Reply mode). To configure this, the Business Process must be attached to the OnPublish event of the Party configured for the Neuron ESB Client Connector. By adding the Cancel Step as the last Process Step to an existing Business Process, Neuron ESB will forward the final processed ESB Message back to the calling client as the Reply message rather than to the Topic specified in the ESB Message Headers Topic property. This will only work if the Business Process is attached to the OnPublish event of the Party. For instance, if the same Business Process was attached to the OnReceive event of the Party, the Cancel Step would silently terminate the Reply message that it was processing and the Neuron ESB Client Connector would return a TimeoutException to the calling client.
Design Time Properties
| Name | Dynamic | Description |
| Name | User provided name for the Process Step. Will replace default name of Step when placed on the Design Canvas. | |
| Disable | Boolean flag to determine whether the step should be executed at runtime or design time. | |
| Bindings | Launches the Binding Expressions dialog for specifying Environment Variables. NOTE: THERE ARE NO BINDABLE PROPERTIES FOR THIS PROCESS STEP. |
Sample
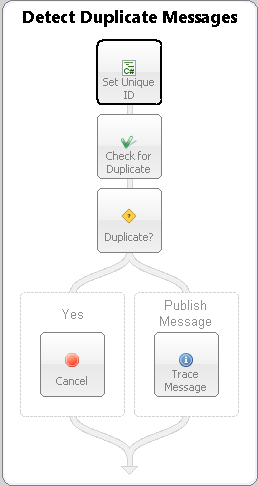
In the Sample below, an incoming message is received by the Detect Duplicate Messages Business Process via the OnPublish event of a Party. Once a unique ID is obtained, the Detect Duplicates Process Step is used to determine is the message was already received. If the message has not previously received, it flows to the Publish Message branch. From there it is forwarded (by the Neuron ESB runtime) to the Topic specified in the ESB Message Headers Topic property. If the message is a duplicate, it flows to the Yes branch. From here, the Business Process is silently terminated using the Cancel step. From this branch, the message is never forwarded to the Topic. This assumes the Business Process below is receiving an ESB Message with a Semantic of Multicast, rather than Request. This would usually be the case when using an Adapter Endpoint in Publish mode.
Decision
| Category: | Flow Control |
| Class: | DecisionPipelineStep |
| Namespace: | Neuron.Pipelines |
| Assembly: | Neuron.Pipelines.dll |
Description:
The Decision Process Step allows users to define branching conditions within a Business Process.Conditions may be expressed in C# using the built in Modal Code Editor.Conditions are evaluated from Left to Right. Once a condition evaluates to true, the execution block within that branch is executed and evaluation of the remaining branches ends. Additional branches can be added to the Decision Step by selecting the Step, right-clicking and select Add branch from the short cut menu. Branches (Execution Blocks) can be removed by right-clicking on the branch and selecting Remove branch from the short cut menu.
Labels for each branch can be changed to a user-defined label by selecting the branchs execution block and changing the Name property within the Process Step Property Page.
Each branch (excluding the default Else branch) has a Condition property that can be accessed within the Property page when the branch is selected. The Condition property exposes an ellipsis button that will launch the Modal Code Editor:
Design Time Properties
| Name | Dynamic | Description |
| Name | User provided name for the Process Step. Will replace default name of Step when placed on the Design Canvas. | |
| Disable | Boolean flag to determine whether the step should be executed at runtime or design time. | |
| Bindings | Launches the Binding Expressions dialog for specifying Environment Variables. NOTE: THERE ARE NO BINDABLE PROPERTIES FOR THIS PROCESS STEP. |
Design Time Properties – Branch
| Name | Dynamic | Description |
| Name | Required. User provided name for the Process Step. Will replace default name of Step when placed on the Design Canvas. | |
| Disable | Boolean flag to determine whether the step should be executed at runtime or design time. | |
| Condition | Required. Launches the Modal Code Editor. Used to return a Boolean value. |
Sample
In the Sample below, the steps in the process demonstrate the use of a For Process Step with a Decision Step to determine when the For Loop should break. The For Process Step initializes a counter to zero and increments by one for each iteration. The Decision Step checks the counter, and when it is equal to two the Break Step will execute, and process execution will move to the Audit Process Step.
Execute Process
| Category: | Flow Control |
| Class: | EsbMessagePipelineExecutionPipelineStep |
| Namespace: | Neuron.Esb.Pipelines |
| Assembly: | Neuron.Esb.dll |
Description:
The Execute Process Step executes another Business Process contained in the same Neuron ESB solution or in an external Neuron ESB Solution. This Step is used to provide the ability to componentize and reuse Business Processes. For example, a Business Process could be created that either standardizes on the way exceptions are processed (as shown in the Exception Process Step Sample) or that provides some other generic functionality or pattern that other Business Processes can encapsulate (dynamic router, validator or transformation).
State
The Execute Process Step has the ability to pass state and environment information back and forth between the calling Business Process (i.e. parent) and the Business Process being called (i.e. child). The Execute Process Step will pass the parents Pipeline context object to the Business Process that it is configured to execute. The Pipeline Context object represents the Business Process instance and is used to access several things at design time and runtime including the existing Neuron ESB Configuration, Environment Variables, Properties, Party, as well as the current message being processed. This means that any context.State, context.Properties information set in the parent Process will be accessible to the child Process. In addition, if information is added or modified to these collections in the child process, that information will be available in the parent process once control returns to the parent Process.
Libraries
In addition to being able to execute local Business Processes, the Execute Process Step can execute Business Processes residing in remote Neuron ESB Solutions. This is useful for creating and maintaining a library of common Business Processes that can be shared across Neuron ESB Solutions. The ESB Solution Source property must be populated with the folder location of the remote Neuron ESB Solution for this feature to be enabled. Once enabled, the Process property will be auto populated with a list of Business Processes located in the remote Neuron ESB Solution. At runtime, all the Business Processes contained within the remote configuration are retrieved and placed in a cache so that they can be executed if selected.
Dynamic Configuration
In some scenarios, developers may need to declare which Business Process to execute at runtime, rather than relying on design time configuration. For example, during the course of execution, the logic in the Business Process could be used to determine the type of order to process. The type of order could then be used to determine which child process to execute. If relying on design time configuration, a Decision Process Step could be used, with each Branch configured to run an Execute Process Step, each configured with a different child process. This will work but would become impractical if it required more than half dozen or so branches. Alternatively, dynamically configuring the Process property at runtime, a Decision Process Step would not be needed. Only one Execute Process Step would be used. Directly preceding the Execute Process Step could be a Set Property Process Step or a Code Step. If a Code Step was used, the following ESB Message Property must be set:
context.Data.SetProperty("neuron", "pipelineName","MyProcess");
The Execute Process Step will look for the neuron.pipelineName ESB Message property (if it exists) and extract its value (i.e. MyProcess) which represents the name of the Business Process to execute. If the ESB Message property does not exist, it will default to the design time configuration of the Execute Process Step to determine the Business Process to load and execute.
The prefix for all Execute Process custom message properties it neuron and they can be accessed directly from the Neuron ESB Message object using the GetProperty() or GetProperties() methods. All Neuron ESB Message properties can also be set using the Set Property Process Step.
| Process Step | Custom Property (i.e. prefix.name) | Design-time Property |
| Execute Process | neuron.pipelineName | Process |
Performance Optimizations
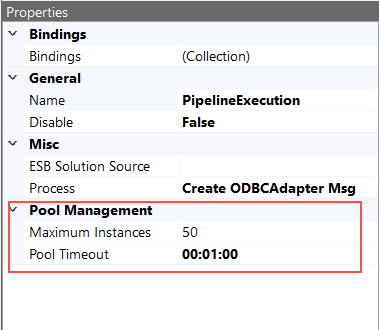
The Execute Process Step uses a Blocking pool of processes to allow better scale out for concurrency and to eliminate all calls being serialized through one instance of a Business Process (child). There are 2 properties located in the Pool Management property category. Maximum Instances (defaults to 100) and Pool Timeout (defaults to 1 minute). Once the maximum number of Business Process instances have been created, the Pool Timeout determines the amount of time to wait for an existing Business Process instance to become available before throwing a timeout exception.
Before a Business Process instance is created, the pool is always checked to see if one already exists. If it does, it retrieves is from the pool and uses it. When complete, the instance is returned to the pool. The Maximum Instances property does NOT define the number of Business Process instances that will always be created at runtime in all circumstances. It only defines the maximum number that could be created. For instance, Business Processes attached to most inbound Adapter Endpoint (Publish mode) will generally only create one pooled instance of a child process as many of the adapters only work with one inbound thread at a time (unless receiving messages from Topics). However, a Client Connector (Neuron ESB hosted service endpoint) could be dealing with many more threads representing concurrent users making service calls.
Additionally, if configured with a remote ESB Solution Source, that source will be retrieved and cached (only the Business Processes it contains) at runtime to avoid unnecessary overhead.
Design Time Properties
| Name | Dynamic | Description |
| Name | User provided name for the Process Step. Will replace default name of Step when placed on the Design Canvas. | |
| Disable | Boolean flag to determine whether the step should be executed at runtime or design time. | |
| Bindings | Launches the Binding Expressions dialog for specifying Environment Variables. | |
| ESB Solution Source | Optional. This launches the select folder dialog. This allows the user to select a remote Neuron ESB Solution to retrieve the list of possible Business Processes to execute at runtime. | |
| Process | Yes | Required. By default, the list of Business Processes to select are auto populated for the Process property from the currently opened Neuron ESB solution. If the ESB Solution Source is populated the list is populated from that solution. NOTE: The Process property can be set at runtime using the Set Property Process Step or Code Step using the following ESB Message Property: Prefix = neuron, Property=pipelineName. |
| Maximum Instances | Required. Defines the maximum of number of Business Process instances that will be created and cached in a concurrent pool. Each thread of execution retrieves a Process instance from the pool. After execution, the Process instance is returned to the pool. If the maximum number of Process instances has already been created, the execution thread will wait for the specified period configured for the Pool Timeout property for another Process instance to become available. Default Value is 100. | |
| Pool Timeout | Required. The period a thread may wait for a Business Process Instance to become available to be retrieved from the pool If the maximum number of pooled instances has already been reached. A timeout exception will be thrown if the Pool Timeout period is exceeded. Default Value is 1 minute. |
Sample
The sample below demonstrates a common reusable exception pattern. The Validate Customer Purchases Business Process has all its business logic encapsulated within the Exception Process Step (Try block). The Catch block has a single Execute Process Step. This calls the Business Process, Exception_Handler_ReThrow. This Business Process is used to enrich the current exception information, call the Audit Process Step with the Action set to Failed, and then re-throw the exception for the Neuron ESB to capture and process normally.
For

| Category: | Flow Control |
| Class: | ForPipelineStep |
| Namespace: | Neuron.Pipelines |
| Assembly: | Neuron.Pipelines.dll |
Description:
A loop is a Process Step, or set of Process Steps, that are repeated for a specified number of times or until some condition is met. Neuron ESB provides several types of loops. The type of loop chosen depends on the task and personal preference.
The For Step provides a looping mechanism for repeating a set of Steps within an Execution Block for a specified number of iterations. It is useful when you know in advance how many times you want the loop to iterate.
The For Step is similar to a C# For loop. It has three main properties that have to be set, the Initializer, Condition and Iterator. All three properties are set by using a C# expression entered in the Modal Code Editor.
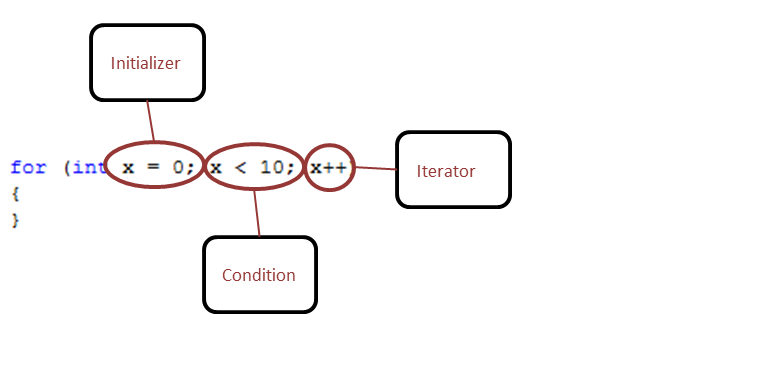
Initializer
The Initializer property is executed first and only once before entering the execution block. The C# expression entered in this property is used to initialize a loop control variable stored in the Properties collection of the context instance. The name of the property is user defined and will be referenced in the Condition and Iterator properties. The expression to initialize a variable can be as simple as the following:
context.Properties["counter"] = 0;
The initializer declares and initializes a local loop variable, counter, that maintains a count of the iterations of the loop.
Condition
Next, theConditionis evaluated. If it is true, the sequence of Process Steps in the execution block of the loop are executed. If it is false, the execution block of the loop does not execute and flow of control jumps to the next Process Step just after the For loop. Like the Initializer, the Condition property is set using a C# expression. For instance, if we wanted the sequence of Process Steps to execute four times, our C# Expression would look like this:
return (int)context.Properties[“counter”] < 4;
Iterator
After the execution block of the For loop executes, the flow of control jumps back up to theIteratorproperty. The Iterator property is used to update any loop control variables (i.e. counter). Like the Condition, the Iterator property is set using a C# expression. In the sample below, the Iterator is incremented by one:
var counter = (int)context.Properties["counter"];
context.Properties["counter"] = counter ++;
The Condition property is now evaluated again. If it is true, the loop executes and the process repeats itself (execution block of loop, then increment step, and then again testing for a condition). After the Condition becomes false, the For loop ends.
Since the Initializer, Condition and Iterator properties are all configured by using the Modal Code Editor, anything can be used to initialize, set the value of, or compare against within the C# expression. For example, other context properties, ESB Message properties, Environment Variables, or content from the ESB Message.
Breaking the Loop
The Break Step provides the ability to stop a loop in the middle of an iteration and continue with the next process step after the loop. During Design Time testing, the Stop Toolbar button is used to stop in the middle of an iteration and abort the rest of the execution of the Business Process.
Design Time Properties
| Name | Dynamic | Description |
| Name | User provided name for the Process Step. Will replace default name of Step when placed on the Design Canvas. | |
| Disable | Boolean flag to determine whether the step should be executed at runtime or design time. | |
| Bindings | Launches the Binding Expressions dialog for specifying Environment Variables. NOTE: THERE ARE NO BINDABLE PROPERTIES FOR THIS PROCESS STEP. | |
| Condition | Required. The condition to evaluate before executing the loop. Launches the Modal Code Editor. Used to return a Boolean value. | |
| Initializer | Required. The condition to evaluate before executing the loop for the first time. Launches the Modal Code Editor. Used to set the loop counter and does not return a value | |
| Iterator | Required. The condition to evaluate after each loop iteration. Launches the Modal Code Editor. Used to increment the counter and does not return a value. |
Sample
In the Sample below, the steps in the process demonstrate the use of a For Process Step with a Decision Step to determine when the For Loop should break. The For Process Step initializes a counter to zero and increments by one for each iteration. The Decision Step checks the counter, and when it is equal to two the Break Step will execute, and process execution will move to the Audit Process Step.
For Each

| Category: | Flow Control |
| Class: | ForEachPipelineStep |
| Namespace: | Neuron.Pipelines |
| Assembly: | Neuron.Pipelines.dll |
Description:
A loop is a Process Step, or set of Process Steps, that are repeated for a specified number of times or until some condition is met. Neuron ESB provides several types of loops. The type of loop chosen depends on the task and personal preference.
The For Each Step provides a looping mechanism for repeating a set of Steps within an Execution Block for each element in an array or a collection of items. When working with collections, you are very likely to be using the For Each Process Step most of the time, mainly because it is simpler than any of the other loop for these kind of operations.
The For Each Step is similar to a C# ForEach loop. It has two main properties that have to be set, the Collection Property Name and the Item Property Name.
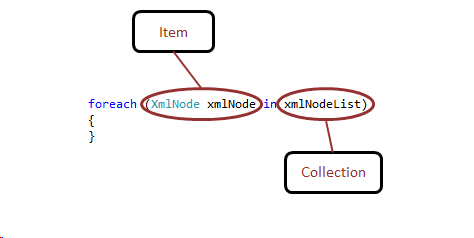
Collection Property Name
The Collection Property Name is the name of the context property that contains the collection that the For Each loop will iterate through. This can be any collection that implements IEnumerable, such as XmlNodeList. This collection must be created in a Code Step preceding the For Each Process Step and saved in a context property of the name that is set in the For Each Process Steps Collection Property Name property. In the sample below, the Neuron ESB Mail API is used to retrieve an email message received by the Neuron ESB Microsoft Exchange Adapter. The email has several file attachments. The collection of attachments are stored in the Properties collection of the context instance using the name set in the property of the For Each Process Step.
var email = Neuron.Esb.Mail.EmailMessage.Deserialize(context.Data.Bytes); context.Properties["EmailAttachments"] = email.Attachments;
Item Property Name
The item Property Name is the name of the context property that the For Each Process Step will create and populate with an individual item from the collection. This property does not need to be created beforehand by the user. The item will be available to be processed by other Process Steps in the execution block of the For Each loop. This property can be accessed in a Code Step inside the execution block of the For Each Step. In the following C# sample, the Attachment property is retrieved, cast into the Neuron ESB Mail Attachment object. The existing ESB Message payload is set with the attachments content and custom message properties are added for future processing.
var att =
(Neuron.Esb.Mail.Attachment)context.Properties["Attachment"];
context.Data = context.Data.Clone(false);
context.Data.Bytes = att.Content;
context.Data.SetProperty("email","ContentType",
att.ContentType);
context.Data.SetProperty("email","Encoding",
att.Encoding);
context.Data.SetProperty("email","Name",
att.Name);
Breaking the Loop
The Break Step provides the ability to stop a loop in the middle of an iteration and continue with the next process step after the loop. During Design Time testing, the Stop Toolbar button is used to stop in the middle of an iteration and abort the rest of the execution of the Business Process.
Design Time Properties
| Name | Dynamic | Description |
| Name | User provided name for the Process Step. Will replace default name of Step when placed on the Design Canvas. | |
| Disable | Boolean flag to determine whether the step should be executed at runtime or design time. | |
| Bindings | Launches the Binding Expressions dialog for specifying Environment Variables. | |
| Collection Property Name | Required. The context property containing the collection the for-each loop will iterate through | |
| Item Property Name | Required. The context property that will be populated by the For Each Process Step on each iteration with the individual element to be processed in the execution block |
Sample
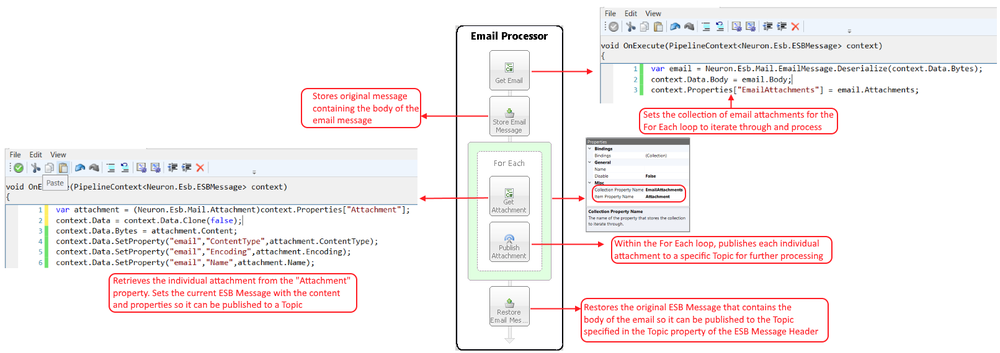
In the figure below, the steps in the process demonstrate the use of a For Each Process Step to publish the file attachments contained within an email message to a specified Topic. After all the attachments are published as individual messages, the original email message body is published to the Topic specified in the ESB Message Headers Topic property. The following describe the process in more detail:
- Get Email C# Process Step – serializes a new Mail object from the inbound ESB Message. This would come from either a POP3 or Microsoft Exchange Adapter Endpoint configured in Publish mode. This Business Process would be attached to the OnPublish event of the Party. The current ESB Message body is reset using the Mail objects Body property. Lastly, the EmailAttachments collection is created and set in the Properties collection of the context instance using the Attachments collection of the Mail object.
- Store Email Message Push Process Step – stores the current ESB Message into a process level cache so that it can be retrieved and restored later in the process
- For Each Process Step This is configured to enumerate through the EmailAttachments collection. Each item in the collection will be placed in Attachment property, created and set in the Properties collection of the context instance.
- Get Attachment C# Process Step – retrieves the next individual Mail Attachment object from the Properties collection. It then resets the ESB Message using the Clone() method so that each message published will have a unique Message ID. The body of the new message is set using the Content property of the message. Additional properties of the Attachment are included as custom ESB Message properties.
- Publish Attachment Publish Step – publishes each Attachment iterated through to a specified Topic
- Restore Email Message Pop Process Step – compliments the previously used Push Process Step. This retrieves the originally message cached by the Push Process Step and restores it so that it will be published to the Topic defined in its Headers Topic property.
Lock

| Category: | Flow Control |
| Class: | LockPipelineStep |
| Namespace: | Neuron.Pipelines |
| Assembly: | Neuron.Esb.dll |
Description:
The Lock Process Step allows a developer to limit access to an execution block of steps to one instance of a process at a time. This is useful if you have one or more steps that should not be executed simultaneously by two or more process instances. For example, if you have an API with low concurrency limits, this would be one way to ensure that you are only making one call at a time:
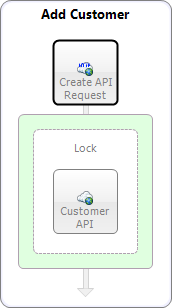
In the above example, only one instance of the Add Customer process will be allowed to call the Service Endpoint step labeled “Customer API”.
Design Time Properties
| Name | Dynamic | Description |
| Name | User provided name for the Process Step. Will replace default name of Step when placed on the Design Canvas. | |
| Disable | Boolean flag to determine whether the step should be executed at runtime or design time. | |
| Bindings | Launches the Binding Expressions dialog for specifying Environment Variables. | |
| LockId | A unique identifier for the lock. When using multiple lock steps in the same process, providing a unique LockId will enforce each lock step independently. If you use the same LockId for two different Lock Process Steps, the same lock will apply in both places. |
Parallel
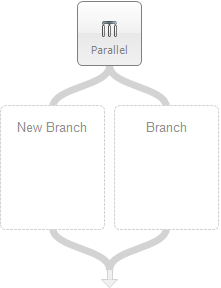
| Category: | Flow Control |
| Class: | EsbMessageParallelStep |
| Namespace: | Neuron.Esb.Pipelines |
| Assembly: | Neuron.Esb.dll |
Description:
The Parallel Process Step allows Process Steps or a sequence of Process Steps to run concurrently within a Business Process. This can be used to control the logical flow of the business process, allowing multiple functionalities to run concurrently, reducing the overall processing time. Service composition/aggregation patterns are a good example where this is often applied. In those scenarios, an incoming request message is submitted to multiple services and the responses need to be aggregated and returned to the calling client.
Process Steps (or a Sequence of Process Steps) are added to an Execution Block of a Parallel Steps Branch. Each Branch has a Condition property that is evaluated at runtime to determine if the Execution Block of the Branch will run. The Condition property can be accessed within the Property page when the branch is selected. The Condition property exposes an ellipsis button that will launch the Modal Code Editor. Conditions may be expressed in C# and must return either True or False.
Additional branches can be added to the Parallel Step by selecting the Step, right-clicking and select Add branch from the short cut menu. Branches (Execution Blocks) can be removed by right-clicking on the branch and selecting Remove branch from the short cut menu.
Labels for each branch can be changed to a user-defined label by selecting the branch’s execution block and changing the Name property within the Process Step Property Page. Branch Labels MUST BE UNIQUE.
Branches
A different thread executes each Branch by default. This requires that each Branch receive not only a copy of the original message, but also a new context instance. This ensures that one Branch’s processing does not affect another Branch’s processing. In short:
- Each Branch gets a copy of the original ESB Message (i.e. context.Data.Clone(false) )
- Each Branch gets a new context instance (i.e. context)
- Each Branch can modify the ESB Message or replace it. (i.e. context.Data)
- Each final Branch’s ESB Message is added to the Messages Property Collection of the context instance.
- The Messages collection can be accessed in Process Steps following the Parallel Process Step i.e. using a C# process step
Within a Branch, developers have access to all the state mechanisms that they would normally have access to in a Business Process (i.e. Properties Collection of the context instance, context.State and ESB Message properties). When working with the Properties Collection, the information added to the collection in Branch can be retrieved in a Code Process step following the Parallel Process Step by preceding the property name with the Branch name. For example, in a C# Process Step in a Branch named Branch1 may have the following code:
context.Properties["myProp"] = "my custom data";
The value of the myProp property could later be retrieved after the Parallel Step completes by preceding the property name with the Branch name i.e.
var propValue = context.Properties["Branch1.myProp"];
Within a Branch, the name of the current Branch can be retrieved by accessing the CurrentBranch property of the Properties Collection using the following syntax:
var myBranchName = context.Properties["CurrentBranch"] as string;
Post Parallel Processing
Control only moves to the Process Step following the Parallel Step once ALL the Branches complete their execution. If an exception is thrown within a Branch, it will abort the execution of all Branches and the Business Process (unless contained within an Exception Process Step). It is recommended that all Process Steps in a Branch’s Execution Block be contained within an Exception Process Step.
After the execution of the Parallel Process Step, all of the ESB Messages and property values set within each Branch can be accessed within any Code Process Step
var messages = (Dictionary<string,
ESBMessage>)context.Properties["Messages"];
foreach(var msg in messages)
{
// print out the messages. Where "msg.Key" is
the name
// of the Branch and "msg.Value = context.Data(), the
// Neuron ESB Message generated by the Branch
context.Instance.TraceInformation(msg.Key + " - "
+ msg.Value.Text);
}
Since all the ESB Messages are contained within a collection, optionally, each ESB Message can be accessed using a For Each Process Step. The following syntax could be used in a Code Process Step within a For Each Process Step:
var message = (KeyValuePair<string,ESBMessage>)context.Properties["Message"]; // print out the messages. Where "message.Key" is the name of // the Branch and "message.Value = context.Data(), the // Neuron ESB Message generated by the Branch context.Instance.TraceInformation(message.Key + " - " + message.Value.Text);
Design Time Properties
| Name | Dynamic | Description |
| Name | User provided name for the Process Step. Will replace default name of Step when placed on the Design Canvas. | |
| Disable | Boolean flag to determine whether the step should be executed at runtime or design time. | |
| Bindings | Launches the Binding Expressions dialog for specifying Environment Variables. | |
| Maximum Concurrent Branches | Required. Default is -1. Determines how many threads will be available to process the branches. -1 value means all branches will be processed by a dedicated thread. If the number is greater than -1 but less than total number of branches, context switching will occur between the number of threads and branches. |
Sample
The figure below depicts the Call Provider Services Business Process that uses the Parallel Step to call two different SOAP based services in parallel. This Process essentially is a re-factorization of the existing Scatter Gather Sample, which is included in the Neuron ESB installation process.
Note:Neuron ESB ships a sample demonstrating the Scatter Gather Pattern. https://www.peregrineconnect.com/neuron/Help3/Development/Samples_and_Walkthroughs/Patterns/web_service_scatter_gather_pattern_using_neuron_pipelines.htm
The original Scatter Gather sample demonstrates retrieving the meta data of N number of services at runtime and using the Split Process Step to call all the services asynchronously, dynamically configuring all the Process Steps involved. It assumes that the information regarding which services to call is ONLY available through a runtime invocation.
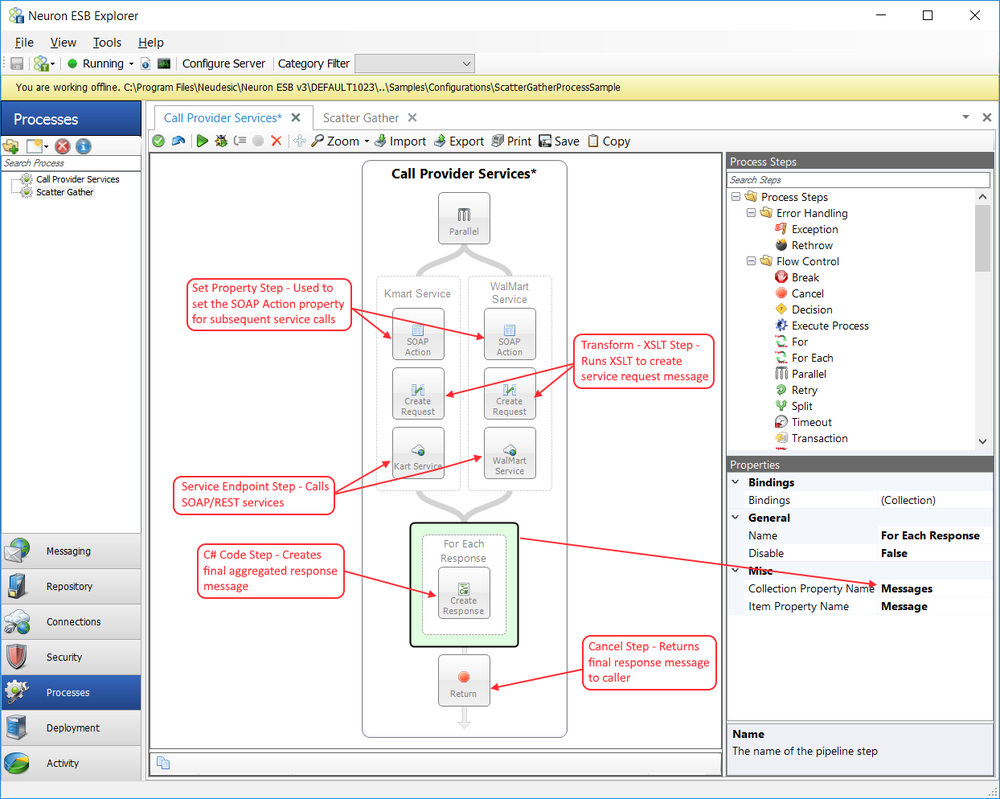
The Call Provider Services Business Process demonstrates an alternative way to accomplish the asynchronous execution of each service, providing that the services to call are known at design time, rather than at runtime. Using the Split Process Step, every message MUST be processed by Steps included in the one Execution Block. Hence, it can be used for dynamic runtime configuration scenarios. In contrast, each Branch in a Parallel Step has its own Execution Block, allowing for a unique set of Process Steps to exist in each Branch.
Each Branch in the Parallel Step represents a service to call (i.e. Kmart and Walmart). The following describes each Branch in more detail:
- SOAP Action Set Property Step Used to set the SOAP Action property of the ESB Message object. Alternatively, the C# Process step could be used to set the SOAP Action. The Set Property Step provides a user interface (Expression Collection Editor) providing a drop down list of all the settable properties.
- Create Request Transform XSLT Step Uses XSLT from the Neuron ESB Repository to transform the incoming message body to the SOAP Request that the target service is expecting.
- X Service Service Endpoint Step Used to call the SOAP Service of the vendor (i.e. Kmart or Walmart). This is set with the name of the preconfigured Neuron ESB Service Connector.
After the Parallel Step has finished, a For Each Process Step iterates through the collection of response messages received by the Branches. Within the For Each Step, several methods could be used to aggregate the response message including using the Transform XSLT Process Step. This sample uses the C# Class Process Step. Following is the contents of that class:
#define DEBUG
#define TRACE
using System;
using System.Collections;
using System.Collections.Generic;
using System.Collections.Specialized;
using System.Data.DataSetExtensions;
using System.Linq;
using System.Xml.Linq;
using System.Xml;
using Neuron.ServiceModel;
using Neuron.Pipelines;
using Neuron.Esb;
using Newtonsoft.Json;
using Newtonsoft.Json.Linq;
namespace Neuron.Esb.Sample.Services
{
public class ResponseFactory :
Neuron.Pipelines.PipelineStep<Neuron.Esb.ESBMessage>
{
// Declared variables
System.Text.StringBuilder sb = new System.Text.StringBuilder();
int totalMessageCount = 0;
int totalMessagesProcessed = 0;
protected override void OnExecute(
PipelineContext<Neuron.Esb.ESBMessage> context)
{
// Get total number of messages in collection to process
if(totalMessageCount == 0)
totalMessageCount = ((Dictionary<string, ESBMessage>)
context.Properties["Messages"]).Count;
// Get a message from the collection
var message = (KeyValuePair<string,ESBMessage>)context.Properties["Message"];
// Write the XML Root element
if(totalMessagesProcessed == 0) sb.AppendLine("<QuoteCollection>");
// Append the current branch message to the new response
message
sb.AppendLine(message.Value.Text);
// Increment the processed counter
totalMessagesProcessed ++;
// Close and finalize Response message. Set response message
// as body of ESB Message. Clean up variables
if(totalMessagesProcessed == totalMessageCount)
{
sb.Append("</QuoteCollection>");
context.Data.Text = sb.ToString();
sb.Clear();
totalMessagesProcessed = 0;
totalMessageCount = 0;
}
}
}
}
The Cancel Process Step placed as the last Step in the process forces the final message to be returned as the Reply message to the original caller.
Retry

| Category: | Flow Control |
| Class: | RetryPipelineStep |
| Namespace: | Neuron.Pipelines |
| Assembly: | Neuron.Pipelines.dll |
Description:
The Retry Process Step can be used to wrap any other Process Step or steps placed within the Execution Block in retry logic. It is most commonly used to help overcome problems such as timeouts and communication exceptions. It can also be used to retry on any exception.
For example, Service and Adapter Policies have Retry semantics built into them to use when Service or Adapter Endpoints receive messages through Topic based subscriptions (i.e. via Messaging). However, these Policies do not apply when Service or Adapter Endpoints are called directly in a Business Process using a Service or Adapter Endpoint Process Step. In those cases, users could implement their own retry policy by using the Retry Process Step
Remarks
If the ErrorType property is set to Communication, both Communication and Timeout exceptions will be caught.
Design Time Properties
| Name | Dynamic | Description |
| Name | User provided name for the Process Step. Will replace default name of Step when placed on the Design Canvas. | |
| Disable | Boolean flag to determine whether the step should be executed at runtime or design time. | |
| Bindings | Launches the Binding Expressions dialog for specifying Environment Variables. | |
| ErrorType | Required. Default is Communication. Presented as a drop down box where Communication or All can be selected. Determines the scope of exception that initiates a retry of all Process Steps within the Retry Execution Block.Timeout exceptions are included if Communication is selected | |
| RetryCount | Required. Default value is 3 retries. The number of attempts that will be made to execute all Process Steps within the Retry Execution Block, if each attempt fails with a qualified exception. Once the number of retries has been exhausted, the exception generated within the Retry Execution Block will be thrown to the underlying Process. | |
| RetryDelay | Required. Default RetryDelay value is 0 seconds. The amount of time (specified in System.TimeSpan) to wait after an exception has occurred before another attempt is made to execute the process steps within the execution block. This forces the executing Thread to sleep for the duration of the RetryDelay interval. | |
| TraceErrors | Required. Default is False. Determines whether failure attempts will write exception information as Trace Error information to the surface of the Design Canvas, Trace Listeners and the Neuron ESB log files at runtime. |
Sample
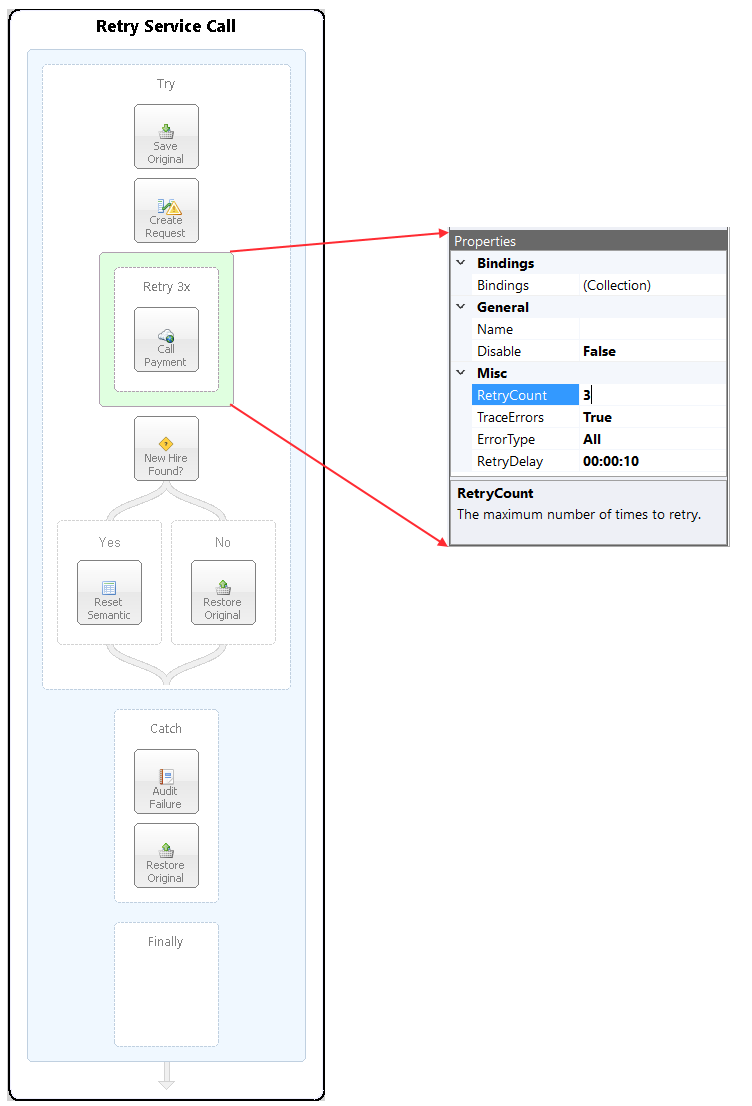
In the Figure below, the Retry Service Call Business Process is used to process an incoming message containing new hire information. It first tries to call a Service Endpoint to retrieve updated information about the new hire. If found, the returned information is published to the HR.Employee Topic for further processing. The Service Endpoint is configured with the Retry Step to attempt 3 retries if the call throws an exception. If the Service Endpoint exhausts its retries, the exception is thrown, caught and audited. Then the original message is retrieved and published to the Topic, HR.Hires. If the updated information is NOT found, the original message is retrieved and published to the HR.Hires Topic as well. The following process in more detail:
- Save Original Push Step Used to save the original Request message. Its inbound Topic set to HR.Hires.
- Create Request Transform XSLT Step Uses XSLT to transform original request message into the SOAP request the Service Endpoint is expecting.
- Call Payment Service Endpoint Step Used to call the SOAP based payment service that queries a back end system to determine if the user information already exists in payroll. This is enclosed in a Retry Process Step configured to retry (three times in 10-second intervals) the service call if any exception occurs.
- New Hire Found Decision Step Used to determine from the response returned by the Call Payment Step if the user already exists in the payroll system.
- Yes
- Reset Semantic Set Property Step Used to set the semantic of the ESB Message to Multicast and the Topic to HR.Employee.
- No
- Restore Original Pop Step Used to discard the response message and restore the original message received by the Process. This will cause the original message to be published to the HR.Hires Topic.
- Catch Block Exception Step
- Audit Failure Audit Step Action set to Failure. Will capture all the details of the exception thrown by the Call Payment Step, logging it as well as the request message sent to the Call Payment Step.
- Restore Original Pop Step Used to discard the response message and restore the original message received by the Process. This will cause the original message to be published to the HR.Hires Topic.
Split

| Category: | Flow Control |
| Class: | XPathEsbMessageSplitter |
| Namespace: | Neuron.Esb.Pipelines |
| Assembly: | Neuron.Esb.dll |
Description:
The Split Process Step (labeled Split and Join) is a composite Process Step that contains a Splitter, Execution Block (labeled Steps) and Aggregator sections. The Split Step can be used to control the flow of the business process by having a specific set of Steps operate on small portions of a larger message, either synchronously or asynchronously. For example, a purchase order published to the bus may contain several individual order line items that must be processed separately. Batch file processing is another common scenario, which requires the ability to split and process the individual parts of the original message as separate distinct messages. Often, these individual messages are sent for processing using a request-reply message exchange pattern. The responses can be collected and joined together for either further processing or as a return message to the original sender.
The Splitter can use an XPath expression or C# code (using the Modal Code Editor) to split the incoming message (Batch) into individual message parts. Each message part is represented as an ESB Message and sent to the Execution Block for continued processing. The Steps within the Execution Block are executed for each individual message split from the Batch. The Aggregator section of the Step can be configured to re-join the individual messages back into a larger Batch message. The Aggregator can enclose the individual messages in an XML tag, use C# code to process them into a larger Batch message or be set to Null and not perform any aggregation, allowing the original incoming Batch message to be forwarded to the next Process Step following the Split Process Step.
Splitter
The Splitter disassembles an incoming message into its constituent messages based on either an XPATH expression or custom C# code. The messages are returned to the Execution Block as a collection of Pipeline Context objects. Each Pipeline Context contains an individual message:
PipelineContext<ESBMessage>
Each individual message in the Pipeline Context is created by cloning the original incoming message and replacing the body with that of the individual message to ensure a Parent/Child relationship between the incoming message and each individual message.
XPATH
The Splitter supports two types of methods for splitting incoming messages: XPATH or Code. Using an XPATH statement to disassemble the incoming message is the default. The split type can be changed through the right click context menu of the Split Step:
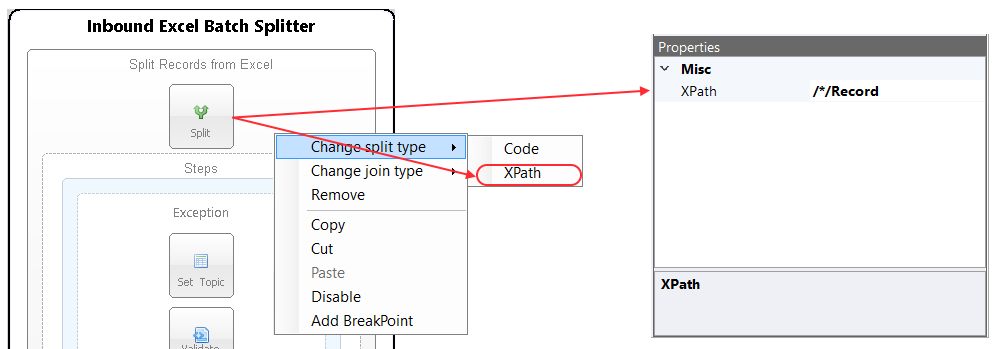
The XPath property becomes visible in the property grid when the XPath split type is selected. The value of the property is used internally to create a set of elements using the System.Xml.Linq.XDocument API, each of which will be converted to an ESB Message as shown in the following pseudo code.
var document = context.Data.ToXDocument();
var nodes = document.XPathSelectElements(XPath);
The XPath value can be standard notation XPATH 1.0. If namespaces exist in the incoming message, then the XPATH statement entered must be qualified.
Once the set of elements has been created, they are looped through, each one creating a new Pipeline Context object with an ESB Message. The collection of Pipeline Context objects are passed to the Execution Block once all the elements have been iterated through.
If the Synchronous property of the Split Step is set to False, then the Parallel.ForEach of the .NET Task Parallel Library will be used to loop through the set of elements, with the degree of Parallelism set to the number of CPU/Cores installed on the machine.
Code
The Code split type for splitting incoming messages is useful when receiving complex XML files where using a simple XPATH cannot be used. It is always used to disassemble NON XML incoming messages. When the Code split type is selected, the Edit Code context menu will become available on the Splitter Step of the Split Step. The Code property also becomes visible, exposing an ellipsis button, both of which will launch the Modal Code Editor:
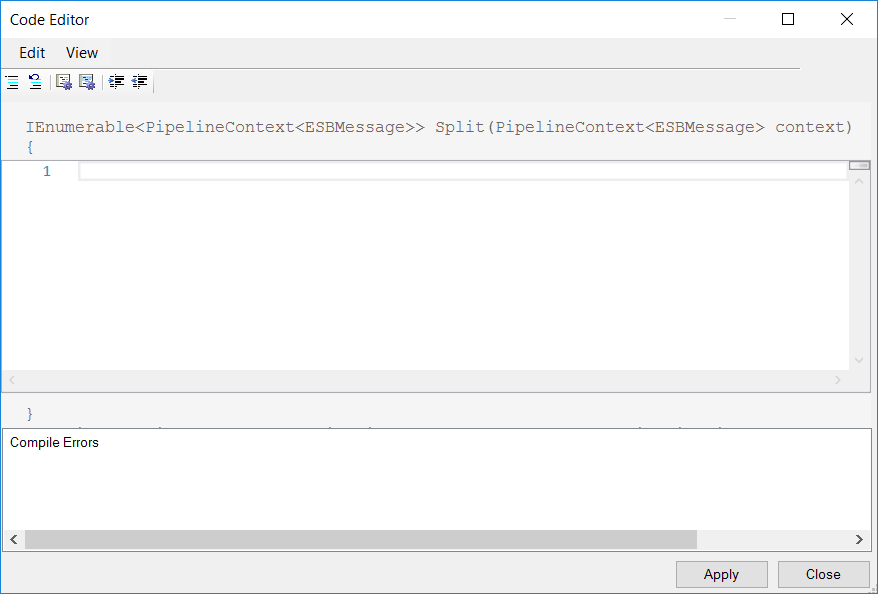
The method template of the Code Editor must return a collection of Pipeline Context objects. The sample below demonstrates using C# to perform a similar batch split that the XPATH option of the Splitter does.
// Get the incoming message as an XmlDocument and run
// an XPATH against it to return the set of nodes
var document = context.Data.ToXmlDocument();
var nodes = document.SelectNodes("Orders/Order");
var list = new List<PipelineContext<ESBMessage>>();
// Loop through all nodes, creating a Pipeline Context
// for each node
foreach(var node in nodes)
{
var clone = context.Data.Clone(false);
clone.Text = node.ToString();
list.Add(this.NewContext(context, clone));
}
// Return the collection to the Execution Block
return list;
Execution Block
Process Steps (or a Sequence of Process Steps) are added to an Execution Block. At runtime, the Execution Block is executed for each message dissembled from the Batch by the Splitter.
If the Synchronous property of the Split Step is False, a different thread executes the Steps enclosed within the Execution Block for each message. This means that each thread will execute its own instance of the Execution Block. The number of instances is determined by the value of the Maximum Thread Count property for the Split Step. This requires that the Execution Block receive not only the individual message, but also a new context instance along with it, similar to the Branches in the Parallel Step. This ensures that one messages processing does not affect another messages processing. In short:
- Execution Block gets an individual message i.e. ESB Message
- Execution Block gets a new context instance (i.e. context)
- Execution Block can modify the ESB Message or replace it. (i.e. context.Data )
Within the Execution Block, developers have access to all the state mechanisms that they would normally have access to in a Business Process (i.e. Properties Collection of the context instance, context.State and ESB Message properties). When working with the Properties Collection, the information added to the collection in an Execution Block cannot be retrieved later in Process Steps that follow the Split Step, or accessed by other messages processed by another instance of the Execution Block.
If the Synchronous property of the Split Step is True, then the Execution Block will run as a For Each Loop on a single thread, only processing the next message once the first message has completed. However, everything else (i.e. each message has its own context instance) remains the same. After the first message completes processing, the next message with a new context instance is processed, and so on.
Once all the messages have been processed by the Execution Block, the results are returned to Aggregator as a collection of context instances along with the original incoming message and its context instance i.e.
IEnumerable<PipelineContext<ESBMessage>>
Aggregator
Once ALL the messages are processed by their respective instance of the Execution Block and its associated process steps, control is passed to the Aggregator portion of the Split process step. Within the Aggregator, the process runtime can either reassemble all the individual Neuron ESB messages, which were processed by the Execution Block back, or discard them. How the Aggregator functions is determined by the value of the “join type” property.
Null
If the join type selected is Null, the Split Process Step will discard the individual messages that were processed and forward the original incoming message to the process step directly following the Split Step.
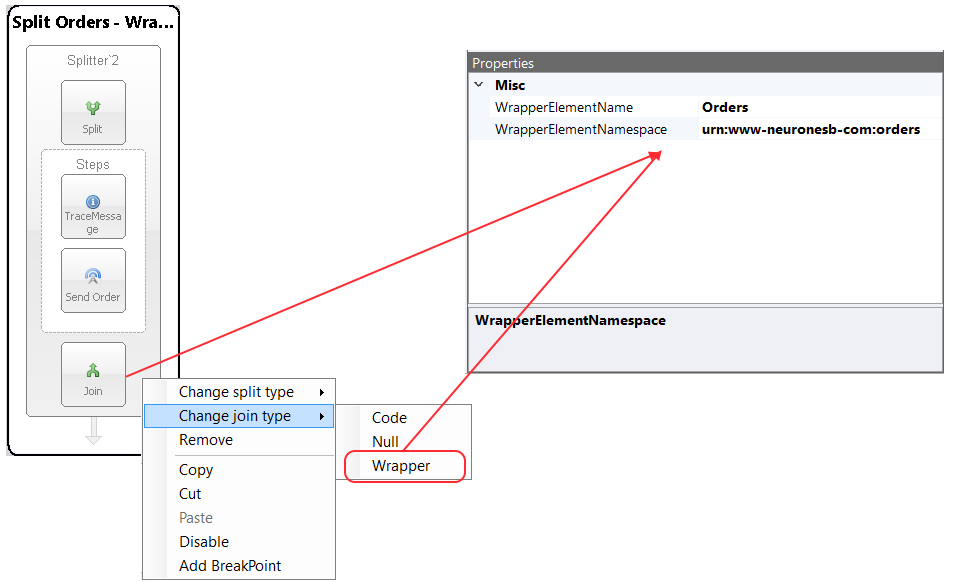
Wrapper
If the join type selected is Wrapper, the Split Process Step will reassemble each message output by the Execution Block. It will use the element tag and namespace specified in the WrapperElementName and WrapperElementNamespace (optional) to construct an XML root node to encapsulate all of the output messages. For example, if the following property values were used:
WrapperElementName = Orders
WrapperElementNamespace =urn:www-neuronesb-com:orders
The result that the Join would produce from the original message follows, providing each output message had an OrderResult XML root node:
<Orders xmlns="urn:www-neuronesb-com:orders"> <OrderResult></OrderResult> <OrderResult></OrderResult> </Orders>
This message will be forwarded to the next Process Step that follows the Split Step.
Code
When using the Code join type, the original context instance (which contains the original unaltered incoming message i.e. Neuron.Esb.ESBMessage) as well the collection of messages and context objects processed by the Execution Block, are passed into the Code Editor as arguments represented by the variables “context” and “splits”.
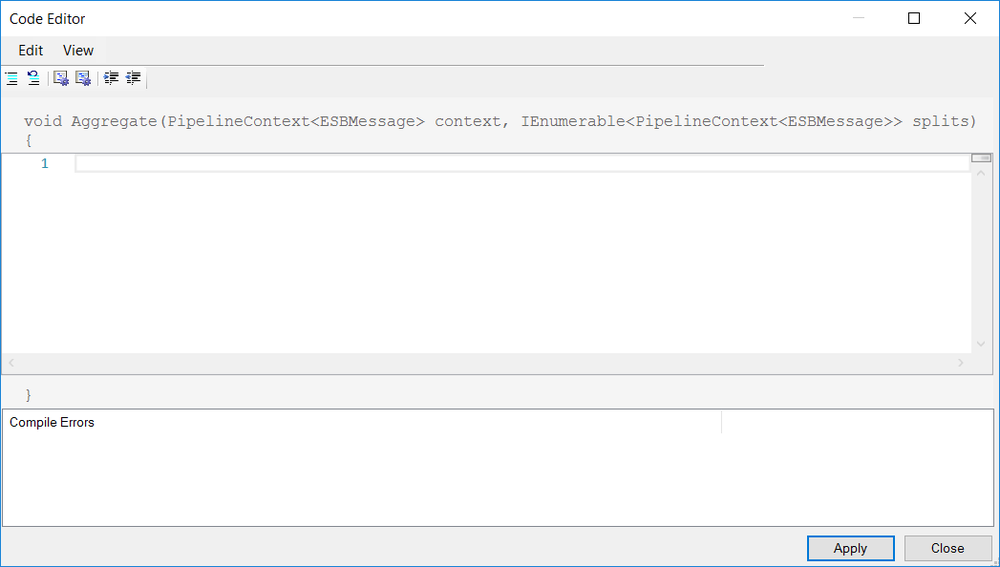
As shown in the following code fragments, entirely custom xml can be created to aggregate the messages collected from the Execution Block by iterating through the splits collection using a For Each loop.
Using StringBuilder:
var sb = new System.Text.StringBuilder();
// Add the Root element
sb.AppendLine("<Orders>");
// Add all child messages to root element
foreach (var ctx in splits)
sb.AppendLine(ctx.Data.Text);
// Close the root
sb.Append("</Orders>");
//Replace original request message with new aggregated
//message. ensure new message retains a Parent/child
//relationship
context.Data = context.Data.Clone(false);
context.Data.FromXml(sb.ToString());
Using an XmlTextWriter:
using (System.IO.StringWriter sw = new
System.IO.StringWriter())
{
using(XmlTextWriter xw = new XmlTextWriter(sw))
{
//writes <Orders> root element
xw.WriteStartElement("Orders");
foreach(var c in splits)
{
//adds <OrderResult>...</OrderResult>
xw.WriteRaw(c.Data.ToXml());
}
//writes </Orders>
xw.WriteEndElement();
xw.Flush();
}
//Replace original request message with new aggregated
//message. ensure new message retains a Parent/child
//relationship
context.Data = context.Data.Clone(false);
context.Data.FromXml(sw.ToString());
}
As indicated in the code fragments above, to return the newly created aggregated message to the remaining steps of the process, the body of Neuron.Esb.ESBMessage assigned to the current context (represented by the context.Data variable) must be replaced with a new aggregated message body.
Remarks
If the Synchronous property is set to True, the Split Step becomes ideal for scenarios where an XPATH statement is used to dissemble an incoming message. The Split Step provides a simple, no code solution for both disassembling the incoming message and aggregating the results. With Synchronous set to True, the disassembling and processing through the Execution Block are essentially two back-to-back For Each Loops. Therefore, if more complex criteria is required to disassemble an incoming message, requiring the split type to be set to Code, users should consider using the For Each Process Step instead, unless there is a requirement for each message to be processed with its own pipeline context object. That is because after the Splitter creates the raw collection of data items, it then has to loop through each data item, converting each into a Neuron.Esb.EsbMessage within a new context instance. In contrast, a For Each Process Step can iterate through the raw collection of data items, as long as there was not a need to have a unique context instance in each loop iteration. This would eliminate the second step of the Splitter i.e. creating the collection of context instances.
However, if concurrent processing (Synchronous set to False) of the dissembled individual messages is required, then the Split Step should always be used. The more complex processing required in the Execution Block (i.e. more Process Steps), the more beneficial the concurrent processing becomes to enhance overall performance. Testing must be done to determine the ideal number of threads to assign to the Maximum Thread Count property. Users should start with the number of threads equaling the number of CPU/Cores installed and then gradually increase.
Additionally, the larger the incoming batch message (number of rows in the message and size of rows), the more time it will take for the Splitter to compose the final collection of context instances to pass to the Execution Block. This needs to be weighed against the time for total execution.
Design Time Properties – Split
| Name | Dynamic | Description |
| Name | User provided name for the Process Step. Will replace default name of Step when placed on the Design Canvas. | |
| Disable | Boolean flag to determine whether the step should be executed at runtime or design time. | |
| Bindings | Launches the Binding Expressions dialog for specifying Environment Variables. | |
| Synchronous | Required. Default is True. Determines whether all the process steps enclosed in the Execution Block will run synchronously or asynchronously. If False, the Split Step will use the TPL Parallel.ForEach to create the collection of context instances to pass to the Execution Block. In addition, the Maximum Thread Count property is used to determine how many instances of the Execution Block should be created. Each Thread is used to process a message from the collection concurrently. If Synchronous is set to True, both the creation of the collection and processing of the collection functions as a standard synchronous For Each loop. | |
| Maximum Thread Count | Required. Default is 10. ONLY used if Synchronous is set to False. Determines size of .NET Thread pool to use to create instances of the Execution Block so that messages may be processed by it concurrently. |
Design Time Properties – Splitter – XPath
| Name | Dynamic | Description |
| XPath | When split type is set to XPath:An XPath expression used to split the message into individual child messages. |
Design Time Properties – Splitter – Code
| Name | Dynamic | Description |
| Code | When split type is set to Code:Defines the C# code that will be used to split the message into individual child messages. An ellipsis button is presented which opens the Modal Code editor. |
Design Time Properties – Aggregator – Wrapper
| Name | Dynamic | Description |
| WrapperElementName | When join type is set to Wrapper:The XML element name used to enclose all the child messages into one message. | |
| WrapperElementNamespace | When join type is set to Wrapper:The XML namespace to use for the wrapper tag. Uniform Resource Locators (URL) or Uniform Resource Names (URN) can be used. Optional. |
Design Time Properties – Aggregator – Code
| Name | Dynamic | Description |
| Code | When join type is set to Code:Defines the C# code that will be used to aggregate all child messages into one message. An ellipsis button is presented which opens the Modal Code editor. |
Sample
Splitting Message with Null Join
Implementing the Scatter Gather ESB Pattern with Neuron Processes
Timeout

| Category: | Flow Control |
| Class: | ContainerPipelineStep |
| Namespace: | Neuron.Pipelines |
| Assembly: | Neuron.Pipelines.dll |
Description:
The Timeout Process Step executes the contained Process Steps on a background thread. To succeed, the contained Process Steps needs to complete successfully before the timeout period expires, otherwise a timeout exception will be raised to the Business Process.
For example, if the Timeout Process Step is configured for 5 seconds, the contained steps must complete their execution before the 5 seconds expires, otherwise a timeout exception will be thrown to the underlying Business Process. Even though the contained Process Steps are executed on a background thread, the Timeout process step executes synchronously. The Business Process will not continue until either the contained Process Steps complete or a timeout occurs.
The Timeout Process Step is compatible with the use of atomic transactions such as transactional MSMQ topics. If a transaction is active when the Business Process runs, the contained Process Steps will execute within the context of the transaction that the Business Process is participating. Failure of the contained Process Steps will cause the transaction to roll back and the message will be returned to the partys message queue.
Although this cannot generally be used to abort a poorly constructed looping scenario, a cancellation token has been built into the context object, which can trigger the termination of the processing occurring in the background thread. This will only happen between Process Steps. For example, the Timeout Process Step would not terminate the following constructed loop if used in a C# Code Process Step:
while (true)
{
// Do something here
System.Threading.Thread.Sleep(1000);
}
However, if the loop were reconstructed to use the Cancellation Token, the loop (and the background processing thread) will be terminated directly by the Timeout Process Step by using the IsCancellationRequested property of the CancellationToken object of the context object.
while (!context.CancellationToken.IsCancellationRequested)
{
// Do something here
System.Threading.Thread.Sleep(1000);
}
Design Time Properties
| Name | Dynamic | Description |
| Name | User provided name for the Process Step. Will replace default name of Step when placed on the Design Canvas. | |
| Disable | Boolean flag to determine whether the step should be executed at runtime or design time. | |
| Bindings | Launches the Binding Expressions dialog for specifying Environment Variables. | |
| Timeout | Required. Must be a value greater than zero. The number of seconds to wait for all the Process Steps to finish execution. If the Timeout value is exceeded, a TimeoutExeception is thrown. |
Sample
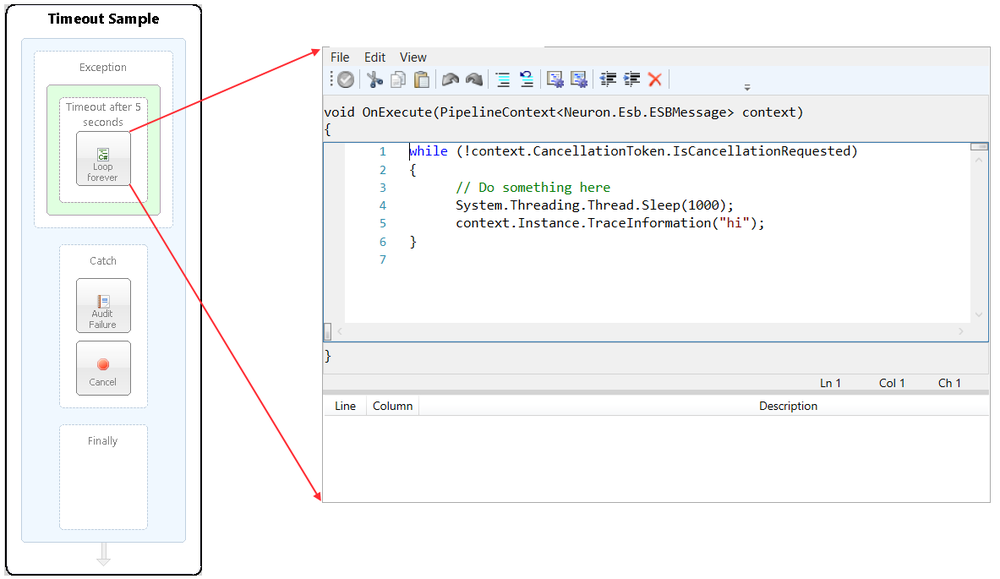
In the Sample below, the Timeout Process Steps Timeout value is set to five seconds. Within the Execution Block, there is a C# Code Step configured to write out to the Trace Window every second in a While loop. The While loop uses the IsCancellationRequested property of the context instance to determine if the Timeout has been exceeded and when to break out of the loop.
Once the Timeout has exceeded, a TimeoutException is thrown and caught in the Exception Steps Catch block. The message is audited and the Business Process is terminated using the Cancel Step.
Transaction

| Category: | Flow Control |
| Class: | TransactionPipelineStep |
| Namespace: | Neuron.Pipelines |
| Assembly: | Neuron.Pipelines.dll |
Description:
The Transaction Process Step can be used to enclose other Process Steps (that support atomic Transactions or an XA resource compliant Transaction Manager) inside a transaction scope by placing them within the Transaction Execution Block. This step uses System.Transactions from the .NET namespace and will always create a new Transaction for the enclosed Process Steps.
If the Transaction exceeds the configured Timeout property, an exception will be thrown to the underlying Business Process.
Design Time Properties
| Name | Dynamic | Description |
| Name | User provided name for the Process Step. Will replace default name of Step when placed on the Design Canvas. | |
| Disable | Boolean flag to determine whether the step should be executed at runtime or design time. NOTE: Also available from the right-click context menu. | |
| Bindings | Launches the Binding Expressions dialog for specifying Environment Variables. | |
| Timeout | Required. The transaction timeout. The value is expressed in hours, minutes, seconds as hh:mm:ss. Default value is 1 minute. | |
| Level | Required. The isolation level of the transaction. A dropdown is presented with the following options: Serializable RepeatableRead ReadCommitted ReadUncommitted Snapshot Chaos Unspecified The isolation level of a transaction determines what level of access other transactions have to volatile data before a transaction completes. Default value is Serializable. |
While

| Category: | Flow Control |
| Class: | WhilePipelineStep |
| Namespace: | Neuron.Pipelines |
| Assembly: | Neuron.Pipelines.dll |
Description:
A loop is a Process Step, or set of Process Steps, that are repeated for a specified number of times or until some condition is met. Neuron ESB provides several types of loops. The type of loop chosen depends on the task and personal preference.
The While Step provides a looping mechanism for repeating a set of Steps within an Execution Block. The loop continues until its Condition property evaluates to False. The Condition property is evaluated each time the loop is encountered. If the evaluation result is true, the Process Steps within the Execution Block are executed.
Here, the key point of thewhileloop is that the Execution Block may never run. When the Condition is tested and the result is False, the Execution Block is skipped and the first Process Step after the while loop is executed.
An infinite while loop can be implemented by ensuring that the Condition property of the While Step always returns true, similar to the C# code fragment below:
while (true){
// statements
}
In contrast to using the For Each or For Process Steps, it up to the developer to set the condition to exit the loop within the While Steps Execution Block. The While Process Step is similar to a C# While loop. It has one property that has to be set, the Condition. The property is set by using a C# expression entered in the Modal Code Editor.
Condition
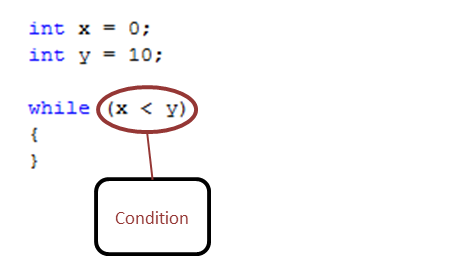
TheConditionis evaluated before the execution of the Execution Block. If it is true, the sequence of Process Steps in the execution block of the loop are executed. If it is false, the execution block of the loop does not execute and flow of control jumps to the next Process Step just after the While loop. The Condition property is set using a C# expression that must return either True or False. For instance, if we wanted the sequence of Process Steps to execute four times, our C# Expression would look like this:
return (int)context.Properties["counter"] < 4;
However, unlike the For Process Step, there is no Iterator property to increment the counter. Using the While Step, the counter variable would have to be incremented by the user within the Execution Block:
var counter = (int)context.Properties["counter"]; context.Properties["counter"] = counter ++;
Since the Condition property is configured by using the Modal Code Editor, anything can be used to initialize, set the value of, or compare against within the C# expression. For example, other context properties, ESB Message properties, Environment Variables, or content from the ESB Message.
Breaking the Loop
The Break Step provides the ability to stop a loop in the middle of an iteration and continue with the next process step after the loop. During Design Time testing, the Stop Toolbar button is used to stop in the middle of an iteration and abort the rest of the execution of the Business Process.
Design Time Properties
| Name | Dynamic | Description |
| Name | User provided name for the Process Step. Will replace default name of Step when placed on the Design Canvas. | |
| Disable | Boolean flag to determine whether the step should be executed at runtime or design time. | |
| Bindings | Launches the Binding Expressions dialog for specifying Environment Variables. NOTE: THERE ARE NO BINDABLE PROPERTIES FOR THIS PROCESS STEP. | |
| Condition | Required. The condition to evaluate before executing the loop. Launches the Modal Code Editor. Used to return a Boolean value. |
Sample
In the Sample below, the steps in the process demonstrate the use of a While Process Step to continually query an external expense reporting system for current expenses of all users. The While Process Steps Condition is set to execute an infinite loop (i.e. return true). The query only returns for a specific user. Only when there are no longer expense records returned (Decision Process Step), will the While loop break and move control to the For Each Process Step. The For Each Process Step is used to aggregate the individual expense records that are returned within the While Step, creating a batch message, which eventually is submitted to a Payroll system.
The following process in more detail:
- Initialize Expenses C# Code Step Used to create the Expenses collection to save returned expense records.
context.Properties[“Expenses”] = new List<string>();
- While Process Step Configured as an infinite loop i.e. Condition property returns true;
- Save Original Push Step Saves original request message so that it can be used to make subsequent requests to the Expense System.
- Query Expense Service Endpoint Step Used to call the SOAP or REST based expense service that queries a back end system for expense records of a user.
- Record Returned? Decision Step Used to determine if expense records were returned from querying the Expense System.
- Yes
- Add Message C# Code Step Adds returned expense record to the Expenses collection and sets the next line number query key to use for the subsequent query.
- Retrieve Original Pop Step Restores the original request message to use for Query
- Set Next Key C# Code Step Updates the restored original request message with the next expense record key to retrieve.
- No
- No More Records Break Step Used to break out of the While loop and move control the following For Each Process Step.
- Loop thru Expenses For Each Step Configured to loop through the Expenses collection
- Create Batch C# Class Step Aggregates all the records in the Expense collection into a single batch message to submit to Payroll.
Initialize Expenses C# Code Step – pseudo code listing:
context.Properties["Expenses"] = new List<string>();
Add Message C# Code Step – pseudo code listing:
//Retrieve the collection of expenses. Add the new expense
//response from the expense system and update the collection
var expenses = (List)context.Properties["Expenses"];
expenses.Add(context.Data.Text);
context.Properties["Expenses"] = expenses;
//Retrieve key to use to query next set of records
var doc = context.Data.ToXmlDocument();
var queryKey = doc.SelectSingleNode("/*/Expense/NextLineNo").InnerText;
context.Properties["QueryKey"] = int.Parse(queryKey);
Set Next Key C# Code Step – pseudo code listing:
//Retrieve the previously saved query key
var queryKey = (int)context.Properties["QueryKey"];
//Update the original request message with the key
var doc = context.Data.ToXmlDocument();
var queryKeyNode = doc.SelectSingleNode("/Request/Expense/LineNo");
queryKeyNode.InnerText = queryKey.ToString();
context.Data.FromXml(doc.InnerXml);
Create Batch C# Class Code Step – pseudo code listing:
#define DEBUG
#define TRACE
using System;
using System.Collections;
using System.Collections.Generic;
using System.Collections.Specialized;
using System.Data.DataSetExtensions;
using System.Linq;
using System.Xml.Linq;
using System.Xml;
using Neuron.ServiceModel;
using Neuron.Pipelines;
using Neuron.Esb;
using Newtonsoft.Json;
using Newtonsoft.Json.Linq;
namespace Neuron.Esb.Sample.Services
{
public class PayrollFactory
:Neuron.Pipelines.PipelineStep
{
// Declared variables
System.Text.StringBuilder sb = new System.Text.StringBuilder();
int totalMessageCount = 0;
int totalMessagesProcessed = 0;
protected override void OnExecute(
PipelineContext context)
{
// Get total number of expenses in collection to process
if (totalMessageCount == 0)
totalMessageCount = ((List)
context.Properties["Expenses"]).Count;
// Get a expense from the collection
var message = (string)context.Properties["Expense"];
// Write the XML Root element
if (totalMessagesProcessed == 0)
sb.AppendLine("");
// Append the current expense to the batch
sb.AppendLine(message);
// Increment the processed counter
totalMessagesProcessed++;
// Close and finalize Payroll batch message. Set it
// as the body of ESB Message. Clean up variables
if (totalMessagesProcessed == totalMessageCount)
{
sb.Append(" ");
context.Data.Text = sb.ToString();
sb.Clear();
totalMessagesProcessed = 0;
totalMessageCount = 0;
}
}
}
}
JSON
JSON
| Category: | Languages |
| Class: | JsonXmlProcessStep |
| Namespace: | Neuron.Esb.Pipelines |
| Assembly: | Neuron.Esb.Pipelines.dll This step is moved to JSON Folder in the Process Steps Toolbox. |
Description:
The JSON Process Step is used to translate .NET Class instances and XML documents to JSON and back again. The Process Step uses the Newtonsoft JSON library (JSON.NET) to handle serialization to JSON and deserialization from JSON. The “Convert To” design time property determines the translation mode of the Process Step. There are three options available to users:
| Convert To | Description |
| JSON | Supports translating XML or .NET Class instances (Xml Serializable or DataContract Serializable) to JSON. |
| XML | Supports translating JSON or .NET Class instances (Xml Serializable or DataContract Serializable) to XML. |
| Class | Supports translating JSON or XML to a .NET Class Instance. |
The Process Step provides a number of features that controls the format of the JSON, including:
- Using Newtonsoft JSON directives (represented by the https://james.newtonking.com/projects/json namespace) to decorate .NET Classes or XML documents
- Null Value handling options
- Custom DateTime formatting
- Excluding XML Root Node and Namespaces
- Providing a .NET Class reference to use for serialization
Convert to JSON
The primary use of the JSON Process Step is to convert either .NET Serializable Class instances or XML documents to properly formatted JSON documents. In either case, the JSON Process Step provides a number of features that can be used to determine the format of the JSON produced. Once the JSON message has been serialized into the Neuron ESB Message, the HTTP.ContentType of the Neuron ESB Message object will be set to “application/json”.
Using Newtonsoft Directives:
For example, the following incoming XML document uses the json:Array attribute from JSON.NET to direct the Process Step to produce JSON in the expected Array format:
<contractLines json:Array="true" xmlns:json="https://james.newtonking.com/projects/json"> <lineId>38939e01-cb69-4d0d-8747-164e33a35aec</lineId> <lineId>37839d01-rt56-4d0d-8747-164e33a15aec</lineId> <lineId>34639f01-kj98-4d0d-8747-164e33a25aec</lineId> </contractLines>
The output of the Process Step with the Array attribute is shown below:
{
"contractLines": [
{
"lineId": [
"38939e01-cb69-4d0d-8747-164e33a35aec",
"37839d01-rt56-4d0d-8747-164e33a15aec",
"34639f01-kj98-4d0d-8747-164e33a25aec"
]
}
]
}
However, if the Array attribute is removed from the incoming XML document, the output is no longer serialized into a JSON array structure:
{
"contractLines": {
"lineId": [
"38939e01-cb69-4d0d-8747-164e33a35aec",
"37839d01-rt56-4d0d-8747-164e33a15aec",
"34639f01-kj98-4d0d-8747-164e33a25aec"
]
}
}
Excluding Xml Root:
Another feature is the handling of root nodes in XML documents. In almost all cases, XML documents require an enclosing root node, whereas JSON documents do not. In fact, many web frameworks using JSON do not use a root node, just the core object. Hence, an XML document like the following:
<company>
<name>ABC TEST LTD</name>
<extref>10050023871</extref>
</company>
Will translate to the following JSON:
{
"company": {
"name": "ABC TEST LTD",
"extref": "10050023871"
}
}
However, if the “Exclude Xml Root” property is set to True, the following JSON would be produced:
{
"name": "ABC TEST LTD",
"extref": "10050023871"
}
Removing Xml Namespaces:
In addition to root node removal, either most web frameworks cannot work with XML Namespaces or the inclusion can cause processing issues. Namespaces can appear anywhere within an XML Document. In most cases, developers will usually manually remove them. The sample below depicts a typical XML document with Namespaces
<ProcessPayment xmlns="https://tempuri.org/"> <request xmlns:d4p1="https://schemas.datacontract.org/2004/07/PaymentService" xmlns:i="https://www.w3.org/2001/XMLSchema-instance"> <d4p1:PaymentProcessRequest> <d4p1:Amount>5</d4p1:Amount> <d4p1:OrderId>9e98d6fb-d1be-40f6-abf7- 6a0417d7e449</d4p1:OrderId> </d4p1:PaymentProcessRequest> </request> </ProcessPayment>
The default translation settings of the JSON Process Step would produce the following JSON output.
{
"ProcessPayment": {
"@xmlns": "https://tempuri.org/",
"request": {
"@xmlns:d4p1":
"https://schemas.datacontract.org/2004/07/PaymentService",
"@xmlns:i": "https://www.w3.org/2001/XMLSchema-instance",
"d4p1:PaymentProcessRequest": {
"d4p1:Amount": "5",
"d4p1:OrderId": "9e98d6fb-d1be-40f6-abf7-6a0417d7e449"
}
}
}
}
However, using the Exclude Xml Root and Remove Xml Namespaces properties, the following JSON would be produced instead:
{
"request": {
"PaymentProcessRequest": {
"Amount": "5",
"OrderId": "9e98d6fb-d1be-40f6-abf7-6a0417d7e449"
}
}
}
Null Value Handling:
In addition, how empty or null values are translated can also be problematic for web developers. For example, the following XML Document has an empty element, as well as an element that is defined as null (i.e. xsi:nil=”true”):
Default settings of the JSON Process Step would in turn produce the following JSON:

However, users can choose to serialize empty or null values with either an empty string or a NULL value by selecting the option using the “Null Value Handling” property. For example, choosing the EmptyString option of the property, the following JSON would be produced instead:

Strongly Typing JSON:
As can be seen in all of the JSON previous sample outputs in this section, all JSON values are enclosed with double quotes, denoting a string data type, even though some of the values within the XML document may be numbers or Booleans values. This is because JSON and XML are different serialization formats. For instance, XML does not have a way to differentiate primitive types. Whereas JSON can differentiate between string, number, and boolean Therefore, when converting from JSON to XML and back, the type information gets lost. One way to handle this is to use a strongly typed intermediate .NET Class when converting back and forth. In other words, instead of converting directly from XML to JSON, deserialize the XML to the .NET Class then serialize the .NET Class to JSON. The .NET Class will force the data to be the correct types.
The JSON Process Step provides the Class Type property to do exactly that. By referencing a .NET Class that represents the XML, the JSON Process Step can produce JSON with the intended data types. For example, the XML sample below can be submitted without a .NET Class instance selected:
<?xml version="1.0"?> <Customer xmlns:xsd="https://www.w3.org/2001/XMLSchema" xmlns:xsi="https://www.w3.org/2001/XMLSchema-instance"> <ID>5</ID> <Name>Marty</Name> <Email>marty.wasz@neudesic.com</Email> <ConfirmDate>2017-06-02T08:11:21.2618385-07:00</ConfirmDate> </Customer>
The JSON Process Step would produce the following JSON. Even though the ID node value is a number, it is still enclosed with double quotes:
{
"ID": "5",
"Name": "Marty",
"Email": "marty.wasz@neudesic.com",
"ConfirmDate": "2017-06-02T08:11:21.2618385-07:00"
}
However, clicking on the ellipsis button of the Class Type property will display the following .NET Assembly picker dialog. Like all .NET Assemblies used by Neuron ESB at runtime, the assembly must be either in the Neuron ESB instance directory, GAC or the Probe Path defined in the esbservice.exe.config file.
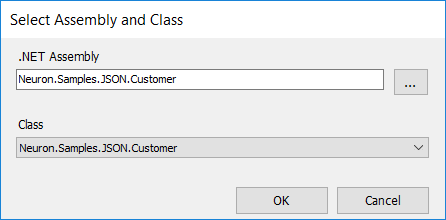
Below is the .NET C# Class that was selected in the dialog
using System;
namespace Neuron.Samples.JSON
{
public class Customer
{
public int ID;
public string Name;
public string Email;
public DateTime ConfirmDate;
}
}
Once the .NET Class has been selected as the Class Type property, the following JSON will be produced with the ID value properly represented as a number (without double quotes):
{
"ID": 5,
"Name": "Marty",
"Email": "marty.wasz@neudesic.com",
"ConfirmDate": "2017-06-02T08:11:21.2618385-07:00"
}
Custom DateTime formatting:
Lastly, when using an intermediate .NET Class instance to serialize XML to JSON, all date time formats are ISO 8601 formatted (i.e. “yy-M-ddTHH:mm:ss.fffffffzzz”). However, this can be changed by editing the “DateTime Format” property. To work though, the incoming DateTime value in the XML document must be formatted using standard date time formats and not custom formats (i.e. https://msdn.microsoft.com/en-us/library/az4se3k1.aspx ). If a custom formatted DateTime string is received in the XML, it will throw a serialization exception.
The DateTime Format property is ONLY used when a Class Type is provided.
Converting .NET Class Instances to JSON
Sometimes it is easier for developers to work directly with .NET Class Instances than with XML. Neuron ESB accommodates this by allowing a Neuron ESB Message body to be set with a .NET Class Instance. This allows it to be used within any C# Code Step as shown below. The Body property can be set with the class, and the GetBody<T>() method of the Neuron ESB Message can be used to retrieve the .NET Class Instance.
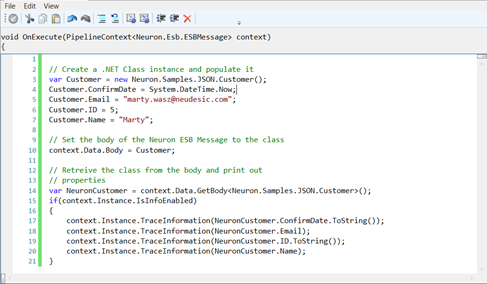
When using the JSON Process Step to translate a .NET Class Instance to JSON, the “Null Value Handling” property is ignored. Additionally, the type information of the class is serialized with the JSON as shown below:
{
"$type": "Neuron.Samples.JSON.Customer,
Neuron.Samples.JSON.Customer",
"ID": 5,
"Name": "Marty",
"Email": "marty.wasz@neudesic.com",
"ConfirmDate": "2017-06-02T10:03:45.2973412-07:00"
}
However, the type information can be suppressed by setting the “Include Object Types” property to false. This property is ONLY visible when a Class Type has been selected. Additionally, the datetime format can be modified to any custom datetime format (i.e. https://msdn.microsoft.com/en-us/library/8kb3ddd4.aspx ). In the sample below, the type information has been suppressed, but additionally, the Datetime Format property has been changed from its default of “yyyy-MM-ddTHH:mm:ss.fffffffzzz” to “yy-M-dd HH:mm:ss tt”:
{
"ID": 5,
"Name": "Marty",
"Email": "marty.wasz@neudesic.com",
"ConfirmDate": "17-6-02 10:05:49 AM"
}
Convert to XML
Use the JSON Process Step to translate JSON documents to XML formatted documents. Once the XML message has been serialized into the Neuron ESB Message, the HTTP.ContentType of the Neuron ESB Message object will be set to “application/xml”. For Instance, the following JSON document includes an enclosing root node, “Customer”:
{
"Customer": {
"ID": 5,
"Name": "Marty",
"Email": "marty.wasz@neudesic.com",
"ConfirmDate": "2017-06-02T08:11:21.2618385-07:00"
}
}
Using the default Process Step settings, the following XML would be produced:
<?xml version="1.0"?> <Customer> <ID>5</ID> <Name>Marty</Name> <Email>marty.wasz@neudesic.com</Email> <ConfirmDate>2017-06-02T08:11:21.2618385-07:00</ConfirmDate> </Customer>
However, if the JSON document did not include an enclosing root (as would be more typical) as shown below:
{
"ID": 5,
"Name": "Marty",
"Email": "marty.wasz@neudesic.com",
"ConfirmDate": "2017-06-02T08:11:21.2618385-07:00"
}
The following error would be generated:
Aborted: JSON root object has multiple properties. The root object must have a single property in order to create a valid XML document.This can be successfully translated though by providing a value for the “XML Root Name” property. By setting the property to “Root”, the following XML documents will be produced:
<?xml version="1.0"?> <Root> <ID>5</ID> <Name>Marty</Name> <Email>marty.wasz@neudesic.com</Email> <ConfirmDate>2017-06-02T08:11:21.2618385-07:00</ConfirmDate> </Root>
Convert to Class
This will work to serialize either a JSON or XML message into a .NET Class Instance which can later be accessed in a C# Code Step using the GetBody<T> method of the Neuron ESB Message object. The Class Type property is the only value required. Given the following JSON message:
{
"Customer": {
"ID": 5,
"Name": "Marty",
"Email": "marty.wasz@neudesic.com",
"ConfirmDate": "2017-06-02T08:11:21.2618385-07:00"
}
}
Its .NET Class instance representation can be retrieved using the following C# in any Code Step enabled Process Step:
// Retrieve the class from the body and print out
// properties
var Customer =
context.Data.GetBody<Neuron.Samples.JSON.Customer>();
if(context.Instance.IsInfoEnabled)
{
context.Instance.TraceInformation(Customer.Email);
context.Instance.TraceInformation(Customer.ID.ToString());
context.Instance.TraceInformation(Customer.Name);
}
Design Time Properties
| Name | Convert To | Description |
| Name | User provided name for the Process Step. Will replace default name of Step when placed on the Design Canvas. | |
| Disable | Boolean flag to determine whether the step should be executed at runtime or design time. NOTE: Also available from the right-click context menu. | |
| Bindings | Launches the Binding Expressions dialog for specifying Environment Variables. | |
| Convert To | Required. Determines what the incoming message will be translated to. Either JSON, XML or Class. Binary is present is marked OBSOLETE and is replaced by the Class option. | |
| Exclude Xml Root | JSON | Required. Default is False. When converting to Json, this will exclude the root element from serializing. |
| Remove Namespaces | JSON | Required. Default is False. When converting to Json, this will remove the namespaces from serializing. |
| Class Type | JSON, XML. Class | Optional. Displays an Assembly Picker Dialog. The fully qualified name of a .NET class to serialize/deserialize to. The assembly must be in the GAC or in the Neuron folder. |
| XML Root Name | XML | Optional. Xml Root name to apply if converting JSON (without a root object) to XML. If a root already exists, this root name will be removed from final XML |
| Include XML Declaration | XML | Required. Default is True. When converting to XML, this will determine if the XML Declaration is written. |
| DateTime Format | JSON | Optional. Used if converting from a .NET Class to JSON, or from JSON to a .NET Class. Default value is the ISO 8601 (internet datetime format) i.e. ‘yyyy-MM-ddTHH:mm:ss.fffffffzzz’. |
| Null Value Handling | JSON | Optional. Used if converting from a .NET Class or XML to JSON. If None, IsEmpty fields e.g. xsi:nil=’true’, will be displayed as xsi:nil=’true’. If set to Null, the element will display a null value. If set to EmptyString, the element will display an empty string as a value. |
Validate JSON
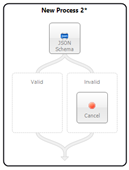
| Category: | Message |
| Class: | EsbMessageJsonValidationProcessStep.cs |
| Namespace: | Neuron.Pipelines |
| Assembly: | Neuron.Pipelines.dll |
Description:
This Step allows you to validate a JSON message in the in ESB Message Body. The JSON Messages is validated against a schema stored in the Document Repository. You can also specify JSON schema as a property of this step if it is not in the repository. You can add a referenced schema location.
There are two branches automatically added for Valid document and Invalid document for you to implement the next steps depending on the outcome.
Design Time Properties
| Name | Description |
| Name | User provided name for the Process Step. Will replace default name of Step when placed on the Design Canvas. |
| Disable | Boolean flag to determine whether the step should be executed at runtime or design time. NOTE: Also available from the right-click context menu. |
| Bindings | Launches the Binding Expressions dialog for specifying Environment Variables. |
| Json Schema Name | Name of Json Schema stored in the Document Repository |
| JsonSchema | You can paste a Json Schema into this Property using the textbox that shows when ellipsis button is clicked. |
| Referenced Schema Location | File system location of any schemas referenced by the schema document. |
Languages
C#
| Category: | Languages |
| Class: | EsbMessageCSharpCodePipelineStep |
| Namespace: | Neuron.Esb.Pipelines |
| Assembly: | Neuron.Esb.Pipelines.dll |
Description:
The.NET Language Process Steps are useful when one of the built-in Neuron Process Steps does not offer the functionality desired. They can be used to create custom processes without having to create custom externally developed and maintained code. Users can choose between the C#, VB.NET and C# Class Process Step. Read more about the .NET Language Code Editors.
The C# Process Step is Modeless Code Editor and is commonly used when there is no need to factor logic into multiple methods, share variables or add additional .NET using statements. The C# Process Step displays the following method signature that passes a pipeline context object, containing the ESB Message to the user:
void OnExecute(PipelineContext<Neuron.Esb.ESBMessage> context)
{
// TODO: implement custom code here.
}
The Pipeline Context object represents the Business Process instance and is used to access several things at design time and runtime including the existing Neuron ESB Configuration, Environment Variables, Properties, Party, as well as the current message being processed, as shown in the Figure below.
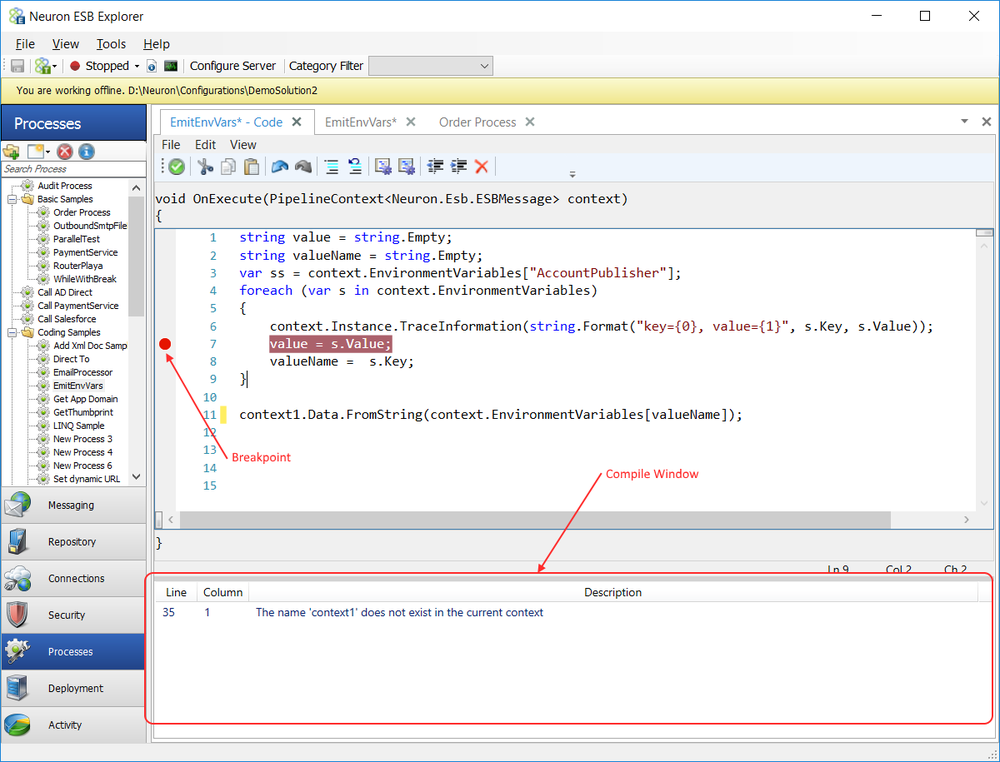
C# Code Editor Modeless Code Editor of the C# Process Step
As can be seen from the figure above, calculating the correct Line is required when using the C# Process Step. The Process Step has a hidden part of the code template, which contains the using statements.
For the C# Process Step, subtract 21 from the Line number displayed in the Compile Window. Using the example above, 35 21 = Line 11, which is the line number the error would be occurring on.
To save changes made to the Code Editor the Save button, located on the Code Editor Toolbar, must be clicked; followed by the Neuron ESB Explorers Save Toolbar button or menu item, as shown in the figure below. The Save button will also save any pending changes to the underlying Business Process.
Save Toolbar Button Located on the Modeless Code Editor of the C# Process Step
For more information on how to use Neuron ESB specific APIs within the Code Editor, review the Code Editor API Samples section of the documentation.
Design Time Properties
| Name | Dynamic | Description |
| Name | User provided name for the Process Step. Will replace default name of Step when placed on the Design Canvas. | |
| Disable | Boolean flag to determine whether the step should be executed at runtime or design time.
NOTE: Also available from the right-click context menu.
| |
| Bindings | Launches the Binding Expressions dialog for specifying Environment Variables.
NOTE: THERE ARE NO BINDABLE PROPERTIES FOR THIS PROCESS STEP.
|
C# Class
| Category: | Languages |
| Class: | EsbMessageCSharpCustomPipelineStep |
| Namespace: | Neuron.Esb.Pipelines |
| Assembly: | Neuron.Esb.Pipelines.dll |
Description:
The.NET Language Process Steps are useful when one of the built-in Neuron Process Steps does not offer the functionality desired. They can be used to create custom processes without having to create custom externally developed and maintained code. Users can choose between the C#, VB.NET and C# Class Process Step. Read more about the .NET Language Code Editors.
The C# Class Process Step is Modeless Code Editor and offers some advantages over the C# Process Step. The C# Class offers developers a way to refactor their code, reducing its complexity. It also allows developers to add using statements and define their own namespaces. The C# Class Process Step provides an existing template that developers can modify by changing the namespace and class names. Developers can add additional methods, static or non-static variables and new classes as shown in the figure below.
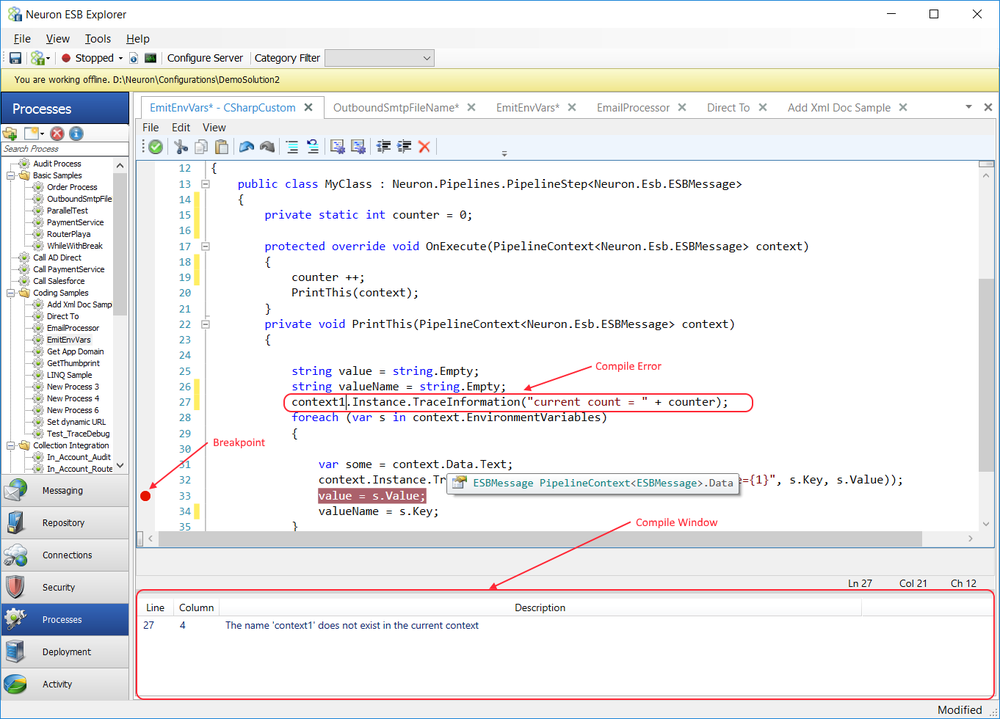
C# Class Code Editor Modeless Code Editor of the C# Class Process Step
The C# Class Process Step provides the following class template that passes a pipeline context object, containing the ESB Message to the user:
#define DEBUG
#define TRACE
using System;
using System.Collections;
using System.Collections.Generic;
using System.Collections.Specialized;
using System.Data.DataSetExtensions;
using System.Linq;
using System.Xml.Linq;
using System.Xml;
using Neuron.ServiceModel;
using Neuron.Pipelines;
using Neuron.Esb;
using Newtonsoft.Json;
using Newtonsoft.Json.Linq;
namespace __DynamicCode // Users can change the Namespace name.
{
// Users can change the Class name
public class __PipelineStep__ :
Neuron.Pipelines.PipelineStep<Neuron.Esb.ESBMessage>
{
protected override void OnExecute(
PipelineContext<Neuron.Esb.ESBMessage> context)
{
// TODO: implement custom logic here.
}
// Users can add additional methods
}
// Users can add additional classes
}
The Pipeline Context object represents the Business Process instance and is used to access several things at design time and runtime including the existing Neuron ESB Configuration, Environment Variables, Properties, Party, as well as the current message being processed.
To save changes made to the Code Editor the Save button, located on the Code Editor Toolbar, must be clicked; followed by the Neuron ESB Explorers Save Toolbar button or menu item, as shown in the figure below. The Save button will also save any pending changes to the underlying Business Process.
Save Toolbar Button Located on the Modeless Code Editor of the C# Class Process Step
For more information on how to use Neuron ESB specific APIs within the Code Editor, review the Code Editor API Samples section of the documentation.
Design Time Properties
| Name | Dynamic | Description |
| Name | User provided name for the Process Step. Will replace default name of Step when placed on the Design Canvas. | |
| Disable | Boolean flag to determine whether the step should be executed at runtime or design time.
NOTE: Also available from the right-click context menu.
| |
| Bindings | Launches the Binding Expressions dialog for specifying Environment Variables.
NOTE: THERE ARE NO BINDABLE PROPERTIES FOR THIS PROCESS STEP.
|
VB.NET

| Category: | Languages |
| Class: | EsbMessageVBCodePipelineStep |
| Namespace: | Neuron.Esb.Pipelines |
| Assembly: | Neuron.Esb.Pipelines.dll |
The.NET Language Process Steps are useful when one of the built-in Neuron Process Steps does not offer the functionality desired. They can be used to create custom processes without having to create custom externally developed and maintained code. Users can choose between the C#, VB.NET and C# Class Process Step. Read more about the .NET Language Code Editors.
The VB.NET Process Step is Modeless Code Editor. Writing VB.NET code within a Process is as simple as dragging the VB.NET Process Step onto the Process Designer, right click and selecting edit code from the context menu. Users will receive the same experience as provided by the C# Process Step. The VB.NET Process Step displays the following method signature that passes a pipeline context object, containing the ESB Message to the user:
Sub OnExecute(ByVal context As PipelineContext(Of ESBMessage))
{
// TODO: implement custom code here.
}
The Pipeline Context object represents the Business Process instance and is used to access several things at design time and runtime including the existing Neuron ESB Configuration, Environment Variables, Properties, Party, as well as the current message being processed, as shown in the Figure below.
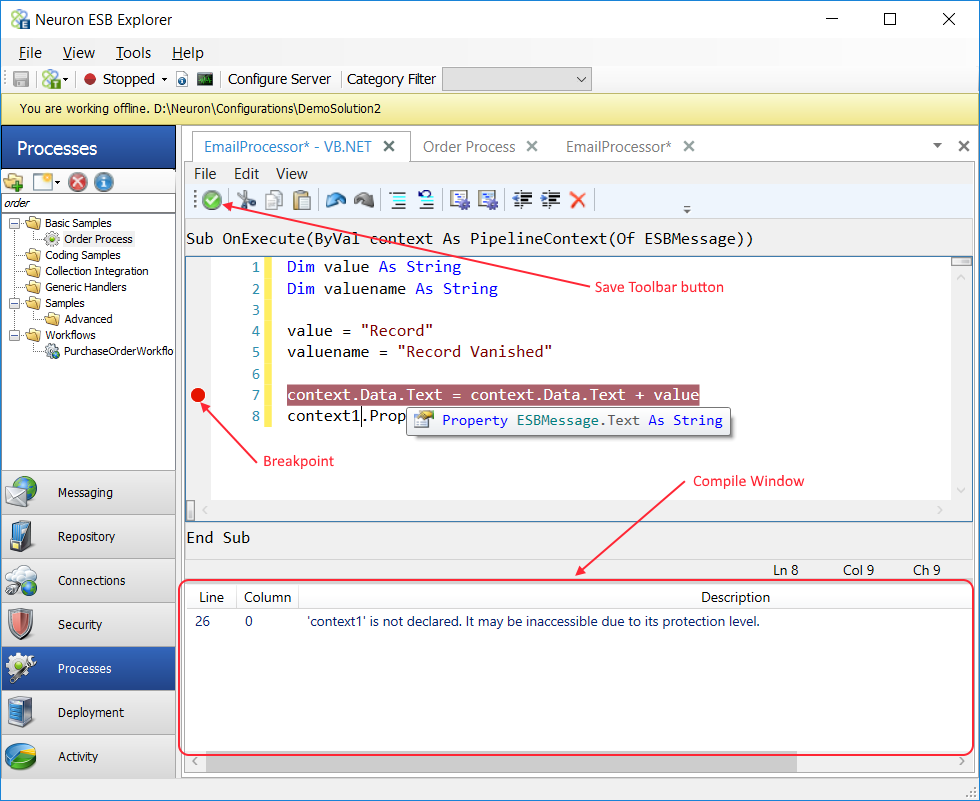
VB.NET Code Editor Modeless Code Editor of the VB.NET Process Step
As can be seen from the figure above, calculating the correct Line is required when using the VB.NET Process Step. The Process Step has a hidden part of the code template, which contains the using statements.
For the VB.NET Process Step, subtract 18 from the Line number displayed in the Compile Window. Using the example above, 35 18 = Line 17, which is the line number the error would be occurring on.
To save changes made to the Code Editor the Save button, located on the Code Editor Toolbar, must be clicked; followed by the Neuron ESB Explorers Save Toolbar button or menu item, as shown in the figure below. The Save button will also save any pending changes to the underlying Business Process.
Save Toolbar Button Located on the Modeless Code Editor of the VB.NET Process Step
For more information on how to use Neuron ESB specific APIs within the Code Editor, review the Code Editor API Samples section of the documentation.
Design Time Properties
| Name | Dynamic | Description |
| Name | User provided name for the Process Step. Will replace default name of Step when placed on the Design Canvas. | |
| Disable | Boolean flag to determine whether the step should be executed at runtime or design time.
NOTE: Also available from the right-click context menu.
| |
| Bindings | Launches the Binding Expressions dialog for specifying Environment Variables.
NOTE: THERE ARE NO BINDABLE PROPERTIES FOR THIS PROCESS STEP.
|
Message
Audit
| Category: | Message |
| Class: | EsbMessageAuditPipelineStep |
| Namespace: | Neuron.Esb.Pipelines |
| Assembly: | Neuron.Esb.Pipelines.dll |
Description:
The Audit Process Step is an extension of the Neuron ESB Audit Service. The Neuron ESB Audit Service is an internal Neuron ESB runtime service used to archive Neuron ESB Messages to the Neuron ESB database. There are two ways to Audit messages:
- As an historical archive that consists of only the Neuron ESB Message. Internally these are stored in a Message History database table and viewable in the Message History Report within the Neuron ESB Explorer.
- As a Failure that consists of the Neuron ESB Message and Exception Information that caused the message to fail within the system. Internally these are stored in a Failed Message table and viewable in the Failed Messages Report within the Neuron ESB Explorer.
Auditing can be configured either directly through a Topics Auditing option, an Adapter or Service Policys Failure Action option (i.e. Failures) or using the Audit Process Step. Additionally, some Topic Network Transport properties can be configured to direct messages to be Audited as Failures in the case where no subscribers exist for the incoming message (i.e. TCP/Named Pipes/MSMQ). Lastly, exceptions raised within the system that are not caught by a configured Policy, but where the message is available, will automatically be archived as a Failure.
Configuring Auditing at the Topic level ensures that all messages received and sent over Topics are archived. Although this can work for Messaging scenarios, it lacks the flexibility to use in more complex Business scenarios. Topic level Auditing tends to cast a wide net, archiving information that may not be necessary or even desirable. In contrast, the Audit Process Step gives the user granular control of exactly what to archive (the whole message or just part of it) and where the archive should take place in a business process (i.e. before or after some sequence of events). In addition, the Audit Process Step provides the user the ability to customize exception handing and Audit Failures any place within a Business Process, capturing the error information as well as the context (i.e. Parent Process, Process that threw exception, Process Step generating the original error, custom exception messages, etc.) so that action can be taken (i.e. resubmitting the message for processing).
The Audit Process step has a number of configurable properties. However, there are two properties located on the Auditing Tab of the Topic that directly affect the execution of the Audit Process Step. Both properties are checkboxes, enabled by default. These are:
- Audit messages asynchronously
- Use verbose detail when auditing message failures
The first property, Audit messages Asynchronously, determines if the Audit Process Step will archive the message using a blocking or non-blocking call to the Neuron ESB Audit Service. For example, if the property was disabled (unchecked), control will not pass to the next Process Step until the call to the Neuron ESB Audit Service returns successfully. If an exception is encountered, it will be thrown to the underlying Business Process. In contrast, if the property was enabled/checked (the default), the call will be made as a datagram, only waiting to see if the call was successful to the network, not necessarily all the way to the Neuron ESB Service. If there is an exception, it will be recorded in the Neuron ESB Log files and the Windows Event log but the exception will NOT be thrown to the underlying Business Process. This will allow control to continue to the next Process Step in the process without waiting for the actual Neuron ESB Auditing Service to respond.
The second property only applies to the Audit Process Step when its Action property is set to Failure. The Use verbose detail when auditing message failures determines whether the full exception stack (i.e. verbose detail) or just the exception message will be logged with the ESB Message if an exception is thrown within a Business Process and recorded by the Audit Process Step.
Action Property
The Action property determines if, how and where the Audited Message will appear in either Message History and Failed Messages reports within the Neuron ESB Explorer. There are four Action property values including None, Receive, Send and Failure.
None
If the Action is set to None, the Neuron ESB Message will NOT be audited at runtime. The call to the Neuron ESB Audit Service is essentially ignored.
Send/Receive
If the Action is set to either Receive or Send, the Neuron ESB Message will be archived to the Message History table where it will be viewable in the Message History Report as shown below. The Action property will be displayed in the Direction column:
Providing that the following message was Audited:
<ProcessPayment xmlns="https://tempuri.org/" xmlns:xsd="https://www.w3.org/2001/XMLSchema"> <request xmlns:a="https://schemas.datacontract.org/2004/07/PaymentService" xmlns:i="https://www.w3.org/2001/XMLSchema-instance"> <a:PaymentProcessRequest> <a:Amount>6666</a:Amount> <a:OrderId>efab608f-f70f-4d27-8e78-c430b28004ac</a:OrderId> </a:PaymentProcessRequest> </request> </ProcessPayment>
It would be viewable in the Message Viewer dialog by double clicking on the row in the Message History report:
Along with the message body, all of the Neuron ESB Message Header properties (Neuron Properties tab) and custom properties (Custom Properties tab) are viewable in the Message Viewer dialog.
Failure
If the Action is set to Failure, the Audit Process Step will attempt to retrieve the PipelineException context property. Its Failure Type and Failure Detail properties will be auto populated by the PipelineException objects inner exception property (i.e. the original exception thrown by the Process Step). It will also use that exception information and ambient properties such as the name of the process and step that generated the exception as well as the name of the parent process, if there is one. The PipelineException context property is populated by the process runtime anytime a Process Step throws an Exception. Because of this, the Audit Process Step is commonly used in the Catch Execution Block of the Exception Process Step.
The Use verbose detail when auditing message failures directly affects the error messages format and detail that is recorded in the Failed Messages table and viewable in the Failed History Report. For example, if this property was unchecked/disabled the following exception would be recorded as the Failure Detail property value:
Parent Process: Unknown Process Name
Source Process: call payment service
Source Process Step: MsmqThe queue does not exist or you do not have sufficient permissions to perform the operation.
In contrast, if the verbose detail property is enabled/checked (default) the error message along with the full exception stack and any inner exceptions will be recorded as the Failure Detail property value:
Parent Process: Unknown Process Name
Source Process: call payment service
Source Process Step: Msmq
Exception Type: System.Messaging.MessageQueueException
Exception Message: The queue does not exist or you do not have sufficient permissions to perform the operation.
Exception Trace:
at System.Messaging.MessageQueue.ResolveFormatNameFromQueuePath(String queuePath, Boolean throwException)
at System.Messaging.MessageQueue.get_FormatName()
at System.Messaging.MessageQueue.get_Transactional()
at Neuron.Esb.Pipelines.EsbMessageMsmqPipelineStep.ValidateLocalQueueForTransactions(MessageQueue queue, String pipelineName) in d: euron\Dev\3.5.4\sdk\core\latest euronEsbSdk\Esb.Pipelines\EsbMessageMsmqPipelineStep.cs:line 796
at Neuron.Esb.Pipelines.EsbMessageMsmqPipelineStep.SendToQueue(MessageQueue queue, PipelineContext`1 state) in d: euron\Dev\3.5.4\sdk\core\latest euronEsbSdk\Esb.Pipelines\EsbMessageMsmqPipelineStep.cs:line 708
The latter can be very useful for debugging application solutions.
Design Time Testing
When testing the Audit Process Step in the Process Designer, the user must supply the Source ID (name of the Party) and Topic in the Edit Test Message dialog. Both Party and Topic must exist in the opened solution and the open solution MUST be running in the local Neuron ESB Service runtime. More information can be found in the Testing Live Process Steps section of this documentation.
Additionally, if the Action property is set to None, the Audit Process Step will throw an AuditStepException to the user. Whereas at runtime, if the Action property is set to None, no Neuron ESB Message will be audited.
Dynamic Configuration
In some scenarios, developers may need to declare values for the Failure Type and Failure Detail properties at runtime, rather than relying on design time configuration. For example, there may be a business logic where, depending on the condition, it may be desirable to record the condition as an actual exception (Failure) so that monitoring tools and operations could be alerted to the condition, even though an actual exception was not thrown within the Business Process. The logic path may determine what the Failure Type and Failure Detail should be. Moreover, there may be information at runtime that needs to be incorporated into the Failure Detail message recorded.
Setting the Failure Detail and Failure Type properties could be done using the Set Property Process Step or a Code Step. If a Code Step was used, the following ESB Message Property must be set:
context.Data.SetProperty("neuron", " FailureDetail",
"My custom details");
context.Data.SetProperty("neuron", " FailureType",
"System.Exception");
The Audit Step will look for the ESB Message properties (if it exists) and extract their values. If the ESB Message properties do not exist, it will default to the design time configuration of the Audit Process Step.
The prefix for all Audit custom message properties it neuron and they can be accessed directly from the Neuron ESB Message object using the GetProperty() or GetProperties() methods. All Neuron ESB Message properties can also be set using the Set Property Process Step.
| Process Step | Custom Property (i.e. prefix.name) | Design-time Property |
| Audit | neuron.FailureType | Failure Type |
| neuron.FailureDetail | Failure Detail |
Performance Optimizations
The Audit Process Step uses a Blocking pool of Service Proxies (connections to the Neuron ESB Audit Service) to allow better scale out for concurrency and to eliminate all calls being serialized through one instance of the Service Proxy. There are 2 properties located in the Pool Management property category. Maximum Instances (defaults to 1) and Pool Timeout (defaults to 1 minute). Once the maximum number of Service Proxies have been created, the Pool Timeout determines the amount of time to wait for an existing Service Proxy to become available before throwing a timeout exception.
Before a Service Proxy is created, the pool is always checked to see if one already exists. If it does, it retrieves is from the pool and uses it. When complete, the Service Proxy is returned to the pool. The Maximum Instances property does NOT define the number of Service Proxies that will always be created at runtime in all circumstances. It only defines the maximum number that could be created. For instance, Business Processes attached to most inbound Adapter Endpoint will generally only create one pooled Service Proxy as many of the adapters only work with one inbound thread at a time (unless receiving messages from Topics). However, a Client Connector (Neuron ESB hosted service endpoint) could be dealing with many more threads representing concurrent users making service calls.
Unlike the pooling properties for other Process Steps, the Maximum Instances for the Audit Step defaults to 1. Since the Neuron ESB Audit Service is a configured as a Per Instance service, general guidance is to test any increase in the Maximum Instance setting against the business scenario. This number should not exceed the Maximum Concurrent Instances property located in the Internal Service Binding Settings section of the Server tab of the Zone for the solution. More than likely, any setting above 50 will likely bring diminished returns.
Design Time Properties
| Name | Dynamic | Description |
| Name | User provided name for the Process Step. Will replace default name of Step when placed on the Design Canvas. | |
| Disable | Boolean flag to determine whether the step should be executed at runtime or design time.
NOTE: Also available from the right-click context menu.
| |
| Bindings | Launches the Binding Expressions dialog for specifying Environment Variables. | |
| Action | Required. Default is None. None: The message will NOT be stored into the audit table. Send: The message will be stored into the audit table with the action Send. Receive: The message will be stored into the audit table with the action Receive. Failure: The message will be stored into the audit failure table with the failure detail and failure type auto populated by the PipelineException context property, unless overridden by the Failure Detail and Failure Type Audit Step properties | |
| Audit Custom Properties | Required. Default is True. This is used to determine if custom Neuron ESB Message properties are archived with the Neuron ESB Message. | |
| Audit Message Body | Required. Default is True. This is used to determine if the message body of the Neuron ESB Message is archived. If set to False, all the Neuron ESB Message Header properties will be archived, but the message body will not. | |
| Failure Detail | YES | Optional. If the Action is Failure, then the detail specified here would be stored with the messages in the audit failure table. If this property is not set and the process context property “CurrentException” is set, then the failure details will be the message and or stack trace of the exception object in the property. |
| Failure Type | YES | Optional. If the Action is Failure, then this is a short description of the type of failure that occurred. If this property is not set and the process context property “CurrentException” is set, then the failure type will be the exception object type in the property. |
| XPath | Optional. Will ONLY be applied if Audit Message Body property is set to True. This is an XPATH 1.0 statement that returns a node set. The returned node set will be the message body archived with the Neuron ESB Message rather than the original message body. | |
| Maximum Instances | Required. Defines the maximum of number of Service Proxies that will be created and cached in a concurrent pool. Each thread of execution retrieves a Service Proxy from the pool. After execution, the Service Proxy is returned to the pool. If the maximum number of Service Proxies has already been created, the execution thread will wait for the specified period configured for the Pool Timeout property for another Service Proxy to become available. Default Value is 1. | |
| Pool Timeout | Required. The period a thread may wait for a Service Proxy to become available to be retrieved from the pool If the maximum number of pooled Service Proxies has already been reached. A timeout exception will be thrown if the Pool Timeout period is exceeded. Default Value is 1 minute. |
Sample
In the Sample below, the steps in the process demonstrate the use of an Audit Process Step to archive a fragment of the incoming the message as well as capture the exception information (and message that generated it) generated by the mis-configured MSMQ Process Step.
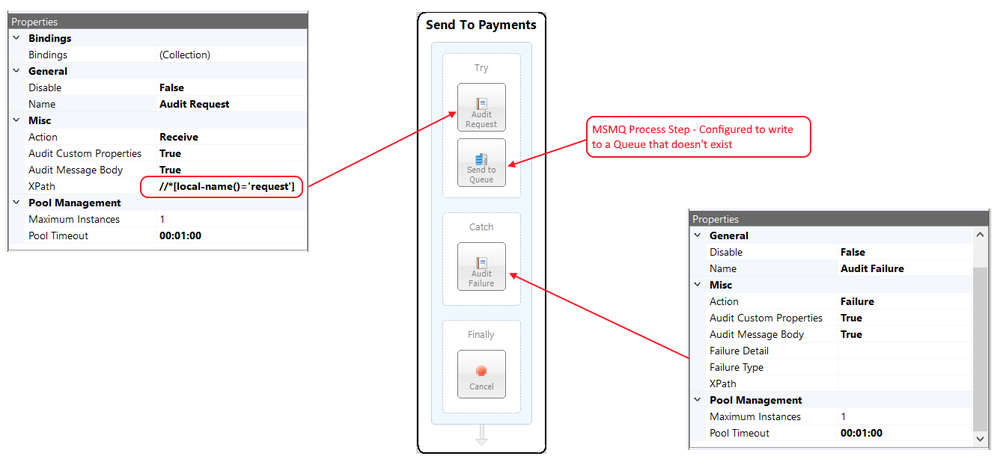
The Incoming ProcessPayment XML message submitted to the Business Process is represented below:
<ProcessPayment xmlns="https://tempuri.org/" xmlns:xsd="https://www.w3.org/2001/XMLSchema"> <request xmlns:a="https://schemas.datacontract.org/2004/07/PaymentService" xmlns:i="https://www.w3.org/2001/XMLSchema-instance"> <a:PaymentProcessRequest> <a:Amount>6666</a:Amount> <a:OrderId>efab608f-f70f-4d27-8e78-c430b28004ac</a:OrderId> </a:PaymentProcessRequest> </request> </ProcessPayment>
The first Audit Step is configured to use the following XPATH 1.0 statement to archive only the request node of the ProcessPayment XML message above:
//*[local-name()='request']
The archived message fragment is viewable in the Message History report using the Message Viewer dialog as shown below:
After the Audit Step archives the fragment of the message, control moves to the MSMQ Process step, which is configured to send to a queue that does not exist. This throws an exception, which is caught by the Audit Step, located in the Catch Execution Block. This in turn generates the following message in the Failed Messages report:
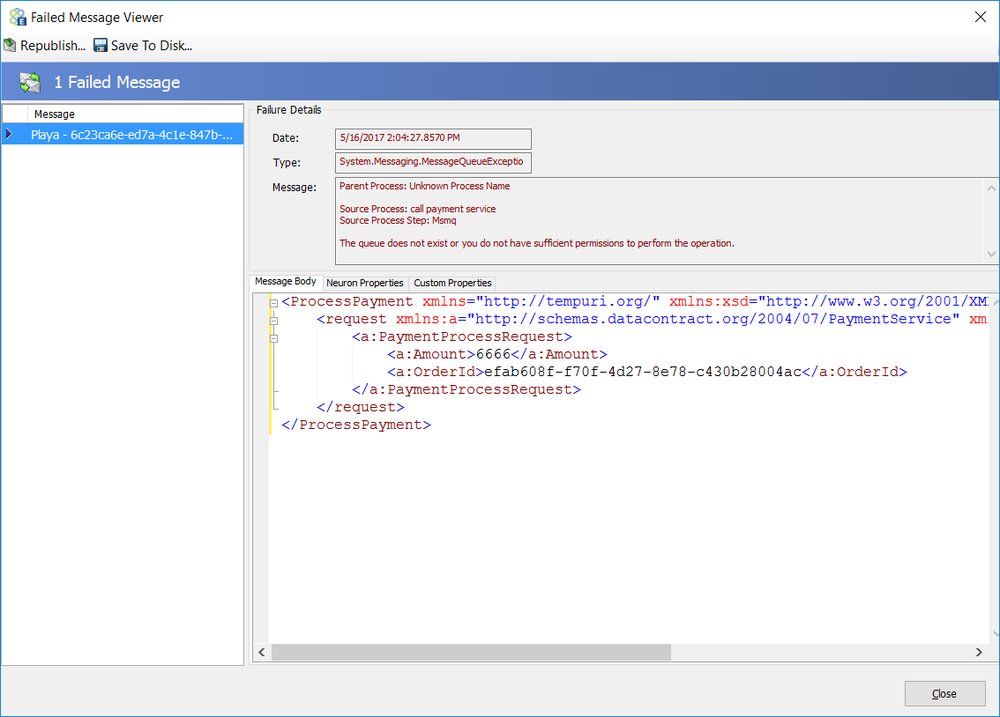
Compression
| Category: | Message |
| Class: | ZipUnzipStep |
| Namespace: | Neuron.Esb.Pipelines |
| Assembly: | Neuron.Esb.Pipelines.dll |
Description:
The Compression Process Step can be used to Compress or Decompress incoming messages. This step is commonly used in the following scenarios:
- When either Service or Adapter Endpoints receive compressed files (i.e. zip, gzip, etc.) and there is a requirement to decompress them so that a Business Process can process the information further.
- When there is a business requirement to send compressed information to either Service or Adapter Endpoints
The Compression Process Step uses Xceed API internally for all operations. The Step supports most compression algorithms, multiple files within a compressed incoming message (i.e. file) and recursive decompression of an incoming message (i.e. a compressed file within a compressed file or Folder within a compressed file). RAW Deflate (which can be used with MSFTs library or PHPs zlib), GZip and Winzip 12 compatible compression methods are also supported.
The Compression Step populates a number of Neuron ESB Message properties that contains meta data about the compression or decompression process that can be inspected directly after the Compression Step executes. These properties are listed in the table included with this documentation.
The Compression/Decompression methods supported are:
- BWT
- BZip2
- Deflated
- Deflated64
- LZMA
- PPMd
- Stored
- DeflatedRaw
- GZip
Compression
When compressing incoming messages, the File Name property must be provided for all Compression Methods except GZip and DeflatedRaw. This can be provided at either design time or runtime. If a File name property is not provided, the Compression step will create one composed of the following pseudo code:
var fileName = System.Guid.NewGuid().ToString() + ".bin";
The final output of the Compression Step is a binary payload stored in the Neuron ESB Messages Bytes property and the following happens:
- A new Neuron ESB Message is created with a new Message ID
- Context.Data.Bytes is set to the Bytes of compressed message
- Context.Data.BodyType is set to “binary/bytes”
- Context.Data.Binary is set to true
- Context.Data.Header.UncompressedBodySize is set to the length of the original incoming message before being compressed
- Context.Data.Header.Compressed is set to true
- Context.Data.Header.CompressedBodySize is set to the bytes length of the compressed message
- Context.Data.Header.Compressed is set to true.
- The compression Message Properties will be populated.
Decompression
When decompressing incoming messages, Neuron ESB provides the following API specifically to access decompressed messages. This is helpful if there was more than one message (i.e. file) included in the incoming compressed message as it includes an Attachments collection.
Class: ZipMessage
Namespace: Neuron.Esb.Zip
Assembly: Neuron.Esb (in Neuron.Esb.dll)
Syntax:
[Serializable]
public sealed class ZipMessage
{
public static byte[] Serialize<T>(T message);
public static ZipMessage Deserialize(byte[] bytes);
private Collection<Attachment> attachments;
public Collection<Attachment> Attachments { get; set;}
}
Class: Attachment
Namespace:Neuron.Esb.Zip
Assembly:Neuron.Esb (in Neuron.Esb.dll)
Syntax:
[Serializable]
public sealed class Attachment
{
public Byte[] Content { get; set; }
public string Filename { get; set; }
public int Length { get; set; }
public string CompressionLevel { get; set; }
public string CompressionMethod { get; set; }
public string EncryptionMethod { get; set; }
public bool IsFolder { get; set; }
public bool ContentEncoding { get; set; }
public bool ContentType { get; set; }
}
The Neuron ESB Message property, compression.count is always populated when decompressing incoming messages. The value can be retrieved to determine whether the Neuron ESB API should be used to process the individual messages. The following C# fragment sample can be used in a C# Code Step to output each individual file to the file system. Alternatively, a For Each Process Step can be used, allowing greater flexibility on what to do with each individual attachment (i.e. call a service, publish to Topic, etc.):
// Determine how many files were decompressed from incoming message
var count = int.Parse(context.Data.GetProperty("compression",
"Count","0"));
if(count > 0 )
{
// Get the uncompressed message payload. Each
// uncompressed message be represented as an Attachment
var zipMessage = Neuron.Esb.Zip.ZipMessage.Deserialize(
context.Data.InternalBytes);
//Loop through the attachments, and write each to the file
//system.
foreach(var att in zipMessage.Attachments)
{
context.Instance.TraceInformation(att.Filename);
context.Instance.TraceInformation(att.CompressionLevel);
context.Instance.TraceInformation(att.CompressionLevel);
context.Instance.TraceInformation(att.EncryptionMethod);
context.Instance.TraceInformation(att.IsFolder.ToString());
System.IO.File.WriteAllBytes(@"E:\Assets\ziptest\Out\"
+ file.Filename, file.Content);
}
}
If the incoming message only consists of one compressed file, the API is not needed for retrieving the message or inspecting the compression properties as the following happens:
- A new Neuron ESB Message is created with a new Message ID
- Context.Data.Bytes is set to the Bytes of uncompressed message
- Context.Data.BodyType is set to “binary/bytes” or, if the ContentType property is not null, “text/xml”.
- Context.Data.Header.UncompressedBodySize is set to the length of the uncompressed bytes;
- Context.Data.Header.Compressed is set to false.
- The compression Message Properties will be populated.
This ensures the content of the decompressed message becomes the current Neuron ESB Message and is forwarded to the next Process Step in the Business Process.
The prefix for all Compression custom message properties it compression and they can be accessed directly from the Neuron ESB Message object using the GetProperty() or GetProperties() methods. All Neuron ESB Message properties can also be set using the Set Property Process Step.
Neuron ESB Message Properties
| Process Step | Method | Custom Property (i.e. prefix.name) | Description |
| Compression | Compress/ Decompress | compression.CompressionLevel | The Compression Level used successfully. Can be any of the following: Highest Lowest None Normal |
| Compress/ Decompress | compression.CompressionMethod | The Compression Method used successfully. Can be any of the following: BWT BZip2 Deflated Deflated64 LZMA PPMd Stored DeflatedRaw GZip | |
| Decompress | compression.EncryptionMethod | String indicating original Encryption method used | |
| Compress/ Decompress | compression.IsFolder | Determines if the object is a folder versus a file | |
| Decompress | compression.Count | Number of files decompressed from original incoming message | |
| Decompress | compression.Filename | Name of file name embedded in the header of the decompressed file.
NOTE: DeflateRaw does not expose a Filename property
| |
| Decompress | compression.Comment | Only available if Compression Method is GZip. Original comment embedded in compressed file. | |
| Decompress | compression.IsTextFile | Only available if Compression Method is GZip. Original IsTextFile property embedded in compressed file. | |
| Decompress | compression.LastWriteDateTime | Only available if Compression Method is GZip. Original LastWriteDateTime property embedded in compressed file. | |
| Decompress | compression.ContentEncoding | Contains the System.Encoding BodyName property. Empty string if binary file. | |
| Decompress | compression.ContentType | Contains the MIME content type of the Filename extension. The default value is “application/octet-stream”. |
Dynamic Configuration
In some scenarios, developers may need to declare values for the File name property at runtime, rather than relying on design time configuration. When compressing incoming messages, the File Name property must be provided for all Compression Methods except GZip and DeflatedRaw. If provided at runtime, the following Neuron ESB Message property can be set in a Code Process Step immediately before the Compression Step:
context.Data.SetProperty("compression", "Filename",
"mycompressedFile.pdf");
| Process Step | Custom Property (i.e. prefix.name) | Design-time Property |
| Compression | compression.Filename | File name |
Design Time Properties
| Name | Dynamic | Description |
| Name | User provided name for the Process Step. Will replace default name of Step when placed on the Design Canvas. | |
| Disable | Boolean flag to determine whether the step should be executed at runtime or design time. NOTE: Also available from the right-click context menu. | |
| Bindings | Launches the Binding Expressions dialog for specifying Environment Variables. Only Password and File name are bindable properties | |
| Type of Operation | Required. Default is Decompress. Either Compress or Decompress | |
| Recursion | Optional. Default is False. Only visible if Type of Operation is set to Decompress. | |
| Compression Method | Required. Default is Deflated. The following methods can be selected: BWT BZip2 Deflated Deflated64 LZMA PPMd Stored DeflatedRaw GZip | |
| Compression Level | Required. Default is Normal. The following levels can be selected: None Lowest Normal Highest | |
| Encryption Password | Optional. Not available if GZip or DeflatedRaw are selected as Compression Methods. | |
| File name | YES | Optional. Only enabled if Type of Operation is set to Compress. Not available if GZip or Deflated are selected as Compression Methods. |
Sample
In the Sample below, the steps in the process demonstrate the use of the Compression Step to unzip an incoming message that contains several files of different types (i.e. text file, PDF file, Excel, etc.). After the Compression Step executes, a Decision step examines one of the message properties generated by the Step to determine if more than one file was decompressed from the incoming message. If there was more than one, then a For Each Process Step is used to iterate through the files, trace out their properties and publish each one individually to a Topic.
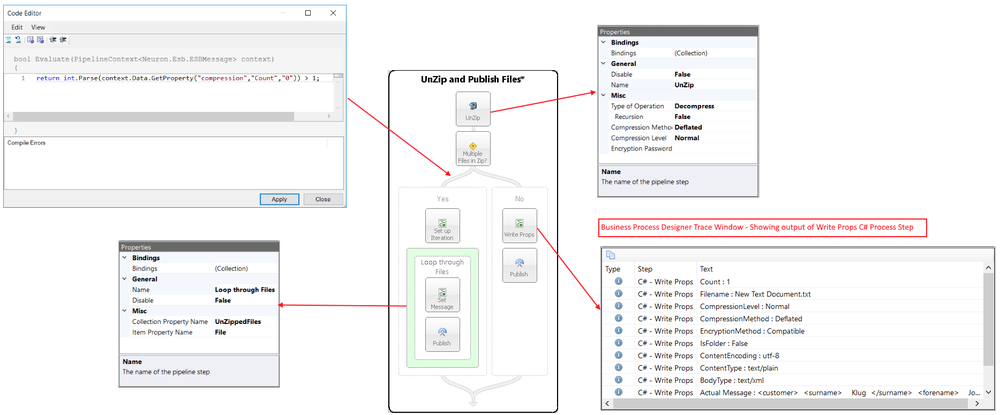
The Unzip and Publish Files Business Process is tested in the Business Process Designer. Once the Edit Test Message dialog is displayed, the *.zip file containing several files is selected by clicking the Load File command button as shown below:
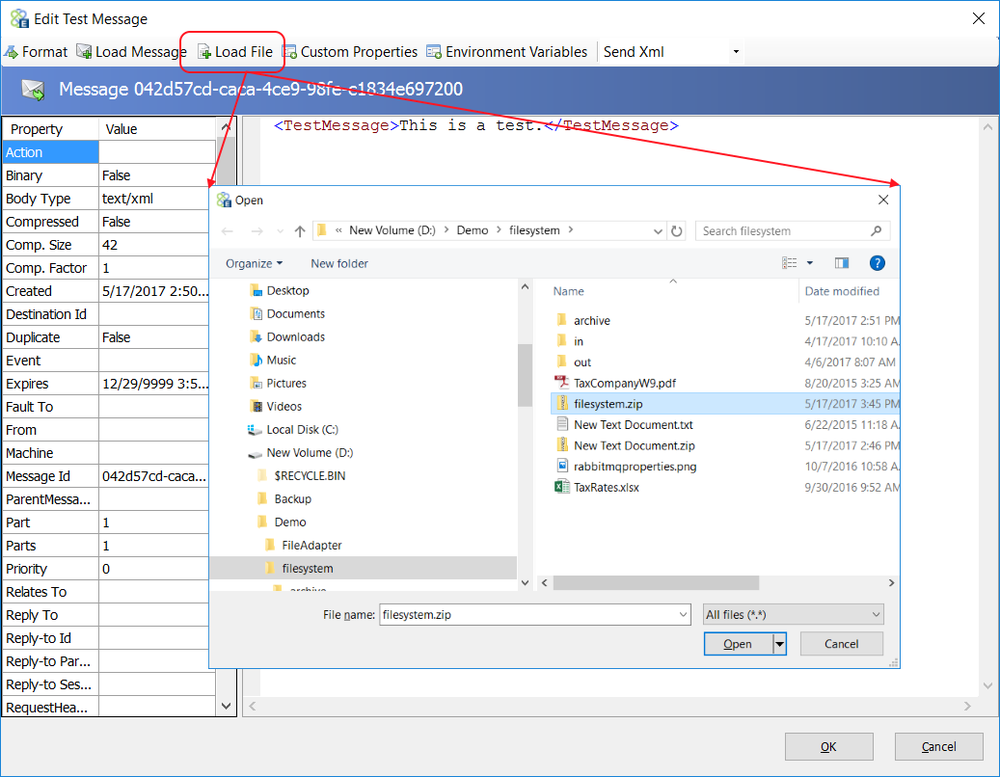
This will read the binary file into the dialog (see figure below) and pass its contents as the Neuron ESB Message body to the Business Process.
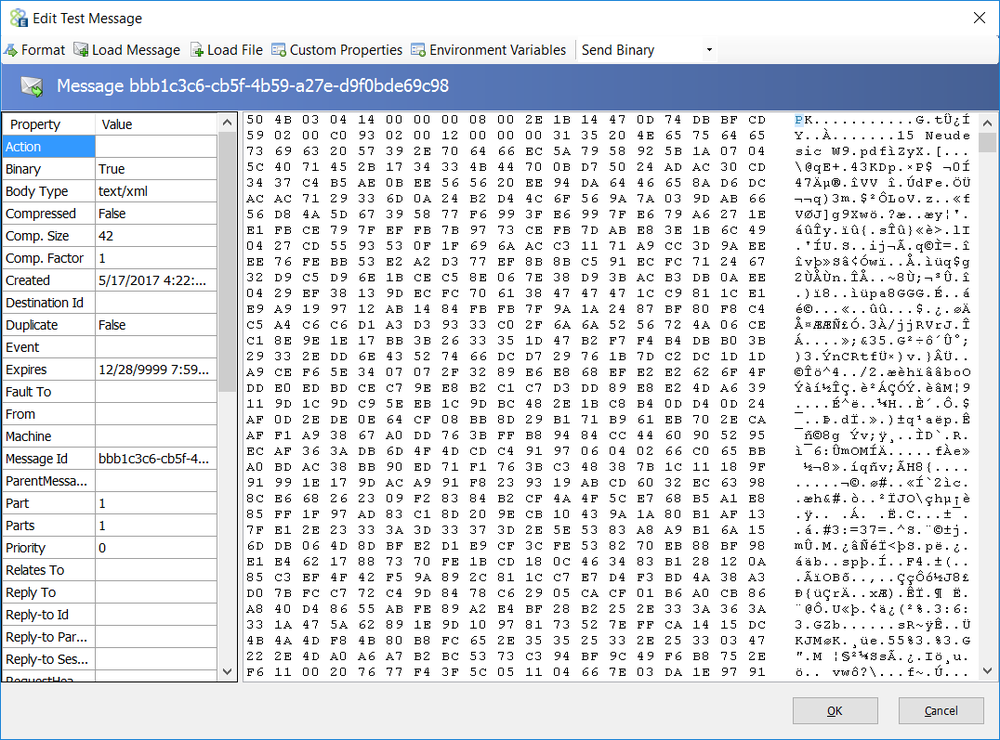
The UnZip Compression Process Step will decompress the incoming binary message into a new Neuron.Esb.Zip.ZipMessage object, serializing it as the new body for the Neuron ESB Message. Next, the Decision Process Step will execute the following logic to determine if multiple files were decompressed from the original binary message:
return int.Parse(context.Data.GetProperty("compression","Count","0"))
> 1;
If True, control moves to the Set up Iteration C# Code Step, where the collection for the For Each Process Step is initialized:
var zipMessage = Neuron.Esb.Zip.ZipMessage.Deserialize(context.Data.Bytes);
context.Properties.Add("UnZippedFiles", zipMessage.Attachments);
The For Each Process Step uses the enclosed Set Message C# Code Step to retrieve each individual decompressed file and convert it into a new Neuron ESB Message. Each one is later published to a Topic, independent of the original incoming message or other decompressed files. The Set Message Step accesses all of the Neuron.Esb.Zip.Attachment properties to set the Neuron ESB Message body and header properties as well as trace out to the Neuron ESB Log and Trace Window the values of Attachment properties as shown in the C# sample below:
// Retrieve the decompressed file and create a new
// child message retaining parent/child relationship
var file = (Neuron.Esb.Zip.Attachment)context.Properties["File"];
context.Data = context.Data.Clone(false);
// Set the current Neuron ESB Message with the file bytes
context.Data.Bytes = file.Content;
// set the Neuron ESB Message binary properties
// in case other steps will content
if(!string.IsNullOrEmpty(file.ContentEncoding))
{
context.Data.Header.Binary = false;
context.Data.Header.BodyType = string.IsNullOrEmpty(file.Filename)?
file.ContentEncoding:file.ContentType;
}
else
{
context.Data.Header.Binary = true;
context.Data.Header.BodyType = file.ContentType;
}
// Trace out meta data and contents of file to
// Neuron ESB Log file and Trace Window
if(context.Instance.IsInfoEnabled)
{
context.Instance.TraceInformation("CompressionLevel
: " + file.CompressionLevel);
context.Instance.TraceInformation("CompressionMethod
: " + file.CompressionMethod);
context.Instance.TraceInformation("ContentEncoding
: " + file.ContentEncoding);
context.Instance.TraceInformation("EncryptionMethod
: " + file.EncryptionMethod);
context.Instance.TraceInformation("ContentType : "
+ file.ContentType);
context.Instance.TraceInformation("Filename : "
+ file.Filename);
context.Instance.TraceInformation("IsFolder : "
+ file.IsFolder);
context.Instance.TraceInformation("BodyType : "
+ context.Data.Header.BodyType);
context.Instance.TraceInformation("IsBinary : "
+ context.Data.Header.Binary);
context.Instance.TraceInformation("Actual Message :
" + context.Data.Text);
}
The output of the Trace statements that appear in the C# Code Step will appear in the Business Process Designer Trace Window as displayed below:
2/12/2020
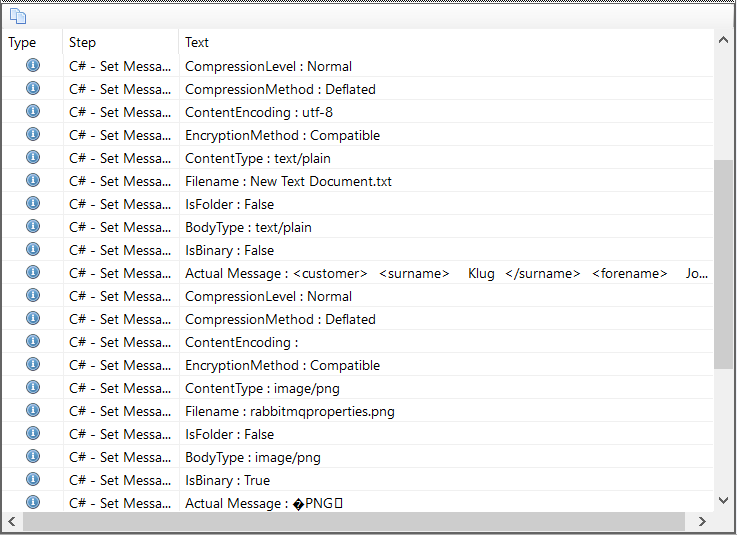
Detect Duplicates
| Category: | Message |
| Class: | DetectDuplicatesStep |
| Namespace: | Neuron.Esb.Pipelines |
| Assembly: | Neuron.Esb.Pipelines.dll |
Description:
The Detect Duplicates Process Step can identify messages previously received by a Business Process so that decisions can be made whether to receive the message again or do some other action. For example, many 3rd party applications and transports (i.e. FTP, FILE, Azure Service Bus, etc.) do not support guaranteed once only delivery of messages. However, users may need to integrate with these technologies (or similar ones) as publication sources to Neuron ESB. In those cases, the Detect Duplicates Process Step can ensure consistency and eliminate the chance of a duplicate message being processed.
The Detect Duplicates Process Step uses the Neuron ESB database to store metadata of received messages. Specifically, the Unique ID, Application Name and the time range which the message will be considered a duplicate.
To use the Process Step, the unique identifier for the message (Unique ID), the Check Window (Timespan) property and Application Name must be provided. The Unique ID can be determined at design time by providing an XPATH 1.0 statement, or developers can determine what the Unique ID should be at runtime by setting a custom Neuron ESB Message Property. The Unique ID can be any string value no longer than 200 characters.
The Check Window is a DateTime Timespan range from the current date time that the message is considered a duplicate. Usually this is set for short durations in the order of minutes. The Check Window property determines in what window of time an incoming message that matches the unique id will be considered a duplicate. For example, if the Check Window were set to 1 minute, the first incoming message would log its unique ID into the Neuron ESB database. If a second message comes in within the next minute where its unique ID matched what was in the database, it is considered a duplicate. However, if the second message came in 5 minutes after the first message, it would not. If a third message though came in within 1 minute of the second message, that message would be considered a duplicate because it came in within the 1 minute Check Window.
Post Processing
After a message is processed by the Detect Duplicates Process Step, the dupcheck.MessageFound Neuron ESB Message Property must be inspected to determine if the message is considered a duplicate. This property is populated by the Process Step and is usually used in the condition property of a Decision Process Steps Branch as shown below:
return bool.Parse(context.Data.GetProperty("dupcheck","MessageFound"));
The prefix for all Detect Duplicates custom message properties it dupcheck and they can be accessed directly from the Neuron ESB Message object using the GetProperty() or GetProperties() methods. All Neuron ESB Message properties can also be set using the Set Property Process Step.
Neuron ESB Message Properties
| Process Step | Environment | Custom Property (i.e. prefix.name) | Description |
| Detect Duplicates | Runtime/Design Time | dupcheck.UniqueId | A unique value used to identify the message and to determine is subsequent received messages have already been processed |
| Runtime | dupcheck.MessageFound | Returns true if a message that matches the UniqueID property was found to be received within the Check Window design time property. False if not found. |
Dynamic Configuration
The Detect Duplicates Step provides the Location of Unique ID (Unique ID) design time property that can be set with an XPATH 1.0 statement. This can be used if the message is embedded with its own unique identifier. However, it is more often the case where there will be multiple elements (i.e. data) within the message that must be used in combination to determine the uniqueness of a message. Alternatively, elements of the message in combination with the context or ambient properties of the endpoint receiving the message may have to be used. In those scenarios, the Unique ID can be composed within a C# Code Step and then its value set using the dupcheck.UniqueId Neuron ESB Message Property.
context.Data.SetProperty("dupcheck", "UniqueId", "some unique id");
| Process Step | Custom Property (i.e. prefix.name) | Design-time Property |
| Detect Duplicates | dupcheck.UniqueId | Directly maps to the output value of an XPATH statement provided in the Location of Unique ID property. The value passed to the dupcheck.UniqueId Is not an XPATH statement. |
Design Time Properties
| Name | Dynamic | Description |
| Name | User provided name for the Process Step. Will replace default name of Step when placed on the Design Canvas. | |
| Disable | Boolean flag to determine whether the step should be executed at runtime or design time. NOTE: Also available from the right-click context menu. | |
| Bindings | Launches the Binding Expressions dialog for specifying Environment Variables. Only the Application Name and Unique ID are bindable properties | |
| Application Name | Required. An application name used to identify the message within the duplication detection system. Cannot be longer than 50 characters. Used in combination with the Unique ID to determine the uniqueness of a message at runtime | |
| Check Window | The timespan range from the current date time which the message will be considered a duplicate | |
| Location of Unique ID | YES | Optional. An XPATH 1.0 statement that will resolve against the incoming message. The Unique ID that this resolves to cannot be greater than 200 characters. Used in combination with the Application Name to determine the uniqueness of a message at runtime. If an XPATH 1.0 statement cannot be used, the Unique ID can be generated at runtime by setting the dupcheck.UniqueId Neuron ESB Message Property. |
Sample
In the Sample below, the steps in the process demonstrate the use of the Detect Duplicates Process Step to determine if an incoming file received by the FTP adapter has previously been processed during the Check Window parameter. The FTP properties of the incoming message is used to determine the uniqueness of the file, including the original file name.
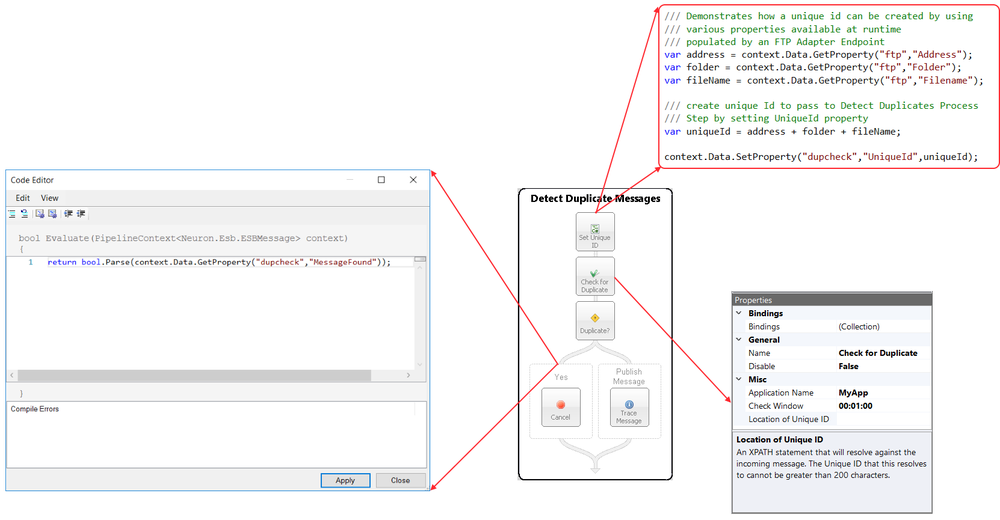
Push
| Category: | Message |
| Class: | PushContextPipelineStep |
| Namespace: | Neuron.Pipelines |
| Assembly: | Neuron.Pipelines.dll |
Description:
The Push Process Step stores a Neuron ESB Message to an internal stack, which can later be retrieved by the Pop Process Step. The Push Process Step MUST precede the Pop Process Step. When used in conjunction with one another, it provides a convenient way to preserve a message between transformation and data manipulation.
For example, a Business Process may receive a message. Within the Process, the message may be transformed, enriched or changed completely. However, at any point after message processing has taken place, it may become necessary to access the original state of the message. If the Push Process Step is the first step within the Process, then the Pop Process Step can be used to retrieve the original unprocessed message.
Internally, the storage for the saved message is a .NET Stack, persisted to the context.Properties collection using the PushedContext key. Hence, the Push Step can be used any number of times in a Process. Each Pop Process Step will take the last message placed on the Stack and restore it as the current Neuron ESB Message in the context of the Process.
Design Time Properties
| Name | Dynamic | Description |
| Name | User provided name for the Process Step. Will replace default name of Step when placed on the Design Canvas. | |
| Disable | Boolean flag to determine whether the step should be executed at runtime or design time. NOTE: Also available from the right-click context menu. | |
| Bindings | Launches the Binding Expressions dialog for specifying Environment Variables. |
Pop

| Category: | Message |
| Class: | PopContextPipelineStep |
| Namespace: | Neuron.Pipelines |
| Assembly: | Neuron.Pipelines.dll |
Description:
The Pop Process Step retrieves the last stored Neuron ESB Message from an internal stack, which was previously placed there by the Push Process Step. The Push Process Step MUST precede the Pop Process Step. When used in conjunction with one another, it provides a convenient way to preserve a message between transformation and data manipulation.
For example, a Business Process may receive a message. Within the Process, the message may be transformed, enriched or changed completely. However, at any point after message processing has taken place, it may become necessary to access the original state of the message. If the Push Process Step is the first step within the Process, then the Pop Process Step can be used to retrieve the original unprocessed message.
Internally, the storage for the saved message is a .NET Stack, persisted to the context.Properties collection using the PushedContext key. Hence, the Pop Step can be used any number of times in a Process. Each Pop Process Step will take the last message placed on the Stack and restore it as the current Neuron ESB Message in the context of the Process.
Design Time Properties
| Name | Dynamic | Description |
| Name | User provided name for the Process Step. Will replace default name of Step when placed on the Design Canvas. | |
| Disable | Boolean flag to determine whether the step should be executed at runtime or design time. NOTE: Also available from the right-click context menu. | |
| Bindings | Launches the Binding Expressions dialog for specifying Environment Variables. |
Set Property
| Category: | Message |
| Class: | EsbMessageTraceMessagePipelineStep |
| Namespace: | Neuron.Esb.Pipelines |
| Assembly: | Neuron.Esb.Pipelines.dll |
Description:
The Set Property Process Step can be used to set the value of any ESB Message header property or custom Neuron ESB Message property. This is useful to either modify the internal processing and routing behavior of a message, or add custom metadata to a message.
Most of the sub systems within Neuron ESB expose defined custom Neuron ESB Message properties that can be used to set properties at runtime, rather than relying on design time configuration. For example, the URL or method of the REST API to call may only be known after the execution of custom business logic. The FTP server or folder to send information to may not be known until runtime. Many of the Neuron ESB Business Process Steps support having some of their properties set at runtime. This is called Dynamic Configuration.
Other examples include Neuron ESB Adapters, which register their properties in form of prefix.property. Neuron ESB Service Endpoints can have their URL dynamically set at runtime by modifying custom Neuron ESB Message Properties. Lastly, all the Neuron ESB Message Header properties, like Topic, Action, etc. (with the exception of SOAP/HTTP) can be set using the Set Property Process Step.
Developers can also set the property value of Neuron ESB Message properties using either a .NET Language Code Editor (as shown below). The prefix and property names are always case sensitive.
context.Data.SetProperty("neuron", "pipelineName","MyProcess");
However, the Set Property Step does not require code, supports the use of built in variables and exposes all Neuron ESB Header properties and Adapter properties as a drop down list. For example, the picture below displays the Expression Collection Editor, showing all the available custom Neuron ESB Message properties that the Active Directory Adapter exposes (represented by the AD prefix) as well as some of the properties of the Active MQ Adapter (i.e. the activemq_in prefix):
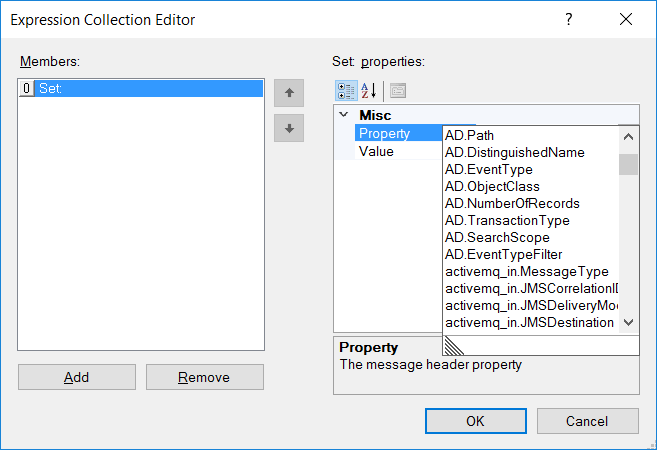
Launching the Expression Collection Editor
To launch the Expression Collection Editor, right-click on the Set Property Process Step in the Business Process Designer and select Set Properties right click context menu as shown below:
The Expression Collection Editor can also be started by double clicking on the icon with the computers mouse.
The Expression Collection Editor allows users to enter one or more property entries. Each property entry has a Property and corresponding Value property that must be populated.
Either the Property property can be selected by choosing an entry in the drop down box or, if a custom Neuron ESB Message needs to be set, the name of the property can be entered. Once the Property is set, the Value property must be entered. For this, users can again either select from the drop down list of available values or enter in a custom value. However, all custom string values MUST BE ENCLOSED in double quotes. In the example below, the custom property myPrefix.MyProperty is being set with the value of hi mom:
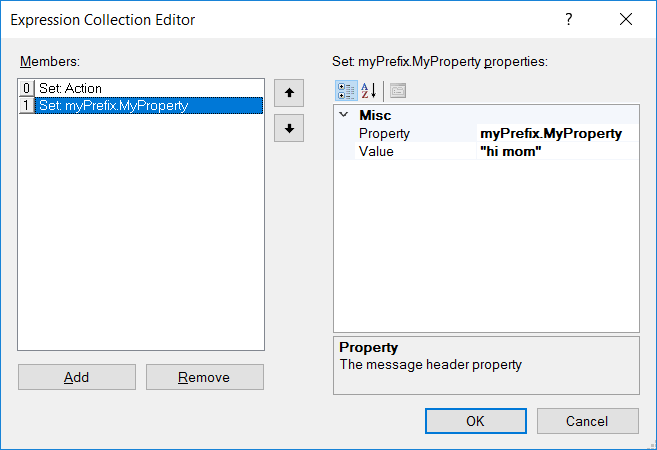
Confirmation of the property being set can be accomplished by testing within the Business Process Designer and using a C# Code Process Step to write out the value as shown below:
var myProp = context.Data.GetProperty("myPrefix","MyProperty");
context.Instance.TraceInformation(myProp);
The Set Property Process Step Value dropdown list contains the following constants which can be used and modified:
- DateTime(local) Adds the local date time value with following date time format: yyyyMMddHHmmss. A custom format specifier (e.g. https://msdn.microsoft.com/en-us/library/8kb3ddd4.aspx) can be added by appending a comma (,) followed by a custom format specifier to the existing constant (e.g. DateTime(local), M-d-yyyy h:mm:ss tt ).
- DateTime(Utc) Adds the UTC date time value with following date time format: yyyyMMddHHmmss. A custom format specifier (e.g. https://msdn.microsoft.com/en-us/library/8kb3ddd4.aspx) can be added by appending a comma (,) followed by a custom format specifier to the existing constant (e.g. DateTime(local), M-d-yyyy h:mm:ss tt ).
- IMF-fixdate Adds the RFC 7231 Date/Time Format e.g. Tue, 15 Nov 1994 08:12:31 GMT’
- GUID Adds a unique GUID string value (e.g. 00000000-0000-0000-0000-000000000000)
- JObject.<property>} Returns the property from the JSON dynamic object property from the current Neuron ESB Message. More information on usage can be found in the Accessing the Configuration section of this document as well as from Newtonsoft.
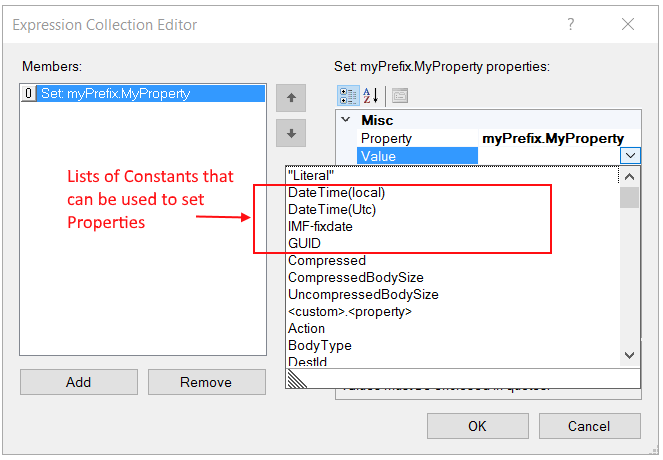
In the Example below, custom properties have been set using the constants and custom format specifiers:
In a C# Code Process Step, the values of the properties are retrieved:
var localDate = context.Data.GetProperty("myPrefix",
"MyLocalDateCustom");
var guid = context.Data.GetProperty("myPrefix","MyGUID");
var IMFdate = context.Data.GetProperty("myPrefix","MyIMFDate");
var utcDate = context.Data.GetProperty("myPrefix",
"MyUtcDateDefault");
context.Instance.TraceInformation(localDate);
context.Instance.TraceInformation(guid);
context.Instance.TraceInformation(IMFdate);
context.Instance.TraceInformation(utcDate);
Producing the following output in the Trace Window:
Design Time Properties
| Name | Dynamic | Description |
| Name | User provided name for the Process Step. Will replace default name of Step when placed on the Design Canvas. | |
| Disable | Boolean flag to determine whether the step should be executed at runtime or design time. NOTE: Also available from the right-click context menu. | |
| Bindings | Launches the Binding Expressions dialog for specifying Environment Variables. There are NO bindable properties | |
| Expressions | Required. Launches the Expression Collection Editor. Used to create a set of Property name/value pairs to set. |
Sparkplug B

| Category: | Message |
| Class: | SparkplugBProcessStep |
| Namespace: | Neuron.Esb.Pipelines.SparkplugB |
| Assembly: | Neuron.Esb.Pipelines.SparkplugB.dll |
Description:
Sparkplug™ provides an open and freely available specification for how Edge of Network (EoN) gateways or native MQTT enabled end devices and MQTT Applications communicate bi-directionally within an MQTT Infrastructure. The Sparkplug B Process Step works together with the MQTT Adapter to exchange messages with these devices. The Sparkplub B specification states that these message are sent as Google Protocol Buffers (Protobufs). For messages received from MQTT, the Sparkplug B Process Step converts the Protobufs to JSON. For messages being sent out to MQTT, it converts JSON into Protobufs.
This is a JSON representation of a Sparkplug B payload:
{
"timestamp": 1486144502122,
"metrics": [
{
"name": "Batch Status",
"alias": 1,
"timestamp": 1479123452194,
"dataType": "String",
"value": "Complete"
}
],
"seq": 2
}The Sparkplug B specification requires a specific topic namespace format for all messages. This helps define the source or target of the message, along with the message type. The format of the topic namespace is:
spBv1.0/group_id/message_type/edge_node_id/[device_id]| Message Property | Direction | Description |
| sparkplugB.Topic | In/Out | The Sparkplug B topic the message was received from or being sent to. |
| sparkplugB.Namespace | Out | The namespace portion of the Sparkplug B topic |
| sparkplugB.GroupId | Out | The group Id portion of the Sparkplug B topic |
| sparkplugB.MessageType | Out | The message type portion of the Sparkplug B topic |
| sparkplugB.EdgeNodeId | Out | The edge node Id portion of the Sparkplug B topic |
| sparkplugB.DeviceId | Out | The device Id portion of the Sparkplug B topic |
Receiving Sparkplug B Messages
When receiving a Sparkplug B messages, you will need a MQTT Adapter Endpoint for receiving the message, and a Process containing the Sparkplug B Process Step for converting the payload into JSON. The process step will also set the ESB Message property sparkplugB.Topic to the Sparkplug B topic namespace. You can retrieve the Sparkplug B Topic in a C# Process Step like this:
var topic = context.Data.GetProperty("sparkplugB", "Topic", "");A simple Process for receiving Sparkplug B messages may look like this:
Sending Sparkplug B Messages
To send Sparkplug B messages, you will first use the Sparkplug B Process Step to convert the JSON into an Google Protobuf payload, then set the topic namespace, and finally send the message using an MQTT Adapter Endpoint. A simple process for sending Sparkplug B messages might look like this:
The above process could be executed on the “On Receive” event for the MQTT Adapter Endpoint’s subscriber. You can set the topic namespace by the adding an ESB Message Property – sparkplugB.Topic. This topic will be used by the MQTT Adapter when sending the message. You can set the Sparkplug B Topic in a C# Process Step like this:
context.Data.SetProperty("sparkplugB","Topic","spBv1.0/Group/DCMD/Node/sensor11");For more information regarding Sparkplug B, see the Sparkplug Specification.
Design Time Properties
| Name | Dynamic | Description |
| Name | User provided name for the Process Step. Will replace default name of Step when placed on the Design Canvas. | |
| Disable | Boolean flag to determine whether the step should be executed at runtime or design time. NOTE: Also available from the right-click context menu. | |
| Bindings | Launches the Binding Expressions dialog for specifying Environment Variables. | |
| Convert To | Type of conversion – Google Protobuf to JSON or JSON to Google Protobuf. | |
| Message Direction | Is this message incoming from a Sparkplug B edge node or device, or outgoing to a Sparkplug B edge node or device? |
Trace
| Category: | Message |
| Class: | EsbMessageTraceMessagePipelineStep |
| Namespace: | Neuron.Esb.Pipelines |
| Assembly: | Neuron.Esb.Pipelines.dll |
Description:
The Trace Process Step is used to write the body of the Neuron ESB Message to the Business Process Designers Trace Window during testing of a Business Process. It will also write the body of the Neuron ESB Message to the Neuron ESB Log file of the endpoint in which it is hosted in at runtime.
The Trace Process Step is dependent on the Tracing level set within the Neuron ESB Explorers .config file as well as the runtime services .config file (set using the Configure Server toolbar button of the Neuron ESB Explorer. It requires that the Trace Level be set to Informational. Internally, the context.Instance.TraceInformation() API is used to write the message.
Neuron ESB Message Body Format:
The .NET UTF8 Encoder is used to translate the body of the Neuron ESB Message to text.
Design Time Properties
| Name | Dynamic | Description |
| Name | User provided name for the Process Step. Will replace default name of Step when placed on the Design Canvas. | |
| Disable | Boolean flag to determine whether the step should be executed at runtime or design time. NOTE: Also available from the right-click context menu. | |
| Bindings | Launches the Binding Expressions dialog for specifying Environment Variables. |
Security
Decrypt XML
| Category: | Security |
| Class: | EsbMessageDecryptXmlPipelineStep |
| Namespace: | Neuron.Esb.Pipelines |
| Assembly: | Neuron.Esb.Pipelines.dll |
Description:
The Decrypt XML Process Step uses the Microsoft .NET Framework standards-based, interoperable way to decrypt all or part of an XML document. The Microsoft .NET Framework implements the World Wide Web Consortium (W3C) specification for XML encryption located at https://www.w3.org/TR/xmlenc-core/. The Decrypt XML Process Step employs the AES 256 encryption standard based on the Rijndael encryption algorithm to protect sensitive data from being exposed to unauthorized parties. Use the Process Step whenever you need to share encrypted XML data between Parties, applications or organizations in a standard way.
Any Neuron ESB Message body encrypted using Encrypt XML Process Step can be decrypted by any implementation of the W3C specification for XML encryption or the Decrypt XML Process Step.
The Decrypt XML Process Step will look up the encryption key from the Neuron ESB solution. Developers may also specify a custom initialization vector that was used to enhance the security of the encrypted data. The Decrypt Xml Step will decrypt the entire XML message, or whatever fragment of the message that previously encrypted. The encryption Key and Initialization Vector property values MUST be identical to the ones used to encrypt the original data.
For example, the Neuron ESB Message body can be set with the following encrypted data:
<EncryptedData Type="https://www.w3.org/2001/04/xmlenc#Element" xmlns="https://www.w3.org/2001/04/xmlenc#"> <EncryptionMethod Algorithm="https://www.w3.org/2001/04/xmlenc#aes256-cbc"></EncryptionMethod> <CipherData> <CipherValue>AAAAAAAAAAAAAAAAAAAAAFFKI/HgrMyMXQeXc+sYDkAJKDD69Vczbnmbp0J7uXohz+v/vfKnZwGHye1GMNtCfWYO6fZgHu1PynnmrTJ2eH6laLN7Gh04GouSP6N1EZt1Iux7Sm27NzEoGKvFcomI6xw60aNWXwy7x6mFz297f9lu3PrdThsO6DYygFBJjojMoqqBSF+s3HdmNYkFIu+7Si/BzUzHYirriRUNtmt/yhDi+l3FYcWUFRcdcy9on0foZ25hdbqQJknhrW1PdVJaN6EHzNneOibeS/EJcQ1HhfAesoCEyyBYmke4AxqoYrsHMHm49gsm/M+SCQpUF1nEEuXgqCgTOyb1TSu44vFGW9HT3PfxB/8rLogrQ1RBDqh9HewXpKCa02d91mhmPg7np+h9a/4HbAcoNjUXq63CrIoS1MQg0yqWrD4wrP3xU61hF2k1sj9xLBYhClqgkX4DPkm3OnQBmyNH83/2Qo5w/wtKl9l5PMhslWxNvBZfXLJD4+KVSYuh4KvnA8VUifDHlg==</CipherValue> </CipherData> </EncryptedData>
By setting the encryption Key and Initialization Vector properties to those used to encrypt the data, the Decrypt XML Process Step will produce the output below:
<ProcessPayment xmlns="https://tempuri.org/"> <request xmlns:d4p1="https://schemas.datacontract.org/2004/07/PaymentService" xmlns:i="https://www.w3.org/2001/XMLSchema-instance"> <d4p1:PaymentProcessRequest> <d4p1:Amount>5</d4p1:Amount> <d4p1:OrderId>9e98d6fb-d1be-40f6-abf7-6a0417d7e449</d4p1:OrderId> </d4p1:PaymentProcessRequest> </request> </ProcessPayment>
Design Time Properties
| Name | Dynamic | Description |
| Name | User provided name for the Process Step. Will replace default name of Step when placed on the Design Canvas. | |
| Disable | Boolean flag to determine whether the step should be executed at runtime or design time. NOTE: Also available from the right-click context menu. | |
| Bindings | Launches the Binding Expressions dialog for specifying Environment Variables. | |
| Initialization Vector | Optional. The initialization vector that was used to encrypt the data. If provided it MUST be the same 32-character hexadecimal number used in the Encryption Step. | |
| Key | Required. The name of the key to use to decrypt the XML element. Only AES 256 keys will be available. This is a dropdown box populated by Keys located in the Security (Encryption -> Keys) section of the Neuron ESB Solution. |
Encrypt XML
| Category: | Security |
| Class: | EsbMessageEncryptXmlPipelineStep |
| Namespace: | Neuron.Esb.Pipelines |
| Assembly: | Neuron.Esb.Pipelines.dll |
Description:
The Encrypt XML Process Step uses the Microsoft .NET Framework standards-based, interoperable way to encrypt all or part of an XML document. The Microsoft .NET Framework implements the World Wide Web Consortium (W3C) specification for XML encryption located at https://www.w3.org/TR/xmlenc-core/. The Encrypt XML Process Step employs the AES 256 encryption standard based on the Rijndael encryption algorithm to protect sensitive data from being exposed to unauthorized parties. Use the Process Step whenever you need to share encrypted XML data between Parties, applications or organizations in a standard way.
Any Neuron ESB Message body encrypted using this Process Step can be decrypted by any implementation of the W3C specification for XML encryption or by the Decrypt XML Process Step. XML encryption replaces any plain text XML element or document with the <EncryptedData> element, which contains an encrypted (or cipher text) representation of plain text XML or any arbitrary data. The <EncryptedData> element also contains information about which cryptographic algorithm was used to encrypt the plain text.
The Encrypt Xml Process Step will look up the encryption key from the Neuron ESB solution. Developers may also specify a custom initialization vector that will be used to enhance the security of the encrypted data. Using the Encrypt Xml Step, it is possible either to encrypt the entire XML message, or to encrypt a fragment of the message specifying using an XPATH 1.0 expression.
For example, the Neuron ESB Message body can be set with the following XML Sample document:
<ProcessPayment xmlns="https://tempuri.org/"> <request xmlns:d4p1="https://schemas.datacontract.org/2004/07/PaymentService" xmlns:i="https://www.w3.org/2001/XMLSchema-instance"> <d4p1:PaymentProcessRequest> <d4p1:Amount>5</d4p1:Amount> <d4p1:OrderId>9e98d6fb-d1be-40f6-abf7-6a0417d7e449</d4p1:OrderId> </d4p1:PaymentProcessRequest> </request> </ProcessPayment>
Using the /* XPATH 1.0 statement to populate the Element To Encrypt property, the body of the Neuron ESB Message will be replaced with the following:
<EncryptedData Type="https://www.w3.org/2001/04/xmlenc#Element" xmlns="https://www.w3.org/2001/04/xmlenc#"> <EncryptionMethod Algorithm="https://www.w3.org/2001/04/xmlenc#aes256-cbc"></EncryptionMethod> <CipherData> <CipherValue>AAAAAAAAAAAAAAAAAAAAAFFKI/HgrMyMXQeXc+sYDkAJKDD69Vczbnmbp0J7uXohz+v/vfKnZwGHye1GMNtCfWYO6fZgHu1PynnmrTJ2eH6laLN7Gh04GouSP6N1EZt1Iux7Sm27NzEoGKvFcomI6xw60aNWXwy7x6mFz297f9lu3PrdThsO6DYygFBJjojMoqqBSF+s3HdmNYkFIu+7Si/BzUzHYirriRUNtmt/yhDi+l3FYcWUFRcdcy9on0foZ25hdbqQJknhrW1PdVJaN6EHzNneOibeS/EJcQ1HhfAesoCEyyBYmke4AxqoYrsHMHm49gsm/M+SCQpUF1nEEuXgqCgTOyb1TSu44vFGW9HT3PfxB/8rLogrQ1RBDqh9HewXpKCa02d91mhmPg7np+h9a/4HbAcoNjUXq63CrIoS1MQg0yqWrD4wrP3xU61hF2k1sj9xLBYhClqgkX4DPkm3OnQBmyNH83/2Qo5w/wtKl9l5PMhslWxNvBZfXLJD4+KVSYuh4KvnA8VUifDHlg==</CipherValue> </CipherData> </EncryptedData>
In contrast, the /*/*/*[local-name(.) = ‘PaymentProcessRequest’] XPATH 1.0 statement can be used to ensure only the PaymentProcessRequest node of the XML document is encrypted rather than the entire document as shown below:
<ProcessPayment xmlns="https://tempuri.org/"> <request xmlns:d4p1="https://schemas.datacontract.org/2004/07/PaymentService" xmlns:i="https://www.w3.org/2001/XMLSchema-instance"> <EncryptedData Type="https://www.w3.org/2001/04/xmlenc#Element" xmlns="https://www.w3.org/2001/04/xmlenc#"> <EncryptionMethod Algorithm="https://www.w3.org/2001/04/xmlenc#aes256-cbc"></EncryptionMethod> <CipherData> <CipherValue>AAAAAAAAAAAAAAAAAAAAAFO12CzK0fDAAY/CNC8Hlfwt+msp2o1ux9f7hqsgGxQ6IMBeYjWUzaPi6jnh3A+m2jInMUA+01xj69QdCK4mERIOaA7Q/wGOIlKyNjW8d6Jn/tflhquV0ouy/FiuPVf2iZWoEEzj8yycAsQlfeSeaZqrJZUOr1wgWTEYpE62b3stSW3u53jsp1U3tu/xRpjhH0adWcfaAiGs9t+lPOjk5wdKxkGe5I5Ou1il9T4WU+jgSD1Su+tXk1Vb0gFoplVzKqhRfmpwf/g1MFf8lNRh95hbVRpvsjm2Z8ob2jc/FJ87NeT1K5hgSpSF7xkkrED31w==</CipherValue> </CipherData> </EncryptedData> </request> </ProcessPayment>
Design Time Properties
| Name | Dynamic | Description |
| Name | User provided name for the Process Step. Will replace default name of Step when placed on the Design Canvas. | |
| Disable | Boolean flag to determine whether the step should be executed at runtime or design time. NOTE: Also available from the right-click context menu. | |
| Bindings | Launches the Binding Expressions dialog for specifying Environment Variables. | |
| Initialization Vector | Optional. The initialization vector to use to encrypt the XML content. If provided it MUST be a 32-character hexadecimal number. | |
| Element To Encrypt | Required. An XPATH 1.0 expression that will select the XML element to encrypt. | |
| Encrypt Content | Default is False. Set to True to encrypt only the content of the element, but not the actual XML element. | |
| Key | Required. The name of the key to use to encrypt the XML element. Only AES keys will be available. This is a dropdown box populated by Keys located in the Security (Encryption -> Keys) section of the Neuron ESB Solution. |
OAuth

| Category: | Security |
| Class: | OAuthProcessStep |
| Namespace: | Neuron.Esb.Pipelines.OAuth |
| Assembly: | Neuron.Esb.Pipelines.OAuth.dll |
Description:
The OAuth Process Step provides the ability for a developer to retrieve an OAuth token within a business process.
Unlike most process steps, the OAuth Process Step does not modify the input ESB Message, except for a few message properties. This step has one optional message property that can be set on the input message. It then sets two or three message properties on the original Input ESB Message and returns it as the output message.
| Message Property | Direction | Description |
| oauth.refresh | In | An optional Boolean value indicating if the access token needs to be refreshed. Set to true if you’ve received a token and is fails validation. This will force a new access token to be retrieved. |
| oauth.accessToken | Out | This will contain the access token retrieved from the OAuth provider. |
| oauth.expiresOn | Out | When the access token is retrieved, if the ExpiresOn property was returned, this will contain the DateTime when the access token expires. |
| oauth.authHeader | Out | This will contain the entire authorization header, including the access token. |
To use this step you must create an OAuth Provider under Security-OAuth Providers. Then drag the OAuth Process Step onto the Process design surface and select the OAuth provider you just created. If using the retrieved OAuth token with a Service Connector, you will need to either use the Http Client Utility Process Step or a C# Step to set the authorization header value.
When using the Http Client Utility Process Step, you can just set the Authorization header to {#oauth.authHeader}. This message property is already correctly formatted with the credential type included:
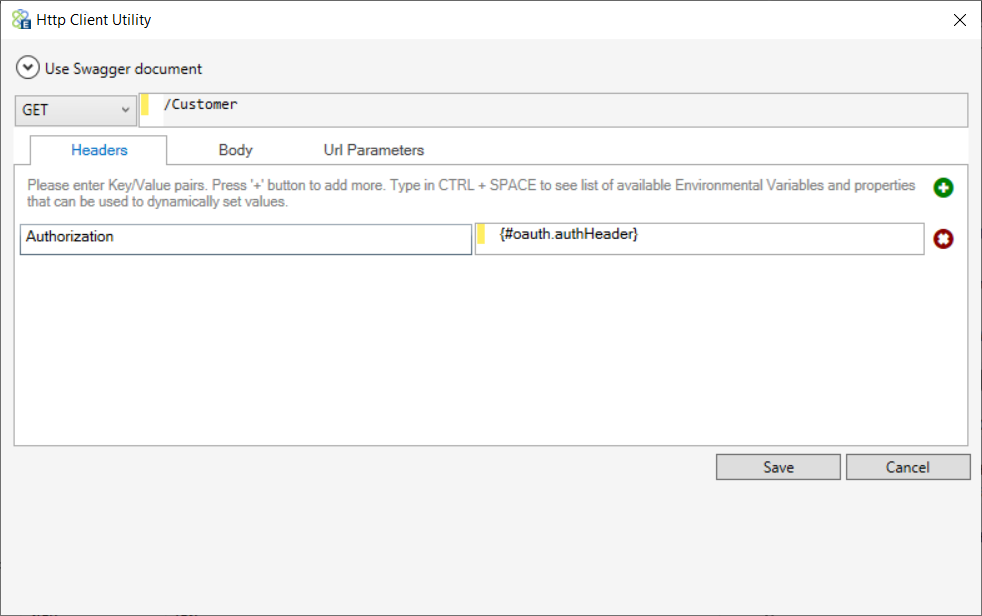
When using the OAuth Process Step, you do not need to configure the Service Connector to use the OAuth Provider – you are already handling it in the Process. Because you are handling it in the process, you should also consider failure scenario where the token might be expired, requiring you to request a new one.
Design Time Properties
| Name | Dynamic | Description |
| Name | User provided name for the Process Step. Will replace default name of Step when placed on the Design Canvas. | |
| Disable | Boolean flag to determine whether the step should be executed at runtime or design time. NOTE: Also available from the right-click context menu. | |
| Bindings | Launches the Binding Expressions dialog for specifying Environment Variables. | |
| OAuth Provider | The name of the OAuth Provider to use for retrieving an access token. |
Sign XML
| Category: | Security |
| Class: | EsbMessageSignXmlPipelineStep |
| Namespace: | Neuron.Esb.Pipelines |
| Assembly: | Neuron.Esb.Pipelines.dll |
Description:
The Sign XML Process Step uses the .NET Framework implementation of the World Wide Web Consortium (W3C) XML Signature Syntax and Processing Specification, also known as XMLDSIG (XML Digital Signature). XMLDSIG is a standards-based, interoperable way to sign and verify all or part of an XML document. Use the Sign XML Process Step whenever you need to share signed XML data between Parties, applications or organizations in a standard way. Any Neuron ESB Message body signed using this Process Step can be verified by any conforming implementation of the W3C specification for XMLDSIG or by using the Verify Signed XML Process Step.
The Sign XML Process Step uses X.509v3 certificates stored in the Windows certificate store and configured in the Security section of the Neuron ESB configuration to sign the XML message. The Sign XML Process Step requires the presence of a private key attached to the certificate in the certificate store. Using the private key, the Sign XML Process Step will use the XML Signature standard to calculate the cryptographically secure signature for the message and will add the signature to the XML body of the message.
XMLDSIG creates a <Signature> element, which contains a digital signature of an XML document. The <Signature> element contains information about which cryptographic algorithm was used for signing. For example, the Neuron ESB Message body can be set with the following XML Sample document:
<ProcessPayment xmlns="https://tempuri.org/"> <request xmlns:d4p1="https://schemas.datacontract.org/2004/07/PaymentService" xmlns:i="https://www.w3.org/2001/XMLSchema-instance"> <d4p1:PaymentProcessRequest> <d4p1:Amount>5</d4p1:Amount> <d4p1:OrderId>9e98d6fb-d1be-40f6-abf7-6a0417d7e449</d4p1:OrderId> </d4p1:PaymentProcessRequest> </request> </ProcessPayment>
Once an appropriate Certificate is selected, the Sign XML Process Step will output the following:
<ProcessPayment xmlns="https://tempuri.org/"> <request xmlns:d4p1="https://schemas.datacontract.org/2004/07/PaymentService" xmlns:i="https://www.w3.org/2001/XMLSchema-instance"> <d4p1:PaymentProcessRequest> <d4p1:Amount>5</d4p1:Amount> <d4p1:OrderId>9e98d6fb-d1be-40f6-abf7-6a0417d7e449</d4p1:OrderId> </d4p1:PaymentProcessRequest> </request> <Signature xmlns="https://www.w3.org/2000/09/xmldsig#"> <SignedInfo> <CanonicalizationMethod Algorithm="https://www.w3.org/TR/2001/REC-xml-c14n-20010315"></CanonicalizationMethod> <SignatureMethod Algorithm="https://www.w3.org/2000/09/xmldsig#rsa-sha1"></SignatureMethod> <Reference> <Transforms> <Transform Algorithm="https://www.w3.org/2000/09/xmldsig#enveloped-signature"></Transform> </Transforms> <DigestMethod Algorithm="https://www.w3.org/2000/09/xmldsig#sha1"></DigestMethod> <DigestValue>i/IcSANTRaTtG87rUppQOZG/nqU=</DigestValue> </Reference> </SignedInfo> <SignatureValue>y5S4Oyfk3GmKr7EKgcSg82iDUukXkCdGn1nt+NN5w8HR3CIqhjIi4AI3qSG80gcWWusmz3tfW69U38AxSip54Ff1CLNwWCVlrmKjv+knozFBQlE/d6ND0ilfpqy9qQQ5Fc2LduscA9JkSjNsmsdpBXtyysTzH9Prl479kCen52ODmXe+/jFocVKrg3ckvQ87Mv1uCQFplwAhbPF0sxooj2r0hmDfmQ1nn/AA1jE1FXdXpaYq62Zawd6Wfgyc87TfpavrWQ9Zo6bcpvUsB07VkmvWjo2M7NRoHSbaumLvQ+RBb/Lziuorn7O96dWCwiJuuWSR+/A/KXWXSfMVEPW9ZQ==</SignatureValue> </Signature> </ProcessPayment>
Design Time Properties
| Name | Dynamic | Description |
| Name | User provided name for the Process Step. Will replace default name of Step when placed on the Design Canvas. | |
| Disable | Boolean flag to determine whether the step should be executed at runtime or design time. NOTE: Also available from the right-click context menu. | |
| Bindings | Launches the Binding Expressions dialog for specifying Environment Variables. | |
| Certificate | Required. The X.509 certificate to use to sign the XML. This is a dropdown box populated by Certificates located in the Security (Authentication -> Credential) section of the Neuron ESB Solution. |
Verify Signed XML
| Category: | Security |
| Class: | EsbMessageVerifySignedXmlPipelineStep |
| Namespace: | Neuron.Esb.Pipelines |
| Assembly: | Neuron.Esb.Pipelines.dll |
Description:
The Verify Signed XML Process Step uses the .NET Framework implementation of the World Wide Web Consortium (W3C) XML Signature Syntax and Processing Specification, also known as XMLDSIG (XML Digital Signature). XMLDSIG is a standards-based, interoperable way to sign and verify all or part of an XML document. Use the Verify Signed XML Process Step whenever you need to share signed XML data between Parties, applications or organizations in a standard way. Any Neuron ESB Message body signed using the Sign XML Process Step can be verified by any conforming implementation of the W3C specification for XMLDSIG or by using this Process Step
The Verify Signed XML Process Step uses the public key associated with a configured X.509v3 certificate to verify that the signature attached to an XML message is valid and was signed by the private key associated with the public key that is used to verify the messages signature. The Verify Signed XML Process Step uses X.509v3 certificates stored in the Windows certificate store and configured in the Security section of the Neuron ESB configuration to verify the XML message.
For example, if the Neuron ESB Message body is set with the following signed XML Message:
<ProcessPayment xmlns="https://tempuri.org/"> <request xmlns:d4p1="https://schemas.datacontract.org/2004/07/PaymentService" xmlns:i="https://www.w3.org/2001/XMLSchema-instance"> <d4p1:PaymentProcessRequest> <d4p1:Amount>5</d4p1:Amount> <d4p1:OrderId>9e98d6fb-d1be-40f6-abf7-6a0417d7e449</d4p1:OrderId> </d4p1:PaymentProcessRequest> </request> <Signature xmlns="https://www.w3.org/2000/09/xmldsig#"> <SignedInfo> <CanonicalizationMethod Algorithm="https://www.w3.org/TR/2001/REC-xml-c14n-20010315"></CanonicalizationMethod> <SignatureMethod Algorithm="https://www.w3.org/2000/09/xmldsig#rsa-sha1"></SignatureMethod> <Reference> <Transforms> <Transform Algorithm="https://www.w3.org/2000/09/xmldsig#enveloped-signature"></Transform> </Transforms> <DigestMethod Algorithm="https://www.w3.org/2000/09/xmldsig#sha1"></DigestMethod> <DigestValue>i/IcSANTRaTtG87rUppQOZG/nqU=</DigestValue> </Reference> </SignedInfo> <SignatureValue>y5S4Oyfk3GmKr7EKgcSg82iDUukXkCdGn1nt+NN5w8HR3CIqhjIi4AI3qSG80gcWWusmz3tfW69U38AxSip54Ff1CLNwWCVlrmKjv+knozFBQlE/d6ND0ilfpqy9qQQ5Fc2LduscA9JkSjNsmsdpBXtyysTzH9Prl479kCen52ODmXe+/jFocVKrg3ckvQ87Mv1uCQFplwAhbPF0sxooj2r0hmDfmQ1nn/AA1jE1FXdXpaYq62Zawd6Wfgyc87TfpavrWQ9Zo6bcpvUsB07VkmvWjo2M7NRoHSbaumLvQ+RBb/Lziuorn7O96dWCwiJuuWSR+/A/KXWXSfMVEPW9ZQ==</SignatureValue> </Signature> </ProcessPayment>
If an appropriate Certificate is selected (the same used to sign the message), the Verify Signed XML Process Step will output the exact same message. However, if the message fails validation, the following exception will be thrown:
Neuron.Pipelines.PipelineException: The XML signature could not be verified.
Design Time Properties
| Name | Dynamic | Description |
| Name | User provided name for the Process Step. Will replace default name of Step when placed on the Design Canvas. | |
| Disable | Boolean flag to determine whether the step should be executed at runtime or design time. NOTE: Also available from the right-click context menu. | |
| Bindings | Launches the Binding Expressions dialog for specifying Environment Variables. | |
| Certificate | Required. The X.509 certificate to use to verify the XML. This is a dropdown box populated by Certificates located in the Security (Authentication -> Credential) section of the Neuron ESB Solution. |
Services
Adapter Endpoint
| Category: | Services |
| Class: | ExecuteAdapterPipelineStep |
| Namespace: | Neuron.Esb.Pipelines |
| Assembly: | Neuron.Esb.Pipelines.dll |
Description:
A core feature of Application and Data Integration servers is their ability to bridge and abstract third party applications, databases, technologies, protocols or transports. Neuron ESB provides this through either its library of built in adapters and by allowing users to build their own adapters using the Neuron ESB Adapter Framework. In many ways, Adapters provide capabilities similar to those found in Neuron ESBs Service Broker specifically:
- Bridging external endpoints
- Functioning as subscribers
Just as with Service Connectors, Adapter Endpoints would normally need to be invoked through the Neuron ESB Messaging system where a message is published to a Topic and then routed to eligible subscribers, one of which could be an Adapter Endpoint as shown below:
However, the Adapter Endpoint Process Step can be used with the Business Process Designer to circumvent the Messaging system. The Process Step allows a user to directly call any Adapter Endpoint that exists in the Neuron ESB Configuration (e.g. Connections -> Endpoints -> Adapter Endpoints within the Neuron ESB Explorer), without the need to publish a Neuron ESB Message to a Topic, eliminating all pub/sub overhead:
This allows users to create Business Processes that define an end-to-end solution without the pub/sub abstraction in the middle. The immediate advantage is:
- Reduced Latency:
The cost of correlating messaging traffic over a Topic is eliminated. - Increased Performance:
For request/reply type calls, intermediate pub/sub is eliminated. - Reduction of Resources:
The Adapter Endpoint does NOT have to be Enabled to be use. Which means a new app domain with dedicated resources will not be created by the Neuron ESB service runtime.
When to Use:
Generally, the process step should always be used with any request/response type of request against the Adapter Endpoint since there will never be more than one subscribing endpoint fulfilling the request and essentially, it would be always be a blocking call within the Business Process. For fire-and-forget messaging (i.e. multicast/datagram), unless there is a need to decouple using the topic-based pub/sub engine as in the case where the publishing process should not know who the subscribing endpoints/parties are, then using the process step would be a preferred approach. However, the Business Process would incur more increased latency since it would now inherit the amount of time it takes an Adapter Endpoint to complete its execution. Only Subscribe side Adapters can be executed by the Adapter Endpoint Process Step.
For example, the Adapter Endpoint Process Step can be used in the Neuron ESB Business Process designer to create real-time service composition solutions by aggregating existing services and application endpoints into more innovative business capabilities that can be accessed throughout an organization (displayed below). The advantage of the Adapter Endpoint Process Step is that it can eliminate much of the overhead traditionally seen when a bus or other messaging architectures are incorporated in service composition solutions where request/response type of message patterns are predominately employed.
context.Data.Header.Service = “FileAdapterEndpointOut”;
Performance Optimizations
The Adapter Endpoint Process Step uses a Blocking pool of Adapter Endpoints to allow better scale out for concurrency and to eliminate all calls being serialized through one instance of an Adapter Endpoint. There are two properties located in the Pool Management property category. Maximum Instances (defaults to 100) and Pool Timeout (defaults to 1 minute). Once the maximum number of Adapter Endpoint instances have been created, the Pool Timeout determines the amount of time to wait for an existing Adapter Endpoint instance to become available before throwing a timeout exception.
Before an Adapter Endpoint instance is created, the pool is always checked to see if one already exists. If it does, it retrieves is from the pool and uses it. When complete, the instance is returned to the pool. The Maximum Instances property does NOT define the number of Adapter Endpoint instances that will always be created at runtime in all circumstances. It only defines the maximum number that could be created. For instance, Business Processes attached to most inbound Adapter Endpoints (Publish mode) will generally only create one pooled instance of an Adapter Endpoint as many of the adapters only work with one inbound thread at a time (unless receiving messages from Topics). However, a Client Connector (Neuron ESB hosted service endpoint) could be dealing with many more threads representing concurrent users making service calls.
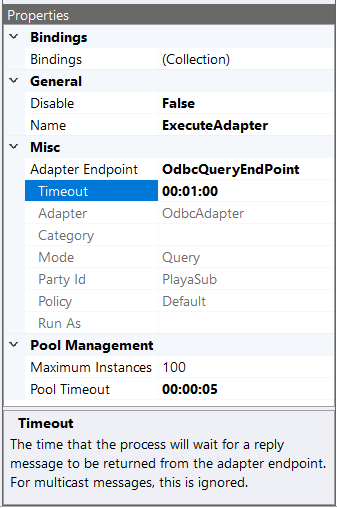
Design Time Properties
| Name | Dynamic | Description |
| Name | User provided name for the Process Step. Will replace default name of Step when placed on the Design Canvas. | |
| Disable | Boolean flag to determine whether the step should be executed at runtime or design time. NOTE: Also available from the right-click context menu. | |
| Bindings | Launches the Binding Expressions dialog for specifying Environment Variables. | |
| Adapter Endpoint | Required. Drop down list populated by all Subscribe type Adapter Endpoints that exists in the Neuron ESB Configuration (e.g. Connections -> Endpoints -> Adapter Endpoints within the Neuron ESB Explorer). Adapter Endpoints do NOT need to be enabled to be listed and used at runtime. | |
| Timeout | Required. The time (specified as a Timespan) that the Business Process would wait for a reply message to be returned from the Adapter Endpoint. For multicast messages, this is ignored. Default is 1 minute. | |
| Maximum Instances | Required. Defines the maximum of number of Adapter Endpoint instances that will be created and cached in a concurrent pool. Each thread of execution retrieves an Adpater Endpoint instance from the pool. After execution, the Adapter Endpoint instance is returned to the pool. If the maximum number of Adapter Endpoint instances has already been created, the execution thread will wait for the specified period configured for the Pool Timeout property for another Adapter Endpoint instance to become available. Default Value is 100. | |
| Pool Timeout | Required. The period a thread may wait for an Adapter Endpoint Instance to become available to be retrieved from the pool If the maximum number of pooled instances has already been reached. A timeout exception will be thrown if the Pool Timeout period is exceeded. Default Value is 1 minute. |
Data Mapper
| Category: | Services |
| Class: | DataMapperPipelineStep |
| Namespace: | Neuron.Pipelines |
| Assembly: | Neuron.Pipelines.dll |
Description
Data Mapper Pipeline step allows applying a Data Map to the ESB message in the pipeline context. Data Map is a new type of entity added in the Neuron ESB 3.7.5 release.
In this step, you can use an existing Data Map from the repository or you can create a new map from within the Process Designer.
Double clicking this step after adding it to the Process, opens up the Data Map designer shown below.
You can select a schema/document for source and target in this designer. You can then connect the source fields to target fields with WYSIWIG mapping. You can also add transformations to the mapping. There are a number of other features such as use of Environment Variables and Custom Properties. You can also set the Data Mapper at runtime using the custom property with prefix neuron and name as DataMapperName. The value of this custom property can specify the name of existing Data Map in the solution.
There is a built in testing function also that allows you to verify the mapping.
For understanding of Data Map, refer to the Neuron ESB 3.7.5 Features Update and the Data Mapper Documentation Links.
Design Time Properties
| Name | Dynamic | Description |
| Name | User provided name for the Process Step. Will replace default name of Step when placed on the Design Canvas. | |
| Disable | Boolean flag to determine whether the step should be executed at runtime or design time. NOTE: Also available from the right-click context menu. | |
| Bindings | Launches the Binding Expressions dialog for specifying Environment Variables. | |
| Data Mapper Name | Yes | You can select an existing Data Mapper Name from the Repository. If you created new one from within the designer, it will get saved in the repository and the name will appear here. |
| Include Xml Declaration | Specifies if Output should include the XML Declaration as the first line. Default value True |
Http Client Utility

| Category: | Services |
| Class: | RestPipelineStep |
| Namespace: | Neuron.Pipelines |
| Assembly: | Neuron.Pipelines.dll |
Description:
Neuron ESB includes a Service Broker that enables organizations to deploy Neuron ESB as a Service Gateway, providing mediation, security, hosting and a number of other services. Service Connectors are essentially registrations within Neuron ESB that point to existing services hosted within an organization, by a partner or in a cloud domain. These services, which can be either SOAP or REST (HTTP) based, can be called either through the Neuron ESB messaging system via a Topic subscription or by using a Service Endpoint Process Step. The latter can be used with the existing Business Process Designer and allows a user to directly call any Service Connector without the need to publish a request to a Topic, eliminating all pub/sub overhead. These are commonly used to create service aggregation and composition solutions.
For calling REST (HTTP) based Service Connectors (endpoints), it is common that various pieces of information need to be provided at runtime according to the REST specification. For example, the Method name (e.g. GET, POST, PUT, PATCH, etc.) must be provided. HTTP Headers usually need to be provided (e.g. Content Type, Authorization, Accept, etc.) as well as Query string or URL parameters. This information can be provided by using a C# Code Editor within the Business Process Designer directly preceding the Service Endpoint activity as depicted below:
Opening the C# Code Editor allows developers to provide the information they need to initialize the service call at runtime by primarily using the HTTP API of the Neuron ESB Message as shown below.
The information used to initialize these HTTP elements can come from the Neuron ESB Message or context properties or even Neuron ESB Environmental Variables that may have different values at runtime depending on the runtime environment they are deployed to. The example below shows how Query string parameters could be set in a Code Editor in the Neuron ESB Workflow Designer.
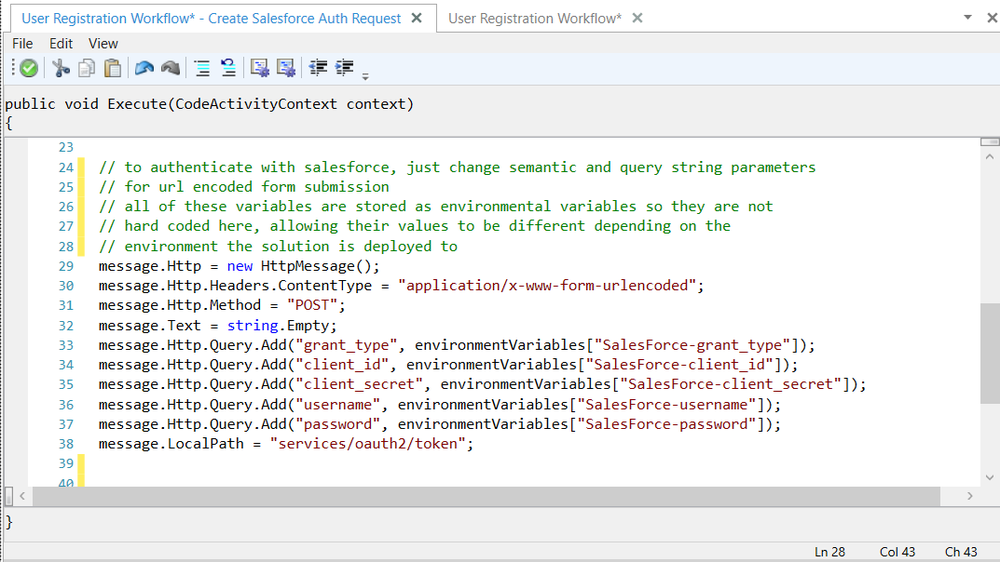
Launching the Http Client Utility
Alternatively, rather than using C# to set HTTP properties, the Http Client Utility Editor can be used within a Business Process to do advanced levels of HTTP configuration. To launch the Http Client Utility Editor, right-click on the Http Client Utility Process Step in the Business Process Designer and select Configure right click context menu as shown below:
The Http Client Utility Editor can also be started by double clicking on the icon with the computers mouse as displayed below:
For users familiar with tools like Postman and the REST client of Chrome, the Http Client Utility Editor will look very similar and they will find it just as easy to configure. The Http Client Utility Editor has built in intelligence and allows the use of Neuron ESB Environmental Variables, Neuron ESB Message properties, Context properties and literal values to configure any Value, Message body or URL as shown below:
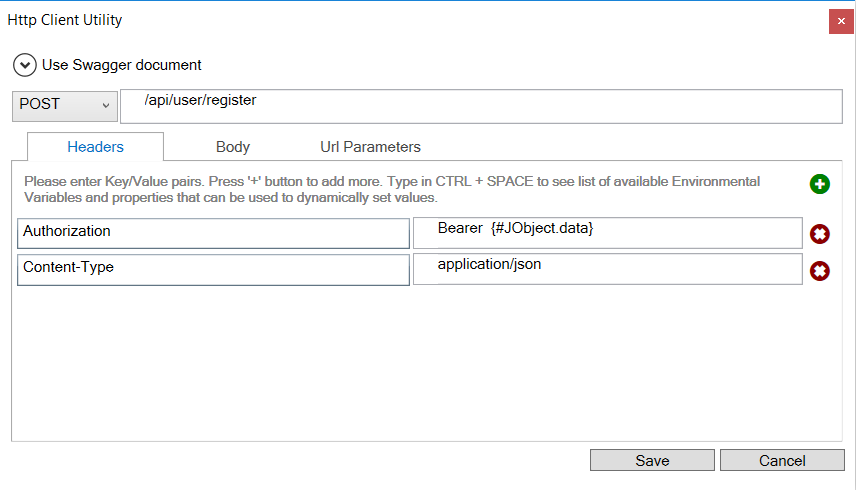
Valid HTTP Header options and methods are displayed as drop down boxes, while possible values for the selected HTTP Header key also appear as context sensitive drop downs.
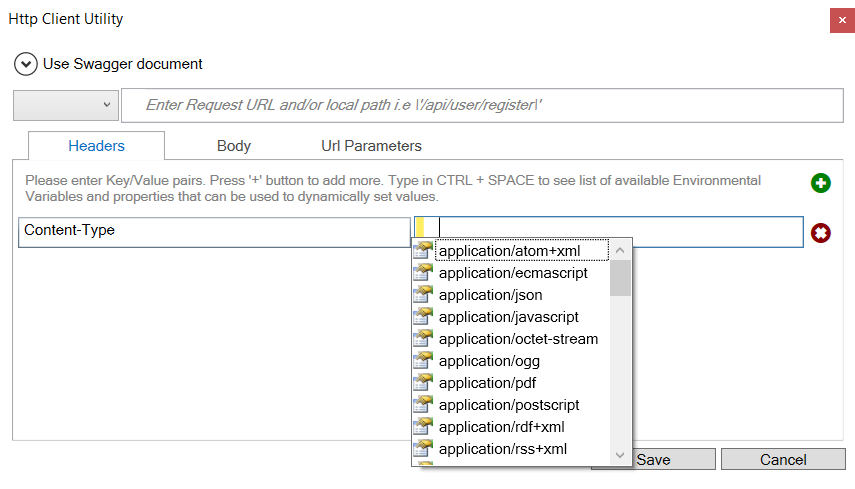
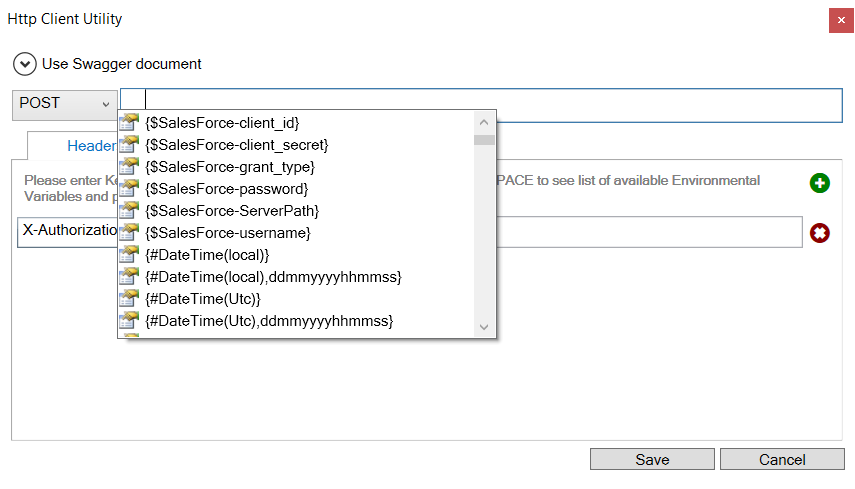
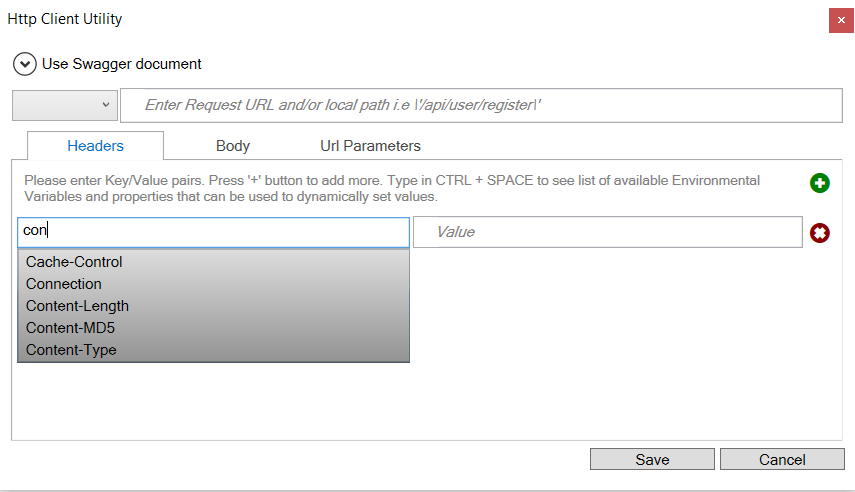
Alternatively, Neuron ESB Environmental Variables, properties (context, message, etc.), message body and literals can be used by selecting from the available list. Environmental variables are preceded by the $, whereas all others are preceded by # as shown below.
The literal values that appear in the list (i.e. by pressing CTRL + SPACE) that can be used are:
- {#DateTime(local)} – Adds the local date time value with following format: “yyyyMMddHHmmss”.
- {#DateTime(local), ddmmyyyyhhmmss } – Adds the local date time value using the provided format specifier. A custom format specifier (e.g. https://msdn.microsoft.com/en-us/library/8kb3ddd4.aspx) can be provided by replacing the existing format specifier (ddmmyyyyhhmmss).
- {#DateTime(Utc)} – Adds the UTC date time value with following format: “yyyyMMddHHmmss”.
- {#DateTime(Utc),ddmmyyyyhhmmss} – Adds the UTC date time value using the provided format specifier. A custom format specifier (e.g. https://msdn.microsoft.com/en-us/library/8kb3ddd4.aspx) can be provided by replacing the existing format specifier (ddmmyyyyhhmmss).
- {#IMF-fixdate} Adds the RFC 7231 Date/Time Format e.g. ‘Tue, 15 Nov 1994 08:12:31 GMT'”
- {#GUID} Adds a unique GUID string value (e.g. 00000000-0000-0000-0000-000000000000)
Values that can be used to access either some part of the body or a custom message property of the ESB Message are:
- {#<custom>.<property>} Returns custom message property e.g. context.data.GetProperty(myPrefix, MyProperty)
- {#JObject.<property>} Returns the property from the JSON dynamic object property from the current Neuron ESB Message. More information on usage can be found in the Accessing the Configuration section of this document as well as from Newtonsoft.
Besides the Method drop down box and the URL text box, the Http Client Utility Editor has three primary tabs: Headers, Body and URL Parameters. The Headers tab allows users to specify any HTTP or custom key/value pairs that will appear as HTTP Headers in the final REST service call. A good example of an HTTP Header could be either the Content Type or the Authorization header. The Body tab allows users to specify how the body should be encoded and sent to the service as shown below:
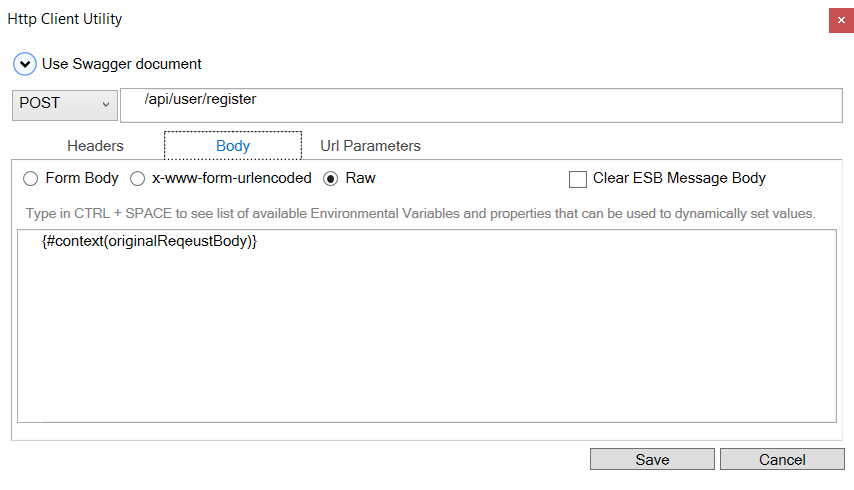
Using the settings, Neuron ESB will ensure the proper HTTP Content Type and data are appropriately set and encoded if necessary. Users have additional options like clearing out the underlying Neuron ESB Message body if either Form Body or Form Url Encoded options are chosen.
The URL Parameters tab allows users to enter key/value pairs that will be serialized as URL parameters for the service call. The Http Client Utility Editor eliminates the need for developers to use C# to set the required HTTP properties for any service call. In the example below, a Salesforce authentication call is made where all the values are using Neuron ESB Environmental Variables, allowing the values to be specific to the actual runtime environment the solution is deployed to:
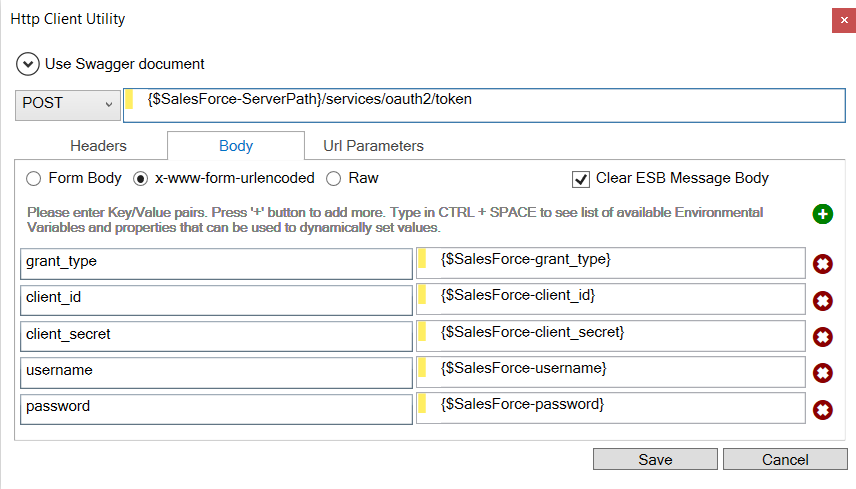
Swagger Integration
The Http Client Utility Editor can be auto configured by selecting Swagger, a common documentation format for REST (HTTP) based services, from the drop down list. For example, Neuron ESB ships a Marketo adapter, which is accompanied by its respective Swagger documentation. The Marketo Swagger documentation, as well as any Swagger document registered within the new Neuron ESB Swagger Repository, can be accessed directly within the Use Swagger document section of the Http Client Utility Editor.
Swagger documents can be imported in the Neuron ESB Swagger Repository by navigating to Repository->Service Descriptions->Swagger Documents within the Neuron Explorer.
By expanding the Use Swagger document section, the Document and Operations dropdown fields will be visible and populated using existing Swagger documents in the Repository. These can be selected to auto configure the Http Client Utility Editor. If a Swagger document does not exist, one can be imported directly within the UI by selecting the Import Swagger option from the Document dropdown and providing the URL of the Swagger document.
Design Time Properties
| Name | Dynamic | Description |
| Name | User provided name for the Process Step. Will replace default name of Step when placed on the Design Canvas. | |
| Disable | Boolean flag to determine whether the step should be executed at runtime or design time.
NOTE: Also available from the right-click context menu.
| |
| Bindings | Launches the Binding Expressions dialog for specifying Environment Variables. There are NO bindable properties | |
| Configure | Required. Launches the Http Client Utility Editor. Used to set all HTTP related properties and message body for REST API calls. |
Publish

| Category: | Services |
| Class: | EsbMessagePublishPipelineStep |
| Namespace: | Neuron.Esb.Pipelines |
| Assembly: | Neuron.Esb.Pipelines.dll |
Description:
The Publish Process Step uses the context of the Neuron ESB Party that the Business Process is associated with to publish the incoming message to a specified Topic. The Publish Process Step provides direct integration to the Neuron ESB Messaging system. When the Publish Step runs in the context of Parties, (attached to a Party configured in an Endpoint) it uses the Party it is attached to and that Partys subscriptions and authorizations will be applied.
Topics can also be set dynamically by using the built in C# Code Editor within the Publish Process Step. For instance, it may be necessary to inspect the content of the message to determine which Topic to publish the message. Using the C# Code Editor, C# can be used to inspect the message, or call external services, code or logic to return the correct Topic.
Design Time Testing
When testing the Publish Process Step in the Process Designer, the user must supply the Source ID (name of the Party) in the Edit Test Message dialog. Both Party and Topic to route to must exist in the opened solution and the open solution MUST be running in the local Neuron ESB Service runtime. More information can be found in the Testing Live Process Steps section of this documentation.
Design Time Properties
| Name | Dynamic | Description |
| Name | User provided name for the Process Step. Will replace default name of Step when placed on the Design Canvas. | |
| Disable | Boolean flag to determine whether the step should be executed at runtime or design time. NOTE: Also available from the right-click context menu. | |
| Bindings | Launches the Binding Expressions dialog for specifying Environment Variables. | |
| Selector Type | Required. Default is Constant. One of two drop down values can be selected;ConstantorCode. The value selected controls the options for theTopicSelectorproperty. | |
| TopicSelector | YES | Required. TopicSelector must be expanded to show the child properties, eitherTopic(whenConstant SelectorType is chosen) or Code (whenCodeSelectorType is chosen) can be selected. The child property displayed is determined by theSelectorTypeproperty. WhereSelectorType = Constant: A list of all Topics and sub Topics will be displayed in a drop down box. One must be chosen. WhereSelectorType = Code: This contains an ellipsis button. When clicked, a C# Code Editor will be displayed. Any expression using C# can be entered as long as it returns the name of a valid Topic. The Publish Process Step requires that the Party, which calls the Process, be authorized to publish on the selected the Topic. |
| Semantic | Required. Default is Multicast. Contains all values for the Neuron.Esb.Semantic enumeration (e.g. Multicast, Request, Reply, Direct, and Routed. Depending on the semantic chosen, additional ESB Message header properties may have to be set. Please refer to the API documentation. | |
| Request-Reply Timeout | Optional. Default is 60 seconds. This property is only required and visible IF the Semantic property is set to Request. |
Rules Engine
| Category: | Services |
| Class: | EsbMessageRulesPipelineStep |
| Namespace: | Neuron.Esb.Pipelines |
| Assembly: | Neuron.Esb.Pipelines.dll |
Description:
The Rules Engine Process Step uses the Microsoft .NET Workflow Rules Engine. Rules can be defined based on any Neuron ESB Message property, body content or the Business Process context.
The .NET Workflow Rules Engine can be used to modify the Neuron ESB Message body and its properties as well as the Business Process Context. The current Neuron ESB Business Process Context and Neuron ESB Message can be accessed within the Rule Set Editor by referencing this. in the Rule Set editing text boxes for Conditions and Actions.
Launching the Rules Set Editor
To launch the Rule Set Editor, right-click on the Rules Engine Process Step in the Business Process Designer and select Rule Set Editor right click context menu as shown below:
The Rule Set Editor can also be started by double clicking on the icon with the computers mouse, displayed below:
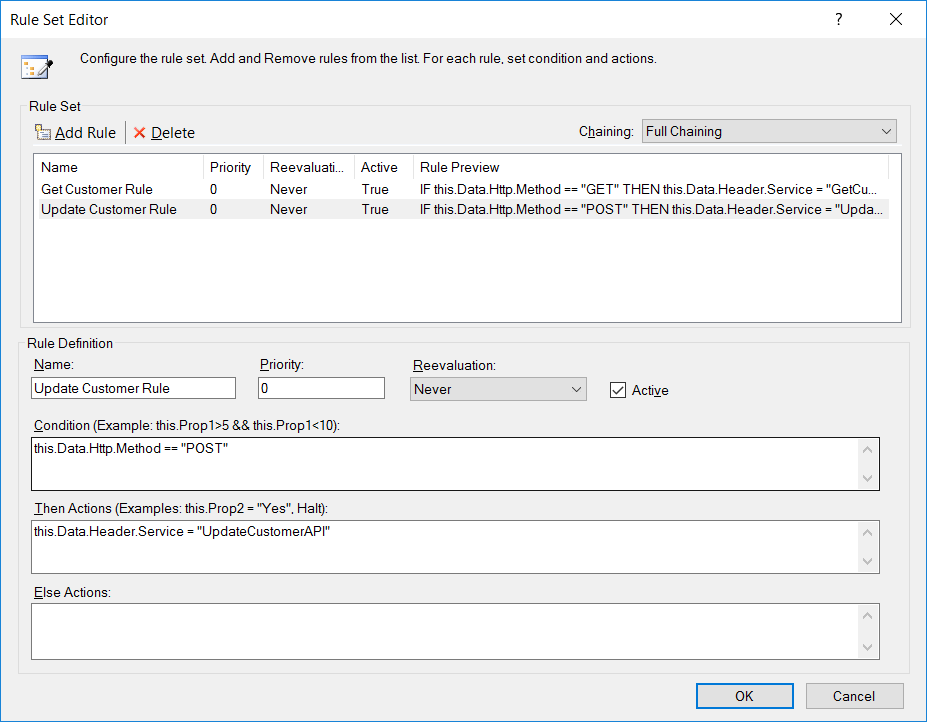
All objects from the Business Process Context are available to be referenced within the Rule Set Editor text boxes. Shown below is an example of setting Neuron ESB Message Properties to values retrieved from the current Neuron ESB Message Body (e.g. SelectSingleNode()) and Environment Variables collection:
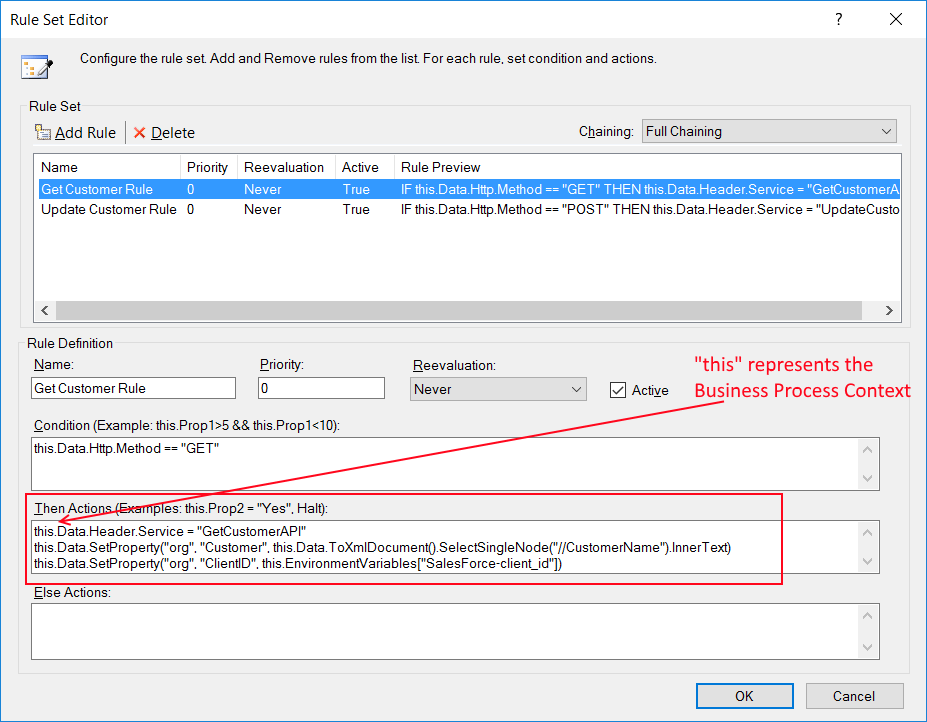
Once a Rule Set has been created, it is saved and serialized as part of the Business Process.
More information regarding the .NET Windows Workflow Rules Engine can be found here: https://msdn.microsoft.com/en-us/library/dd554919.aspx
Design Time Properties
| Name | Dynamic | Description |
| Name | User provided name for the Process Step. Will replace default name of Step when placed on the Design Canvas. | |
| Disable | Boolean flag to determine whether the step should be executed at runtime or design time. NOTE: Also available from the right-click context menu. | |
| Bindings | Launches the Binding Expressions dialog for specifying Environment Variables. | |
| Rule Set Editor | Required. Launches the Rule Set Editor. |
Service
| Category: | Services |
| Class: | EsbMessageCallWebServicePipelineStep |
| Namespace: | Neuron.Esb.Pipelines |
| Assembly: | Neuron.Esb.Pipelines.dll |
The Service Process Step can be used to call a Web Service. To configure, drag the Service Process Step onto a Business Process, right click the step to display the short cut menu, and select Select Endpoint from the menu. This will display the Select Endpoint Dialog box in the figure below.
In the Select Endpoint dialog, enter the URL to the WSDL of the service in the URL text box, then click the Load button. This will populate the Services and Operations list boxes. Once populated, select the services endpoint and associated operation, and click the OK button. This will populate the following Service Pipeline Step properties:
- MetadataUrl
- Action
- EndpointName
- ServiceName
If metadata (WSDL) is not available, the Service Process step can be configured manually by entering values for the following properties:
- BindingName
- BindingConfigurationName
- EndpointBehaviorName
- ServiceUrl
The first three properties must be configured within the *.config file of whatever application will be hosting and executing the process.This is determined by where the Business Process associated Party is running.For example, if the Business Process is configured for a Party, which in turn is associated with a Service Connector, Client Connector or Neuron ESB Adapter, then the configuration file for the Neuron ESB Service must be edited to include the properties.The name of the configuration file is esbService.exe.config and can be found in the root of the Neuron ESB installation directory.
Metadata Exchange Endpoints
The Service Process Steps supports WSDL extensions as well as WCF Metadata Exchange Endpoints. If using the Select Endpoint wizard (displayed above), if an endpoint is entered without either a WSDL or Metadata Exchange Endpoint (e.g. mex), WSDL will be assumed and that extension will be automatically entered for the user. If a WSDL or Metadata Exchange Endpoint is not found, an error will be displayed to the user. Lastly, the Service Process Step can still be manually configured to call any WCF or non-WCF service endpoint using its associated property grid. This allows service calls to be made without have to retrieve and parse the Metadata for each call.
Design Time Properties
| Name | Dynamic | Description |
| Name | User provided name for the Process Step. Will replace default name of Step when placed on the Design Canvas. | |
| Disable | Boolean flag to determine whether the step should be executed at runtime or design time. NOTE: Also available from the right-click context menu. | |
| Bindings | Launches the Binding Expressions dialog for specifying Environment Variables. | |
| IsOneWay | Required: Dropdown selection of True or False specifying whether the Message Exchange Pattern will be one way or request/response. Default is False. | |
| RestoreHeaders | Required: Dropdown selection of True of False specifying whether to restore the ESBMessage custom properties as SOAP message headers. Default is False. | |
| BindingName | Only required if not using WSDL (i.e. MetadataUrl): | |
| BindingConfigurationName | Only required if not using WSDL (i.e. MetadataUrl): | |
| EndpointBehaviorName | Only required if not using WSDL (i.e. MetadataUrl): | |
| Credentials | Optional: Username for accessing service | |
| Password | Optional: Password for accessing service | |
| MetadataUrl | Optional: The metadata address of the web service. | |
| Transactional | Required: Boolean value: Either True or False to allow Transaction Flow. The service must be configured properly to support flow of transactions. If it is configured properly, this will also work with the Transaction shape. | |
| ServiceName | Required: The name of the web service. | |
| EndpointName | Required: The name of the communication endpoint of the service as defined in the services WSDL. | |
| Action | Required: Specifies the SOAP Action for the outgoing message. If none is specified then the value of the Action property of the current ESB Message in the process will be used. | |
| Timeout | Required: Communication timeout when waiting for a reply from the service. The value is expressed in hours, minutes, and seconds as hh:mm:ss. Default is 1 minute. | |
| ServiceUrl | Only required if not using WSDL (i.e. MetadataUrl): |
Service Endpoint
| Category: | Services |
| Class: | EsbMessageServiceEndpointPipelineStep |
| Namespace: | Neuron.Esb.Pipelines |
| Assembly: | Neuron.Esb.Pipelines.dll |
Description:
Neuron ESB includes a Service Broker that enables organizations to deploy Neuron ESB as a Service Gateway, providing mediation, security, hosting and a number of other services. Service Connectors are essentially registrations within Neuron ESB that point to existing services hosted within an organization, partner or cloud domain. Some of Neuron ESBs Service Broker capabilities include:
- Bridging external endpoints
- Services functioning as subscribers
Normally a Service Connector (externally hosted service registered with Neuron ESB) receives request messages through the Neuron ESB Messaging system. Request messages are published to a Topic and then routed to eligible subscribers, one of which could be a Service Endpoint (e.g. Service Connector) as shown below:
However, the Service Endpoint Process Step can be used with the Business Process Designer to circumvent the Messaging system. The Process Step allows a user to directly call any Service Connector that exists in the Neuron ESB Configuration (e.g. Connections -> Endpoints -> Service Endpoints within the Neuron ESB Explorer), without the need to publish a Neuron ESB Message to a Topic, eliminating all pub/sub overhead:
This allows users to create Business Processes that define an end-to-end solution without the pub/sub abstraction in the middle. The immediate advantage is:
- Reduced Latency:
The cost of correlating messaging traffic over a Topic is eliminated.
- Increased Performance
For request/reply type calls, intermediate pub/sub is eliminated.
- Reduction of Resources:
The Service Endpoint does NOT have to be Enabled to be use (the Service Connector must be enabled though). Which means a new app domain with dedicated resources will not be created by the Neuron ESB service runtime.
When to Use:
Generally, the process step should always be used with any request/response type of request against the Service Endpoint (e.g. Service Connector) since there will never be more than one subscribing endpoint fulfilling the request and essentially, it would be always be a blocking call within the Business Process. For fire-and-forget messaging (i.e. multicast/datagram), unless there is a need to decouple using the topic-based pub/sub engine as in the case where the publishing process should not know who the subscribing endpoints/parties are, then using the process step would be a preferred approach. However, the Business Process would incur more increased latency since it would now inherit the amount of time it takes a Service Endpoint to complete its execution. Only Service Connectors can be executed by the Service Endpoint Process Step.
For example, the Service Endpoint Process Step can be used in the Neuron ESB Business Process designer to create real-time service composition solutions by aggregating existing services and application endpoints into more innovative business capabilities that can be accessed throughout an organization (displayed below). The advantage of the Service Endpoint Process Step is that it can eliminate much of the overhead traditionally seen when a bus or other messaging architectures are incorporated in service composition solutions where request/response type of message patterns are predominately employed.
Dynamic Configuration
In some scenarios, developers may need to declare which Service Connector or URL to use at runtime, rather than relying on design time configuration. For example, during the course of execution, the logic in the Business Process could be used to determine the Service Connector to call, or the URL. If relying on design time configuration, a Decision Process Step could be used, with each Branch configured to run a Service Endpoint Step, each configured with a different Service Connector. This will work but would become impractical if it required more than half dozen or so branches. Alternatively, dynamically configuring the Service Endpoint property or the URL of the Service Connector at runtime, a Decision Process Step would not be needed. Only one Service Endpoint Process Step would be used. Directly preceding the Execute Process Step could be a Set Property Process Step or a Code Step. If a Code Step was used, the following custom properties and/or header property could be used:
context.Data.SetProperty("Addressing",
"To","https://www.mysite/customer");
context.Data.Header.Service = "MyServiceConnector";
The Addressing.To property can be used to dynamically configure the URL of the existing configured Service Connector at runtime. This is useful if more than one service can use the exact same options as configured in the Service Connector being called. In contrast, the Service property of the Neuron ESB Message Header is used to direct the Service Endpoint Process Step, which Service Connector should be called at runtime, effectively making the Service Endpoint name property dynamic.
The Addressing.To property can be accessed directly from the Neuron ESB Message object using the GetProperty() or GetProperties() methods. All Neuron ESB Message properties can also be set using the Set Property Process Step.
| Process Step | Custom Property (i.e. prefix.name) | Design-time Property |
| Service Endpoint | ESBMessage.Header.Service | Service Endpoint |
| Addressing.To | N/A |
Performance Optimizations
The Service Endpoint Process Step uses a Blocking pool of Service Endpoints to allow better scale out for concurrency and to eliminate all calls being serialized through one instance of a Service Endpoint. There are two properties located in the Pool Management property category. Maximum Instances (defaults to 100) and Pool Timeout (defaults to 1 minute). Once the maximum number of Service Endpoints instances have been created, the Pool Timeout determines the amount of time to wait for an existing Service Endpoint instance to become available before throwing a timeout exception.
Before a Service Endpoint instance is created, the pool is always checked to see if one already exists. If it does, it retrieves is from the pool and uses it. When complete, the instance is returned to the pool. The Maximum Instances property does NOT define the number of Service Endpoint instances that will always be created at runtime in all circumstances. It only defines the maximum number that could be created. For instance, Business Processes attached to most inbound Adapter Endpoints (Publish mode) will generally only create one pooled instance of an Service Endpoint as many of the adapters only work with one inbound thread at a time (unless receiving messages from Topics). However, a Client Connector (Neuron ESB hosted service endpoint) could be dealing with many more threads representing concurrent users making service calls.
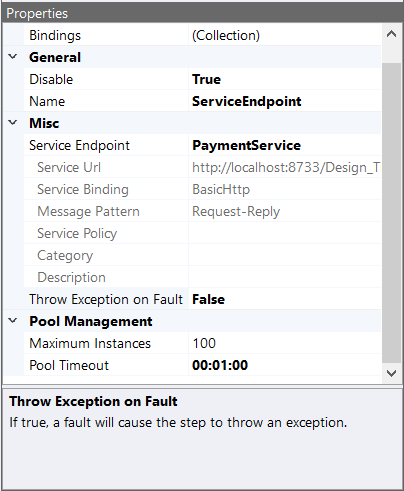
Design Time Properties
| Name | Dynamic | Description |
| Name | User provided name for the Process Step. Will replace default name of Step when placed on the Design Canvas. | |
| Disable | Boolean flag to determine whether the step should be executed at runtime or design time. NOTE: Also available from the right-click context menu. | |
| Bindings | Launches the Binding Expressions dialog for specifying Environment Variables. | |
| Service Endpoint | YES | Required. Drop down list populated by all Subscribe type Service Endpoints (e.g. Service Connectors) that exists in the Neuron ESB Configuration (e.g. Connections -> Endpoints -> Service Endpoints within the Neuron ESB Explorer). Service Endpoints do NOT need to be enabled to be listed and used at runtime. |
| Throw Exception on Fault | Required. Default is False. If set to True, an exception will be thrown if the Service Endpoint receives a Service Fault from the target service. | |
| Maximum Instances | Required. Defines the maximum of number of Service Endpoint instances that will be created and cached in a concurrent pool. Each thread of execution retrieves a Service Endpoint instance from the pool. After execution, the Service Endpoint instance is returned to the pool. If the maximum number of Service Endpoint instances has already been created, the execution thread will wait for the specified period configured for the Pool Timeout property for another Service Endpoint instance to become available. Default Value is 100. | |
| Pool Timeout | Required. The period a thread may wait for a Service Endpoint Instance to become available to be retrieved from the pool If the maximum number of pooled instances has already been reached. A timeout exception will be thrown if the Pool Timeout period is exceeded. Default Value is 1 minute. |
Storage
Lookup Table

| Category: | Storage |
| Class: | LookupTableProcessStep |
| Namespace: | Neuron.Esb.Pipelines.LookupTable |
| Assembly: | Neuron.Esb.Pipelines.LookupTable.dll |
Description:
The Lookup Table Process Step provides a means to perform key-value lookups from a database table. These lookups are intended to be simple in nature – provide a key and get a value in return. For example, you can map the internal ID of an Account in Salesforce to a Customer in NetSuite. Then, whenever the Salesforce account is updated, you won’t need to make a call to NetSuite to find the ID. You can use the Lookup Table Process Step instead.
The key-value pairs in the lookup table are further identified by a category. This allows the user to keep multiple types of key-value pairs in the same table, with no worry of having duplicate keys for different types of lookup data.
The lookup table can be populated in one of two ways – either by prepopulating it outside of a Neuron integration (i.e. a batch script or something similar), or by managing the table in real time using the Add, Update, Upsert and Delete lookup operations available in the process step.
Unlike most process steps, the Lookup Table Process Step does not modify the input ESB Message, except for a few message properties. This step expects one or two message properties, depending on the operation, to be set on the input message. It then sets two or three message properties on the original Input ESB Message and returns it as the output message.
| Message Property | Direction | Description |
| lookup.key | In | The key used when performing the requested operation. |
| lookup.value | In/Out | For the Lookup operation, this is the value returned from the lookup. For Add, Update and Upsert, this is the value being added or updated in the lookup table. |
| lookup.success | Out | A Boolean value indicating if the operation was successful. |
| lookup.errorDetails | Out | If the operation was not successful, this will contain the error details of why it failed. |
The lookup table has only three columns – Category, Id and Value. The primary key for this table contains both the Category and Id. The Category is configured as a propery in the process step’s property grid. The Id (key) is set as a message property. The Lookup, Add, Update, Upsert and Delete operations are executed against the primary key. Only the Clean operation is executed against just the Category column.
Lookup
The lookup operation returns a value based on the lookup key. It requires the input message property lookup.key prior to be set prior to calling this step. If the key is found, the message property lookup.value will be returned with the results of the lookup.
Set the lookup key in C# code:
context.Data.SetProperty("lookup", "key", "myKey");Retrieve the lookup value in C# code:
var myValue = context.Data.GetProperty("lookup", "value");If the lookup operation fails, the message properties lookup.success will equal false and you can find the error details in the lookup property lookup.errorDetails.
Add
The Add operation adds a key-value pair to the lookup table. It requires the message properties lookup.key and lookup.value to be set prior to the calling this step. If the add operation is successful, lookup.success will be set to true. If it fails. Lookup.success will be set to false and lookup.errorDetails will contain additional information regarding the failure (i.e. duplicate key).
Update
The Update operation modifies an existing key-value pair with a new value. It requires the message properties lookup.key and lookup.value to be set prior to the calling this step. If the update operation is successful, lookup.success will be set to true. If it fails. Lookup.success will be set to false and lookup.errorDetails will contain additional information regarding the failure (i.e. key not found).
Upsert
The Upsert operation is a combination of the Add and Update operations. It first checks to see if the key exists. If the key does not exist, it adds the key-value pair. If the key does exist, it updates the existing key-value pair. It requires the message properties lookup.key and lookup.value to be set prior to the calling this step. If the upsert operation is successful, lookup.success will be set to true. If it fails. Lookup.success will be set to false and lookup.errorDetails will contain additional information regarding the failure (i.e. database connection error).
Delete
The Delete operation will remove a key-value pair from the database. It requires the message property lookup.key to be set prior to the calling this step. If the delete operation is successful, lookup.success will be set to true. If it fails. Lookup.success will be set to false and lookup.errorDetails will contain additional information regarding the failure (i.e. key not found).
Clean
The Clean operation will remove all key-value pairs from the lookup table that match the Category entered in the Lookup Table Process Step’s property grid. It does not require any input message properties. Use this step with caution – it will remove all entries for the selected category. If the clean operation is successful, lookup.success will be set to true. If it fails. Lookup.success will be set to false and lookup.errorDetails will contain additional information regarding the failure (i.e. database connection error).
Design Time Properties
| Name | Dynamic | Description |
| Name | User provided name for the Process Step. Will replace default name of Step when placed on the Design Canvas. | |
| Disable | Boolean flag to determine whether the step should be executed at runtime or design time. NOTE: Also available from the right-click context menu. | |
| Bindings | Launches the Binding Expressions dialog for specifying Environment Variables. | |
| Connection String | Required. The ODBC connection string to use for communicating with the database. The ellipsis button will launch the Connection String Builder UI. You can select the Neuron ESB database or one of your own. | |
| Connection Timeout | Required. The number of seconds required for the connection attempt to timeout. Default is 15 seconds. | |
| Command Timeout | Required. The number of seconds required for the Command execution to timeout. Default is 30 seconds. | |
| Lookup Table | Required. The table containing the key-value pairs. The Neuron ESB database includes a table that can be used as a lookup table, called KeyValueLookup. You can also provide your own table in a separate database. | |
| Lookup Operation | Required. Select one of Lookup, Add, Update, Upsert, Delete or Clean. | |
| Category | Required. The category of the key-value pair. |
Creating Your Own Lookup Table
You can create your own lookup table and host it in your own instance of SQL Server.
To create the lookup table:
CREATE TABLE [dbo].[KeyValueLookup](
[Category] [nvarchar](50) NOT NULL,
[Id] [nvarchar](200) NOT NULL,
[Value] [nvarchar](max) NOT NULL,
CONSTRAINT [PK_KeyValueLookup] PRIMARY KEY CLUSTERED
(
[Category] ASC,
[Id] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON, OPTIMIZE_FOR_SEQUENTIAL_KEY = OFF) ON [PRIMARY]
) ON [PRIMARY] TEXTIMAGE_ON [PRIMARY]
The account used to access the table (i.e. ESB Service Account) needs to be granted the following permissions to the table:
- Select
- Update
- Insert
- Delete
MSMQ
| Category: | Storage |
| Class: | EsbMessageMsmqPipelineStep |
| Namespace: | Neuron.Esb.Pipelines |
| Assembly: | Neuron.Esb.Pipelines.dll |
Description:
The MSMQ Process is used to send messages to or receive messages from an MSMQ Queue. The MSMQ Process step has similar capabilities as the Neuron ESB MSMQ Adapter except that the MSMQ Process Step supports correlated Sends and Receives. At minimum the following three properties need to be configured to use the step:
- Queue Path
- Transactional
- Direction
Queue Path
The Queue Path property represents the location and name of the Queue (i.e. path name or FormatName) to send or receive messages from.
For example, to send to the OrderQueue located on the local machine with a NETBIOS name of Martywaz01, acceptable queue paths are:
- .\private$\orderqueue
- FormatName:Direct=OS:martywaz01\private$\orderqueue
Transactional
For transactional messaging, the Microsoft Distributed Transaction Coordinator (MSDTC) service must be configured and running when reading from and writing to transactional queues.
When the Transactional property is set to Requires or RequiresNew, the message is read from the queue in a transaction. This requires that the MSMQ queue be a transactional queue.
If the Transactional property is set and the queue is not a transactional queue, then the Process Step will not be able to retrieve messages from the queue or send messages to the queue. Remote transactional reads are only supported on MSMQ 4.0 and above which is shipped with Windows 2008, Vista and later operating systems. A remote transactional read is one where the queue is not on the same machine as the Neuron ESB server. When sending and receiving to remote transactional queues, the MSDTC must be configured for secure network access on all machines involved in the transaction.
If RequiresNew is selected, a new Transaction will be created for the Process Step operation. However, if Requires is selected, an attempt will be made to enlist in the underlying ambient transaction (e.g. System.Transactions.Transaction.Current != null).
For local transactional queues, the Process Step will check the transactional property of the queue before sending messages to the queue. If the queue is not transactional, and the Transactional property is set to Requires or RequiresNew, an exception will be thrown. However, there is no ability to check the transactional property of a remote queue. If the Process Step sends a message to a non-transactional queue with the Transactional property set, the send will silently fails. The developer must ensure the type of queue the message is being sent to matches the properties set.
Operation
The Operation property is used to indicate what operation the Process Step should execute:
- Send
- Read
- Peek
Sending Messages
The Send operation indicates that the body of the Neuron ESB message will be sent to the queue specified in the Queue Path Property. The BodyStream property of MSMQ message will be set to the byte array of the Neuron ESB Message. If any custom Neuron ESB Message properties exist (prefix of msmq listed in the table below), their values will be copied to the respective properties of the MSMQ message. The exact Neuron ESB Message properties copied are determined by the value of the Extended Properties property value. If set to true, all MSMQ Message properties are copied to the new MSMQ message. If false, only Correlation Id (if Correlate property is set to true), AppSpecific, Label and Priority are copied. After the message body has been sent to the MSMQ queue, the MSMQ Message ID as well as the Correlation Id (provided the Correlate property was set to true) are copied to the existing Neuron ESB Message as custom message properties (with prefix of msmq).
Reading Messages
The Read operation will attempt to read a message from the MSMQ Queue, for the duration of the timespan value set for the Timeout property. This is essentially a WAIT operation. If Correlate is set to true and a Correlation ID is provided, the ReceiveByCorrelationId() method of the MSMQ queue will be used to ensure that only messages with the given Correlation Id will be retrieved. If a message is found, its retrieved and the following happens:
- A new Neuron ESB Message is created with a new Message ID, its body set to the BodyStream of the MSMQ Message.
- The Neuron ESB Message Headers Priority property is set to the MSMQ Messages Priority property
- The appropriate encoder is obtained to translate the byte stream depending on the value of the Use ActiveXMessageFormatter property
- Either all or a subset of the MSMQ Message properties are copied to the new Neuron ESB Message as custom properties (prefix of msmq).
- The msmq.ReceivedMessage custom Neuron ESB Message property is set to true.
If no message is found after the Timeout period, the msmq.ReceivedMessage custom Neuron ESB Message property is added to the existing Neuron ESB Message and is set to false.
Peek a Message
The Peek Operation is similar to the Read except that it does NOT remove the message from the Queue. It only determines if a message exists on the queue or if Correlate is set to true, determines if a message with a specific Correlation Id exists on the queue. If a message is found on a queue, the following happens:
- Either all or a subset of the MSMQ Message properties are copied to the existing Neuron ESB Message as custom properties (prefix of msmq).
- The msmq.ReceivedMessage custom Neuron ESB Message property is added to the existing Neuron ESB Message and is set to true.
If no message is found after the Timeout period, the msmq.ReceivedMessage custom Neuron ESB Message property is added to the existing Neuron ESB Message and is set to false.
Correlation
Correlation can be used to ensure that random messages are not read from a Queue. Using a Correlation ID, the Process Step can be directed to only read those MSMQ messages whose Correlation Id properties are set with the Correlation Id value provided either at design time (property grid) or runtime (e.g. msmq.CorrelationId).
To enable correlation, the Correlate property of the Process Step must be set to true. If true, the Correlation Id property will be visible and can be set in the property grid. The Correlation Id must conform to the format specified by MSMQ, which is essentially a GUID and 7-digit number separated by a backslash (e.g. \).
More about Correlation Ids can be found here:
https://msdn.microsoft.com/en-us/library/ms703979(v=vs.85).aspx
Requirements
This MSMQ Process requires that the Microsoft Message Queue (MSMQ) server Windows feature be installed. The MSMQ Active Directory Domain Services Integration sub feature is required only if sending or receiving to Public queues.
Post Processing
After either a Read or Peek operation, the msmq.ReceivedMessage Neuron ESB Message Property can be inspected to determine if the Process Step either retrieved or found a message on the Queue. This property is populated by the Process Step and is usually used in the condition property of a Decision Process Steps Branch as shown below:
return bool.Parse(context.Data.GetProperty("msmq",
"ReceivedMessage"));
The prefix for all MSMQ custom message properties it msmq and they can be accessed directly from the Neuron ESB Message object using the GetProperty() or GetProperties() methods. All Neuron ESB Message properties can also be set using the Set Property Process Step.
https://msdn.microsoft.com/en-us/library/ms705286(v=vs.85).aspx
Neuron ESB Message Properties
| Process Step | Direction | Custom Property (i.e. prefix.name) | Properties Enabled | Description |
| MSMQ | Send/Receive | msmq.CorrelationId | NO | Required if the Correlate design time property is set to True |
| Send/Receive | msmq.AppSpecific | NO | MSMQ Header Property | |
| Send/Receive | msmq.Label | NO | MSMQ Header Property | |
| Send/Receive | msmq.Priority | NO | MSMQ Header Property | |
| Send/Receive | msmq.Id | NO | MSMQ Header Property | |
| Send/Receive | msmq.AcknowledgeType | YES | MSMQ Header Property | |
| Send/Receive | msmq.AttachSenderId | YES | MSMQ Header Property | |
| Send/Receive | msmq.Recoverable | YES | MSMQ Header Property | |
| Send/Receive | msmq.TimeToBeReceived | YES | MSMQ Header Property | |
| Send/Receive | msmq.TimeToReachQueue | YES | MSMQ Header Property | |
| Send/Receive | msmq.UseDeadLetterQueue | YES | MSMQ Header Property | |
| Send/Receive | msmq.UseEncryption | YES | MSMQ Header Property | |
| Send/Receive | msmq.UseJournalQueue | YES | MSMQ Header Property | |
| Send/Receive | msmq.UseTracing | YES | MSMQ Header Property | |
| Send/Receive | msmq.QueuePath | N/A | Used to dynamically set the Queue Path design time property | |
| Receive | msmq.UseAuthentication | YES | MSMQ Header Property | |
| Receive | msmq.TransactionId | YES | MSMQ Header Property | |
| Receive | msmq.SourceMachine | YES | MSMQ Header Property | |
| Receive | msmq.SentTime | YES | MSMQ Header Property | |
| Receive | msmq.MessageType | YES | MSMQ Header Property | |
| Receive | msmq.LookupId | YES | MSMQ Header Property | |
| Receive | msmq.IsLastInTransaction | YES | MSMQ Header Property | |
| Receive | msmq.IsFirstInTransaction | YES | MSMQ Header Property | |
| Receive | msmq.DestinationQueue | YES | MSMQ Header Property | |
| Receive | msmq.ConnectorType | YES | MSMQ Header Property | |
| Receive | msmq.BodyType | YES | MSMQ Header Property | |
| Receive | msmq.AuthenticationProviderType | YES | MSMQ Header Property | |
| Receive | msmq.AuthenticationProviderName | YES | MSMQ Header Property | |
| Receive | msmq.Authenticated | YES | MSMQ Header Property | |
| Receive | msmq.Acknowledgment | YES | MSMQ Header Property | |
| Receive | msmq.ArrivedTime | YES | MSMQ Header Property | |
| Receive | msmq.ReceivedMessage | N/A | Set to true if Direction == Receive and a message is found on the Queue, otherwise the value will be false. |
Dynamic Configuration
Directly preceding the MSMQ Process Step could be a Set Property Process Step or a Code Step. If a Code Step was used, the following custom properties could be used:
context.Data.SetProperty("msmq","CorrelationId",
" 220b1f11-23b6-460c-a83b-70907e9dff45\3940494");
context.Data.SetProperty("msmq","QueuePath",
".\Private$\msgsfromneuron");
The msmq.CorrelationId property can be used to dynamically set the Correlation Id at runtime. This is useful if business logic within the process is required to compose the uniqueness of the Correlation Id. In other cases, the actual Queue to send the message to or attempt to read from may only be able to be determined at runtime. For instance, perhaps an MSMQ is mapped to a user or customer, and the name of that user or customer can only be known at runtime.
The msmq properties can be accessed directly from the Neuron ESB Message object using the GetProperty() or GetProperties() methods. All Neuron ESB Message properties can also be set using the Set Property Process Step.
| Process Step | Custom Property (i.e. prefix.name) | Design-time Property |
| MSMQ | msmq.CorrelationId | N/A Required if Correlate property is set to True. |
| msmq.AppSpecific | AppSpecific | |
| msmq.Label | Label | |
| msmq.Priority | Priority | |
| msmq.AcknowledgeType | N/A | |
| msmq.AttachSenderId | N/A | |
| msmq.TimeToBeReceived | N/A | |
| msmq.TimeToReachQueue | N/A | |
| msmq.UseDeadLetterQueue | N/A | |
| msmq.UseEncryption | N/A | |
| msmq.UseJournalQueue | N/A | |
| msmq.UseTracing | N/A | |
| msmq.QueuePath | Queue Path | |
| msmq.Recoverable | Recoverable |
https://www.peregrineconnect.com/neuron/Help3/Development/Samples_and_Walkthroughs/Process_Samples/Correlated_Messaging_with_the_MSMQ_Process_Step.htm
Design Time Properties
| Name | Dynamic | Description |
| Name | User provided name for the Process Step. Will replace default name of Step when placed on the Design Canvas. | |
| Disable | Boolean flag to determine whether the step should be executed at runtime or design time. NOTE: Also available from the right-click context menu. | |
| Bindings | Launches the Binding Expressions dialog for specifying Environment Variables. | |
| Queue Path | YES | Required. The path of the MSMQ queue to send to or receive from. Can be dynamically set using msmq.QueuePath Esb Message property. i.e. ‘.\Private$\QueueName’ or FormatName:Direct=OS:machine\Private$\QueueName |
| Transactional | Required. Default is Required. When set toRequired, Neuron will share an existing transaction if one is exists, otherwise Neuron will create a new Transaction. When set toRequiresNew, Neuron will create a new transaction regardless of whether or not there is an existing transaction. When set toNone, Neuron ignores any transaction that may exist. To participate in a transaction, you must be using transactional message queues. It the queue is not on localhost, and then MSDTC must be running. Remote transactional reads are only supported with Msmq 4.0 and higher. | |
| Clear Connection Cache | Required. Default is True. MSMQ maintains a cache of format names and opened handles. When set to True, Neuron clears the format names and closes any opened handles that are stored in the cache. | |
| Use ActiveXMessageFormatter | Required. Default is True. The ActiveX Message format is compatible with Message Queuing COM components. | |
| Extended Properties | Required. Default is True. Retrieves MSMQ Message properties when reading a message from a queue and applies them as custom Neuron ESB Message Properties. Dynamically sets MSMQ Message properties from the Neuron ESB Message when sending to a queue. https://msdn.microsoft.com/en-us/library/ms705286(v=vs.85).aspx | |
| Operation | Required. Default value is Send. SelectSendto publish a message to an MSMQ queue,Receiveto receive a message from a queue, orPeekto peek at a message in a queue but not remove it. | |
| Correlate | Required. Default is False. Receive messages that correlate with a previously sent message using the Correlation Id value. | |
| CorrelationId | YES | ONLY Required if Correlate is set to True. The Correlation Id that is used to set the MSMQ CorrelationId property of the MSMQ Message created and sent to a Queue. In addition, the Correlation Id used to determine what message(s) to read/peek from a Queue. The Correlation Id must conform to the format specified by MSMQ, which is essentially a GUID and 7-digit number separated by a backslash (e.g. \) |
| AppSpecific | Required only when Operation is set to Send. The AppSpecific property can be used for saving characteristics of a message (such as the shipper number of an order) to determine how the message should be processed. This property can be dynamically set using the msmq.AppSpecific ESB message property. Default value is 0. | |
| Label | Optional only used when Operation is set to Send. The Label property can be used as a message identifier to determine the origin of a message, allowing all necessary information for processing the message to be collected from a persistent data store such as a relational database. For example, in processing an order this identifier would be the order number. This property can be dynamically set using the msmq.Label ESB message property. The Neuron ESB MSMQ Adapter has the ability to map Labels to Topic names. | |
| Priority | Required only when Operation is set to Send. Default value is Normal. The priority level assigned to the MSMQ message. The priority effects how MSMQ handles the message while it is in route, as well as where the message is placed in the queue. Higher priority messages are given preference during routing, and inserted toward the front of the queue. Messages with the same priority are placed in the queue according to their arrival time. This property can be dynamically set using the msmq.Priority ESB message property. | |
| Recoverable | Required only when Operation is set to Send. Default value is False. By default, MSMQ stores messages in memory for increased performance, and a message may be sent and received from a queue without ever having been written to disk. One can control this behavior, forcing MSMQ to store a message to disk, by specifying that a message should be recoverable. | |
| Timeout | Required only when Operation is set to Read or Peek. The receive timeout for retrieving message from queue. Timespan format. |
ODBC

| Category: | Storage |
| Class: | OdbcStep |
| Namespace: | Neuron.Esb.Pipelines |
| Assembly: | Neuron.Esb.Pipelines.dll |
Description:
The ODBC Process Step provides powerful capabilities for users building Business Processes that need to integrate directly with ODBC based data sources (i.e. Excel, SQL Server, Oracle, DB2, MySQL, and Lotus Notes, among others). The ODBC Process Step supports one-way inserts and updates, as well as query (i.e. Request/Response) types of message patterns. Generally, it supports all the capabilities of the Neuron ESB ODBC Adapter except Publish and Batch mode operations. Optionally, the ODBC Process Step can also generate XML Schemas that represent the result sets returned. This Step uses the same ODBC Connection String Builder that the Neuron ESB ODBC Adapter uses.
The ODBC Process Step supports both Message based and Parameter Mapped configuration models. When using the Message based model, a specifically formatted XML message must be sent to the Process Step. The XML message contains all the necessary meta-data and information to direct the Process Step on how and what to execute against the datasource. The following is an example of an XML message that he ODBC Process step understands. It contains the type of call to make, the format of the call, and the meta-data for the parameters of the call including their respective values:
<Statement sql="{Call StoreOrderItem(?,?,?)}" type="StoredProcedure">
<Parameters>
<Parameter name="@OrderID" type="int" value="1237"></Parameter>
<Parameter name="@OrderDate" type="datetime" value="4/22/09"></Parameter>
<Parameter name="@OrderAmount" type="money" value="100.00"></Parameter>
</Parameters>
</Statement>
In contrast, the Parameter Mapped based model allows users to work directly with existing XML messages, Neuron ESB Message headers and custom properties to map values within them directly to parameters for the call as shown below:
The Parameter Mapped based model allows developers to work with any existing message or meta-data without the need for creating specially formatted documents or template mapping.
Besides the different configuration models, the ODBC Process Step supports a number of features including:
- Strongly Typed Parameters
- Stored Procedures and Dynamic SQL
- Output and ReturnValue Parameters
- XSD Schema Generation
- Restriction of Rows Returned
Developers can use the ODBC Process Step to make one-way calls (i.e. insert, update, upsert, etc.) or queries (i.e. Select * From, etc.) against any ODBC data source that a registered ODBC driver exists for. For one-way calls, the Semantic property of the Step must be set to Multicast. For queries, the Semantic property must be set to Request.
Either ODBC Drivers or ODBC Data Source Names (DSN) can be used when constructing a connection string for the ODBC Process Step.
The ODBC Process Step provides the Connection String Builder user interface (UI) to assist users in constructing connection strings. This can be launched by clicking the ellipsis button located on the Connection String property in the Process Steps property grid:
All connection strings built using the Connection String Builder UI are stored as encrypted name/value pairs as shown in the lower half of the screen (grid). One column contains ODBC Keywords, while the other contains their respective values.
https://www.connectionstrings.com/
The Connection String Builder UI supports several ways to assist users in creating connection strings:
- Using the ODBC Datasource Name Administrator
- Querying ODBC Drivers
- Manually entering in Keyword and Value pairs
If the Data Source Name radio button option is selected, users can launch the Microsoft Windows ODBC Data Source Administrator by clicking the Create button as displayed below:
If ODBC Data Source Names (DSN) already exist, clicking the Load button will populate the list of DSNs (User and System) in the top part (grid) of the ODBC Connection String Builder UI. Clicking on any entry will automatically populate the correct Name/Value pairs in the lower grid with the DSN keyword and value as well as the Driver keyword and value
Alternatively, users can directly query an ODBC driver for the list of available keywords that it supports by choosing the ODBC Driver radio button option. When selected, the dropdown will be populated by all the available registered ODBC Drivers on the machine. Select one, and then click the Load button.
Not every Keyword/Value pair is required to make a successful connection. They can be used to fine-tune the connection though. Usually only four common keywords are required when not using a DSN: Driver, Database, Server and Trusted_Connection (indicating Windows integrated security). Clicking the Test Connection button will use the selected Keyword/Value pairs to connect to the data source as shown below:
Message Formats
Once a connection has been established, the Process Step can execute statements. The configuration of the statements can be either Message or Parameter Mapped based. For Message based statements, the body of the Neuron ESBMessage must be the Neuron ESB ODBC XML format (this is not required for Parameter Mapped configuration). The XML describes the stored procedure or SQL Statement called and parameters that are passed.
Multicast Messages
The sample XML documents below represents an incoming Neuron ESB Message where the Semantic is Multicast. Neither one is expected to return a result set back to the Business Process. In the<Statement>element, the type attribute specifies whether a stored procedure or SQL statement is executed. If a SQL statement is used, the Sql Enabled design time property must be set to true. The sql attribute specifies the stored procedure or SQL statement to be executed. The sql attribute must be in the format using the ODBC call syntax.
If there are any parameters, a<Parameters>element must be used and defines each parameter. The type attribute is optional, but most ODBC data sources need them. If the type attribute is not used, the data source will attempt to cast the value into the data type required by the statement. However, the cast could fail depending on the target data source and the data type that is being cast. When the type attribute is used, it must be an ODBC data type defined in the Microsoft .NET Framework.
When executing a Stored Procedure:
<Statement sql="{Call uspUpdatePhoneNumber(?,?)}" type="StoredProcedure">
<Parameters>
<Parameter name="@Id" type="int" value="3"></Parameter>
<Parameter name="@PhoneNumber" type="varchar" value="11111"></Parameter>
</Parameters>
</Statement>
When executing a SQL Statement (i.e. INSERT):
<Statement sql="INSERT INTO phonebook(LastName, FirstName,PhoneNumber) VALUES(?,?,?)" type="Text"> <Parameters> <Parameter name="@LastName" type="varchar" value="Wasznicky"></Parameter> <Parameter name="@FirstName" type="varchar" value="Todd"></Parameter> <Parameter name="@PhoneNumber" type="varchar" value="3109890000"></Parameter> </Parameters> </Statement>
Null Parameters
Additionally, NULL values can be passed to the datasource by adding the nillable attribute to the Parameter element and setting the value attribute to null as shown below:

Binary Parameters
Lastly, if the type attribute is set to binary, image or varbinary, the ODBC Process Step will use the text of the value attribute within the Parameter element. It will assume the text is base64 encoded and attempt to convert it to a byte array, which will be passed to the datasource. If the text contains a file:// url as the content, it will use the url to read in the content as a byte array and pass that to the datasource. The specific type used depends on the type used for the table or stored procedure. For example, if a column is defined as varbinary(max), then the image odbc data type should be used instead of the binary or larger files may fail.
For example, the following SQL Script will create a table and stored procedure in Microsoft SQL Server. The stored procedure includes a parameter (@FileContent) of varbinary(max):
SET ANSI_NULLS ON GO SET QUOTED_IDENTIFIER ON GO CREATE TABLE [dbo].[FilePrint]( [Id] [int] IDENTITY(1,1) NOT NULL, [FileName] [nvarchar](150) NOT NULL, [FileContent] [varbinary](max) NULL, [FieldOffice] [nvarchar](5) NULL, CONSTRAINT [PK_FilePrint] PRIMARY KEY CLUSTERED ( [Id] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY] TEXTIMAGE_ON [PRIMARY] GO SET ANSI_NULLS ON GO SET QUOTED_IDENTIFIER ON GO CREATE PROCEDURE [dbo].[InsertFilePrint] @FileName nvarchar(150), @FileContent varbinary(max), @FieldOffice nvarchar(5) AS BEGIN SET NOCOUNT ON; Insert into FilePrint (FileName, FileContent, FieldOffice) Values (@FileName, @FileContent, @FieldOffice) END GO
If the script above is executed, creating both the table and stored procedure, then the ODBC XML messages below can be used to insert binary data directly into the table. The first message contains a base64 encoded string as the text for the value attribute, representing the contents of a PDF file:
<Statement sql="{Call InsertFilePrint (?,?,?)} " type="StoredProcedure">
<Parameters>
<Parameter name="@FileName" type="String" value="Test"></Parameter>
<Parameter name="@FileContent" type="Image" value="JVBERi0xLjMKJaqrrK0KNCAwIG9iago8PCAvVHlwZSAvSW5mbwovUHJvZHVjZXIgKG51bGwpID4+ CmVuZG9iago1IDAgb2JqCjw8IC9MZW5ndGggMjY5 NiAvRmlsdGVyIC9GbGF0ZURlY29kZSAKID4+ CnN0cmVhbQp4nLVabVPjyBH+zq9QPqSyt7UW8 z6jrUrVebHN+XJ0eHJlZgo2NTg4CiUlRU9GCg=="></Parameter>
<Parameter name="@FieldOffice" type="String" value="BO"></Parameter>
</Parameters>
</Statement>
The second message below uses the file:\\ moniker to represent the contents of the PDF file. At runtime, the ODBC Process Step will read the file into a byte array and pass it as the parameter to the data source:
<Statement sql="{Call InsertFilePrint (?,?,?)} " type="StoredProcedure">
<Parameters>
<Parameter name="@FileName" type="String" value="Test"></Parameter>
<Parameter name="@FileContent" type="Image" value="file://C:\temp\License_2.0.pdf"></Parameter>
<Parameter name="@FieldOffice" type="String" value="BO"></Parameter>
</Parameters>
</Statement>
Creating Messages
Either creating the message formats can be done through C#, XSLT or using XML Templates. For example, if receiving information via an HTTP POST Query String, the values could be retrieved and mapped within a C# Code Step as shown below:
// Retrieve the template var insertContact = context.Configuration.XmlDocs["InsertContactTemplate"].Xml; // Set the ODBC Statement Parameters based on HTTP POST Query String context.Data.Text = string.Format(insertContact, context.Data.Http.Query["LastName"], context.Data.Http.Query["FirstName"], context.Data.Http.Query["Phone"]);
This would create the following Neuron ESB ODBC XML statement:
<Statement sql="INSERT INTO phonebook(LastName, FirstName,PhoneNumber) VALUES(?,?,?)" type="Text"> <Parameters> <Parameter name="@LastName" type="varchar" value="wasznicky"></Parameter> <Parameter name="@FirstName" type="varchar" value="marty"></Parameter> <Parameter name="@PhoneNumber" type="varchar" value="435-908-9999"></Parameter> </Parameters> </Statement>
Request Messages
Executing statements when the Semantic is a Request functions the same as a message with a Multicast Semantic, except that a result set from the stored procedure or SQL statement is returned as a new Neuron ESB Reply message. The following Neuron ESB ODBC XML formats are examples of SQL statements and Stored Procedures that return a result set.
<Statement sql="select * from PhoneBook where Id = ?" type="Text"> <Parameters> <Parameter name="@Id" type="int" value="2"></Parameter> </Parameters> </Statement>
Executing the statement above would return the following XML back to the Business Process as a Neuron ESB Reply Message:
<NewDataSet> <Table1> <Id>2</Id> <FirstName>Joe</FirstName> <LastName>King</LastName> <PhoneNumber>425-909-8787</PhoneNumber> </Table1> </NewDataSet>
However, developers can control the output and structure of returned result sets by modifying the design time properties like Root Node Name, Row Node Name and Namespace as shown below:
<Employees> <Contact xmlns="https://www.neuronesb.com/contacts"> <Id>2</Id> <FirstName>Joe</FirstName> <LastName>King</LastName> <PhoneNumber>425-909-8787</PhoneNumber> </Contact> </Employees>
SQL statements and Stored Procedures can return a result set or they can use ReturnValue or OutPut parameters to return a value from the Request call. If ReturnValue or OutPut parameters are used, the following format MUST be used. Notice the new direction attribute and the position of the ? = notation in the ODBC Call Syntax. The value of this attribute can be either ReturnValue or OutPut. This attribute is ONLY REQUIRED when making a Request call AND when a value is returned using a ReturnValue or OutPut parameter:
<Statement sql="{? = Call CLOB_InsertPaymentRecord (?,?)}" type="Text">
<Parameters>
<Parameter direction="ReturnValue" name="@RETURN_VALUE" size="1" type="varchar"></Parameter>
<Parameter name="RECORD_NO" type="varchar" value="C9722/2051"></Parameter>
<Parameter name="DATA" type="varchar" value="19.99"></Parameter>
</Parameters>
</Statement>
Parameter Mapping
The ODBC process step has a property called “Use Parameter Mapper”. When set to true, the incoming message will be passed through to the Parameter Mapper, which allows the message to deviate from the format previously described in this document. The Parameter Mapper model offers a unique value over the Message format model. It offers users the ability to decouple the ODBC operation from the incoming Neuron ESB Message body format. When the Use Parameter Mapper is set to true, the following four properties become visible in the property grid:
- Command Type Can be set to either Text or Stored Procedure. If the former, the Sql Enabled design time property must also be set to true. The Text option allows dynamic SQL statements to be entered in the Command property. If set to Stored Procedure, the name of the Stored Procedure to execute must be set in the Command property.
- Command Must contain the dynamic SQL or name of the Stored Procedure to execute. This must be entered in the ODBC Call Syntax.
- Xpath An optional XPATH 1.0 statement. Allows users to select a specific part of the incoming message to be used by the Parameter Mapper. This is only required when the SelectionType property within the OdbcCallParameters Collection Editor is set to either Element, Attribute or OuterXml. It can optionally be used when the Selection Type is set to Xpath as well.
- Parameters This is required if the Command requires parameters. Clicking the ellipsis button launches the OdbcCallParameters Collection Editor which allows users to specify the Parameters within a graphical UI as displayed below.
Each Parameter entry can have the following properties:
- DefaultValue Optional. The value that would be used for the parameter if no other value was specified in the SelectionType property or found in the message. This can also be used to hard code values for Parameters if SelectionType was set to None.
- Direction Required. Specifies if the parameter is an Input, Ouput, InputOutput, or a ReturnValue. Synonymous with the direction attribute in the Message Format section of this document
- ParameterName Required. The name of the parameter passed in the SQL command. Synonymous with the name attribute in the Message Format section of this document
- ParameterType Required. The ODBC data type of the parameter. Synonymous with the type attribute in the Message Format section of this document
- SelectionType Required. Specifies how to find/select the parameter value from the message. Options are None, Element, Attribute, OuterXml, XPath, MessageHeader, and MessageProperty.
- SelectionValue Optional. Specifies the selector value. This value is dependent on the SelectionType and is used as an argument to the method in the selection type. Literal strings do NOT need to be enclosed in quotes.
- Size Optional. Only needed for variable non-binary data types. Synonymous with the size attribute in the Message Format section of this document
The SelectionType property provides the capability to decouple the ODBC operation from using the ODBC XML Message format previously documented. This property allows users to hard code parameter values, use any part of an incoming message as well as use any Neuron ESB Message or Header property as the value for a parameter. This property in concert with the SelectionValue property provides the mapping between the parameter and value. For Example:
- SelectionType is equal to None:
The value can be hard code by entering the value into the DefaultValue property - SelectionType is equal to Element:
The name of the element must be provided in the SelectionValue property. This will be retrieved from the XML Node (innertext property) returned by the XPATH 1.0 property in the property grid. - SelectionType is equal to Attribute:
The name of the attribute must be provided in the SelectionValue property. The Attribute value will be retrieved from the Attributes collection of the XML Node returned by the XPATH 1.0 property in the property grid. - SelectionType is equal to OuterXml:
The SelectionValue property is not used. This will return the OuterXml property of the XML Node returned by the XPATH 1.0 property in the property grid. - SelectionType is equal to XPath:
An XPATH 1.0 statement must be entered in the SelectionValue property. It will be evaluated against either the underlying Neuron ESB message body, or the XML Node returned by the XPATH 1.0 property in the property grid (if one was provided). - SelectionType is equal to MessageHeader:
A valid Neuron ESB Message Header property must be provided in the SelectionValue property (e.g. Action, Topic, MessageId, etc.). The Message Header values are case sensitive. - SelectionType is equal to MessageProperty:
A valid Neuron ESB custom Message property must be provided in the SelectionValue property. This is case sensitive and must be in the format prefix.propertyname (no double quotes).
In the following example, the Property Mapper is used to map a custom Neuron ESB Message property to an ODBC Parameter. The custom Property can be set either using the Set Property Process Step:
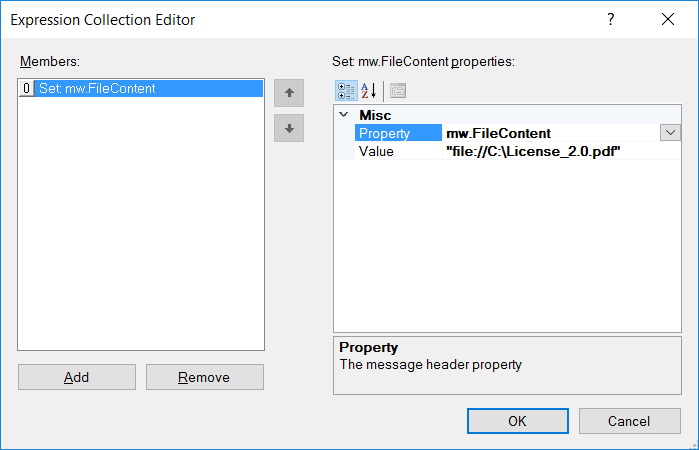
Or by using the following C# code within a C# Code Process Step:
context.Data.SetProperty("mw","FileContent",@"file://C:\License_2.0.pdf");
Within the OdbcCallParameter Collection Editor, the SelectionType property is set to MessageProperty and the SelectionValue property is set to mw.FileContent as displayed below. This will insert a binary payload into a table:
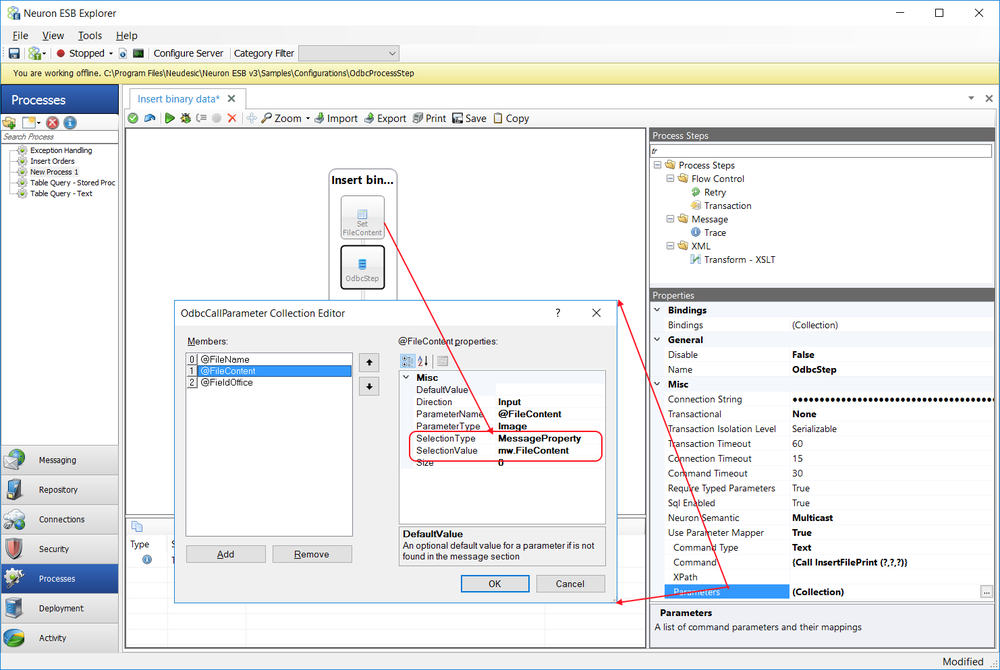
In the next example, the following message is set as the Neuron ESB Message body:
<GetOrder> <OrderID>1235</OrderID> </GetOrder>
The Xpath property in the Property Mapper section of the property grid contains the XPATH 1.0 statement GetOrder, which returns the following child element to the Property Mapper for the OdbcCallParameters Collection Editor to process:
<OrderID>1235</OrderID>
Within the OdbcCallParameter Collection Editor, the SelectionType property is set to Element and the SelectionValue property is set to the XPATH 1.0 statement OrderID as displayed below. This ensures that the innertext property of the OrderID element is used as the Parameter value:
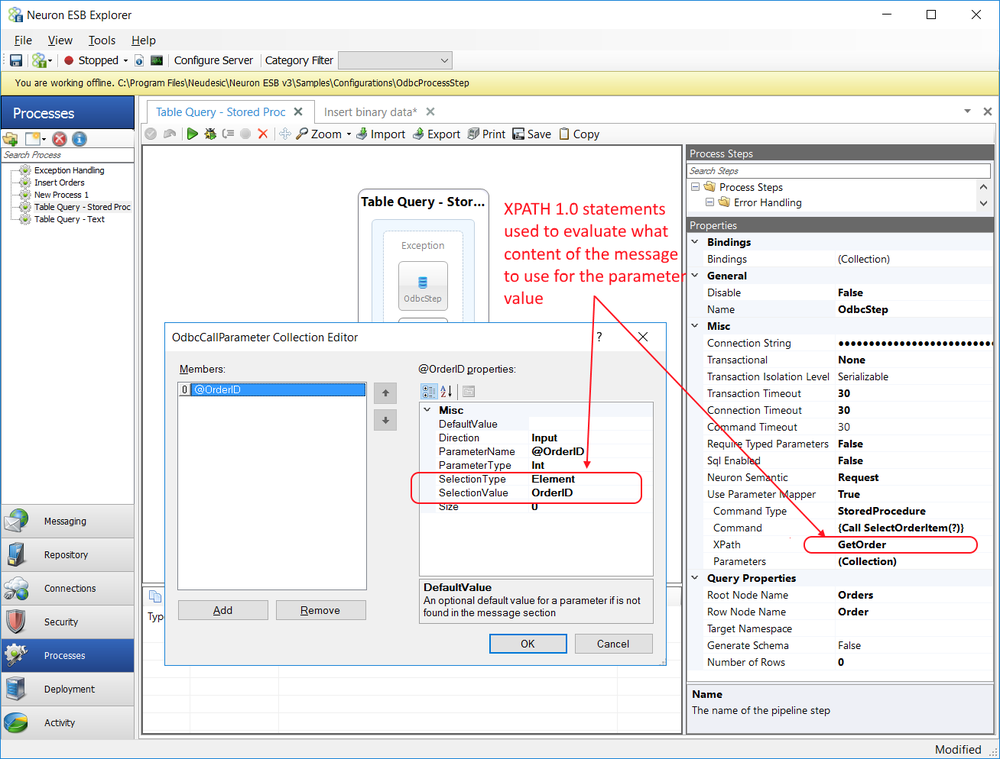
Passing Null and Empty Strings
The SelectionValue and DefaultValue properties within the OdbcCallParameters Collection Editor support passing in null values and empty strings as values for parameters. For a value to be evaluated as null, DBNull must be entered (remove double quotes). To pass an empty string, String.Empty must be entered (remove double quotes).
Schema Generation
The Include Schema design time property can be used to generate an XSD Schema that represents the XML output of the ODBC Process Step. This can be useful validating the output within the Business Process at runtime or in other parts of the system using the Validate Schema Process Step.
This property should only be set to True during development to retrieve the XSD Schema, if one is needed. Usually this would be done by running a test within the Business Process Designer, capturing the output using a Trace Process Step or Audit Process Step, and then copying the XSD portion into the Neuron ESB Schema Repository.
To finalize the structure of the xml that the ODBC Process Step would return when querying a data source, the Root Node Name, Row Node Name and Target Namespace can be modified in the Process Steps property page as shown below:
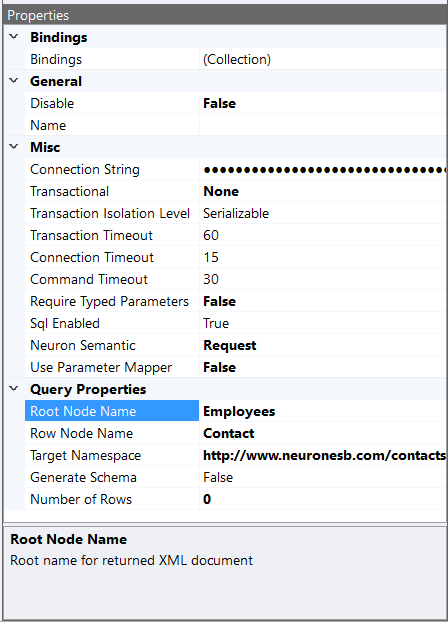
Using the modified properties, the ODBC Process Step produced the following XML output:
<Employees> <Contact xmlns="https://www.neuronesb.com/contacts"> <Id>2</Id> <FirstName>Joe</FirstName> <LastName>King</LastName> <PhoneNumber>425-909-8787</PhoneNumber> </Contact> </Employees>
When the Include Schema design time property is set to True, an XSD Schema will be pre-pended to the output XML. The XSD Schema representing the xml will look like this.
<xs:schema id="Employees" xmlns="" xmlns:xs="https://www.w3.org/2001/XMLSchema" xmlns:msdata="urn:schemas-microsoft-com:xml-msdata" xmlns:app1="https://www.neuronesb.com/contacts" msdata:schemafragmentcount="2"> <xs:import namespace="https://www.neuronesb.com/contacts"/> <xs:element name="Employees" msdata:IsDataSet="true" msdata:UseCurrentLocale="true"> <xs:complexType> <xs:choice minOccurs="0" maxOccurs="unbounded"> <xs:element ref="app1:Contact"/> </xs:choice> </xs:complexType> </xs:element> </xs:schema> <xs:schema targetNamespace="https://www.neuronesb.com/contacts" xmlns:mstns="https://www.neuronesb.com/contacts" xmlns="https://www.neuronesb.com/contacts" xmlns:xs="https://www.w3.org/2001/XMLSchema" xmlns:msdata="urn:schemas-microsoft-com:xml-msdata" attributeFormDefault="qualified" elementFormDefault="qualified" xmlns:app1="https://www.neuronesb.com/contacts"> <xs:element name="Contact"> <xs:complexType> <xs:sequence> <xs:element name="Id" msdata:ReadOnly="true" msdata:AutoIncrement="true" type="xs:int"/> <xs:element name="FirstName" minOccurs="0"> <xs:simpleType> <xs:restriction base="xs:string"> <xs:maxLength value="50"/> </xs:restriction> </xs:simpleType> </xs:element> <xs:element name="LastName" minOccurs="0"> <xs:simpleType> <xs:restriction base="xs:string"> <xs:maxLength value="50"/> </xs:restriction> </xs:simpleType> </xs:element> <xs:element name="PhoneNumber" minOccurs="0"> <xs:simpleType> <xs:restriction base="xs:string"> <xs:maxLength value="50"/> </xs:restriction> </xs:simpleType> </xs:element> </xs:sequence> </xs:complexType> </xs:element> </xs:schema>
Post Processing
After the execution of a Request statement, the odbc.Rows Neuron ESB Message Property can be inspected to determine how many rows were returned in the result set. This property is populated by the Process Step and is usually used in the condition property of a Decision Process Steps Branch as shown below:
return bool.Parse(context.Data.GetProperty("odbc","Rows"));
The prefix for all ODBC custom message properties it odbc and they can be accessed directly from the Neuron ESB Message object using the GetProperty() or GetProperties() methods. All Neuron ESB Message properties can also be set using the Set Property Process Step.
Neuron ESB Message Properties
| Process Step | Direction | Custom Property (i.e. prefix.name) | Description |
| ODBC | Request | odbc.Rows | Used to determine how many rows were returned in the reply message when Semantic is set to Request |
| Request | odbc.RowName | Maps to the Row Node Name design-time property | |
| Request | odbc.RootName | Maps to the Root Node Name design-time property | |
| Request | odbc.Namepace | Maps to the Target Namespace design-time property | |
| Request/Multicast | odbc.ConnectionString | Maps to the Connection String design-time property |
Dynamic Configuration
Directly preceding the ODBC Process Step could be a Set Property Process Step or a Code Step. If a Code Step was used, the following custom properties could be used:
context.Data.SetProperty("odbc","RowName","Customer");
The odbc properties can be accessed directly from the Neuron ESB Message object using the GetProperty() or GetProperties() methods. All Neuron ESB Message properties can also be set using the Set Property Process Step.
| Process Step | Custom Property (i.e. prefix.name) | Design-time Property |
| ODBC | odbc.RowName | Row Node Name |
| odbc.RootName | Root Node Name | |
| odbc.Namepace | Target Namespace | |
| odbc.ConnectionString | Connection String |
Design Time Properties
| Name | Dynamic | Description |
| Name | User provided name for the Process Step. Will replace default name of Step when placed on the Design Canvas. | |
| Disable | Boolean flag to determine whether the step should be executed at runtime or design time. NOTE: Also available from the right-click context menu. | |
| Bindings | Launches the Binding Expressions dialog for specifying Environment Variables. | |
| Connection String | YES | Required. The ODBC connection string to use for communicating with the Odbc data source. The ellipsis button will launch the Connection String Builder UI. |
| Transactional | Required. Default is Required. When set toRequired, Neuron will share an existing transaction if one is exists, otherwise Neuron will create a new Transaction. When set toRequiresNew, Neuron will create a new transaction regardless of whether or not there is an existing transaction. When set toNone, Neuron ignores any transaction that may exist. | |
| Transaction Isolation Level | Required. Default is Serializable. The transaction isolation level. Uses the Microsoft .NET Framework System.Transactions.IsolationLevel enumeration values. | |
| Transaction Timeout | Required. Default is 60 seconds. The number of seconds required for the Transaction to timeout. If less than 1, the timeout will default to 30 seconds. | |
| Connection Timeout | Required. Default is 15 seconds. The number of seconds required for the connection attempt to timeout. Default is 15 seconds. | |
| Command Timeout | Required. Default is 30 seconds. The number of seconds required for the Command execution to timeout. Default is 30 seconds. | |
| Require Typed Parameters | Required. Default is false. Requires that all parameter elements include the type attribute with the appropriate Odbc Data type value. | |
| Sql Enabled | Required. Default is false. Enables dynamic sql to be passed to Process Step. If set to false, then only stored procedures are allowed. When dynamic SQL is allowed, the Process Step will validate against SQL Injection attacks. | |
| Neuron Semantic | Required. Default is Multicast. Either Multicast or Request. Set for Request if returning result set, otherwise set to Multicast. | |
| Use Parameter Mapper | Required. Default is false. Displays the properties required to use the Parameter Mapper UI. When set to true, you will map data from the ESB Message body, message headers or message properties, or provide a default values. When set to false the ESB Message body must be in the XML as described in the documentation. | |
| Command Type | Required if Use Parameter Mapper is true. The method to use to make a database call. StoredProcedure or Text can be selected. | |
| Command | Required if Use Parameter Mapper is true. Either the SQL Text Statement or Stored Procedure in ODBC Call Syntax. | |
| XPATH | Optional if Use Parameter Mapper is true. Only required if specifying Parameters using the Parameter Mapper UI. An XPath expression to select a section of the ESB Message for use in the parameter mappings. | |
| Parameters | Optional if Use Parameter Mapper is true. Launches the Parameter Mapper UI. A list of command parameters and their mappings. | |
| Root Node Name | YES | Optional. Root name for returned XML document |
| Row Node Name | YES | Optional. Row name for returned XML Document |
| Target Namespace | YES | Optional. Target Namespace for returned XML document |
| Generate Schema | Required. Default is false. XSD Schema generated and returned with XML document | |
| Number of Rows | Required. Default is 0. Number of rows to return from odbc statement result set. If -1 or 0, then all rows returned | |
| New Property Throw Error on Exception | This property applies when the Semantic Property value is set to Request. If true, an error will be thrown back to the calling Business Process. If false, the error information will be returned as the body of the response message. |
Store
| Category: | Storage |
| Class: | EsbMessageStorePipelineStep |
| Namespace: | Neuron.Esb.Pipelines |
| Assembly: | Neuron.Esb.Pipelines.dll |
Description:
The Store Process Step supports one-way inserts and updates into any Microsoft SQL Server database.
The Store Process Step provides a Parameter Mapped configuration model. The Parameter Mapped based model allows users to work directly with existing XML messages, Neuron ESB Message headers and custom properties to map values within them directly to SQL parameters for the call as shown below:
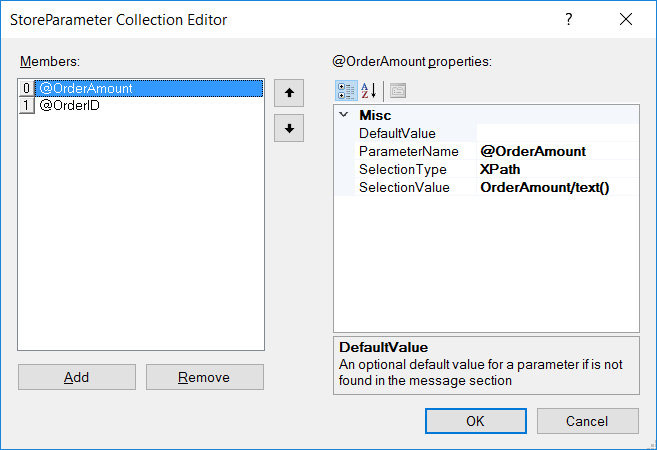
The Parameter Mapped based model allows developers to work with any existing message or meta-data without the need for creating specially formatted documents or template mapping.
Besides the different configuration models, the Store Process Step supports calling either Microsoft SQL Server Stored Procedures or Dynamic SQL.
The Store Process Step provides the Connection Properties user interface (UI) to assist users in constructing SQL connection strings. This can be launched by clicking the ellipsis button located on the Connection String property in the Process Steps property grid:
All connection strings built using the Connection Properties UI are stored as encrypted strings.
Clicking the Test Connection button will use the settings to connect to the Microsoft SQL Server database as shown below:
Parameter Mapping
The Store process step uses a Parameter Mapper, which offers users the ability to decouple the SQL operation from the incoming Neuron ESB Message body format. The following four properties control how the parameter mapping is executed:
- Command Type Can be set to either Text or Stored Procedure. The Text option allows dynamic SQL statements to be entered in the Command property. If set to Stored Procedure, the name of the Stored Procedure to execute must be set in the Command property.
- Command Must contain the dynamic SQL or name of the Stored Procedure to execute. This must be entered in the Microsoft SQL Server SQL Syntax.
- Xpath An optional XPATH 1.0 statement. Allows users to select a specific part of the incoming message to be used by the Parameter Mapper. This is only required when the SelectionType property within the StoreParameter Collection Editor is set to either Element, Attribute or OuterXml. It can optionally be used when the Selection Type is set to Xpath as well.
- Parameters This is required if parameters are required to be passed. Clicking the ellipsis button launches the StoreParameter Collection Editor which allows users to specify the Parameters within a graphical UI as displayed below.
Each Parameter entry can have the following properties:
- DefaultValue Optional. The value that would be used for the parameter if no other value was specified in the SelectionType property or found in the message. This can also be used to hard code values for Parameters if SelectionType is set to None.
- ParameterName Required. The name of the parameter passed in the SQL command.
- SelectionType Required. Specifies how to find/select the parameter value from the message. Options are None, Element, Attribute, OuterXml, XPath, MessageHeader, and MessageProperty.
- SelectionValue Optional. Specifies the selector value. This value is dependent on the SelectionType and is used as an argument to the method in the selection type. Literal strings do NOT need to be enclosed in quotes.
The SelectionType property provides the capability to decouple the SQL operation from the incoming Neuron ESB Message body. This property allows users to hard code parameter values, use any part of an incoming message as well as use any Neuron ESB Message or Header property as the value for a parameter. This property in concert with the SelectionValue property provides the mapping between the parameter and value. For Example:
- SelectionType is equal to None:
The value can be hard code by entering the value into the DefaultValue property - SelectionType is equal to Element:
The name of the element must be provided in the SelectionValue property. This will be retrieved from the XML Node (innertext property) returned by the XPATH 1.0 property in the property grid. - SelectionType is equal to Attribute:
The name of the attribute must be provided in the SelectionValue property. The Attribute value will be retrieved from the Attributes collection of the XML Node returned by the XPATH 1.0 property in the property grid. - SelectionType is equal to OuterXml:
The SelectionValue property is not used. This will return the OuterXml property of the XML Node returned by the XPATH 1.0 property in the property grid. - SelectionType is equal to XPath:
An XPATH 1.0 statement must be entered in the SelectionValue property. It will be evaluated against either the underlying Neuron ESB message body, or the XML Node returned by the XPATH 1.0 property in the property grid (if one was provided). - SelectionType is equal to MessageHeader:
A valid Neuron ESB Message Header property must be provided in the SelectionValue property (e.g. Action, Topic, MessageId, etc.). The Message Header values are case sensitive. - SelectionType is equal to MessageProperty:
A valid Neuron ESB custom Message property must be provided in the SelectionValue property. This is case sensitive and must be in the format prefix.propertyname (no double quotes).
In the following example, the Property Mapper is used to map a custom Neuron ESB Message property to three SQL Parameters. The custom Property can be set either using the Set Property Process Step:
Or by using the following C# code within a C# Code Process Step:
context.Data.SetProperty("mw","OrderID","2345");
context.Data.SetProperty("mw","OrderDate","4/8/2017");
context.Data.SetProperty("mw","OrderAmount","3000");
Within the StoreParameter Collection Editor, the SelectionType property of each Parameter is set to MessageProperty and the SelectionValue property is set to the name of the custom property as displayed below:
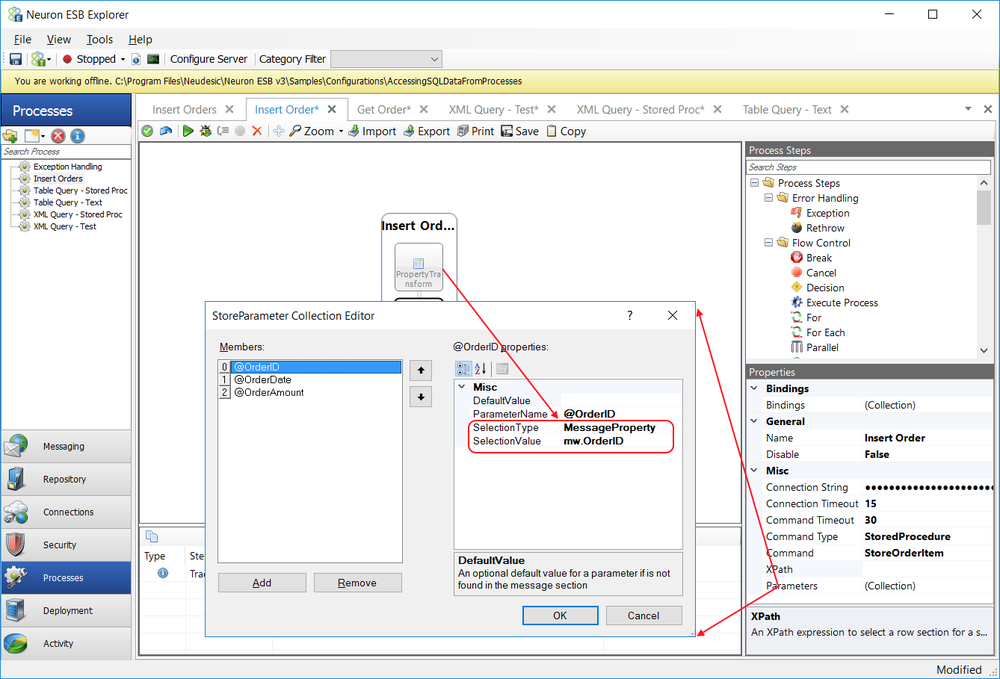
Data Types
The Store Process Step passes all parameters to the Microsoft SQL Server as strings, which are interpreted as varchar data types. If the Dynamic SQL or Stored Procedure being called requires parameters of a different type (i.e. int, bool, etc.) Microsoft SQL Server will automatically attempt to do an implicit conversion between the parameter values and the target data types.
Currently there is no support for passing Null values and working with Binary data types.
Dynamic Configuration
Directly preceding the Store Process Step could be a Set Property Process Step or a Code Step. If a Code Step was used, the following custom properties could be used:
context.Data.SetProperty("sql","ConnectionString",
" ");
The sql.ConnectionString property can be used to dynamically set the ConnectionString design-time property at runtime, effectively changing the target database and server to execute against.
The sql property can be accessed directly from the Neuron ESB Message object using the GetProperty() or GetProperties() methods. All Neuron ESB Message properties can also be set using the Set Property Process Step.
| Process Step | Custom Property (i.e. prefix.name) | Design-time Property |
| Store | sql.ConnectionString | ConnectionString |
New dynamic property
The Command property of this step can be dynamically configured at runtime using the ‘sql.Command’ custom message property.
Design Time Properties
| Name | Dynamic | Description |
| Name | User provided name for the Process Step. Will replace default name of Step when placed on the Design Canvas. | |
| Disable | Boolean flag to determine whether the step should be executed at runtime or design time. NOTE: Also available from the right-click context menu. | |
| Bindings | Launches the Binding Expressions dialog for specifying Environment Variables. | |
| Connection String | YES | Required. The ODBC connection string to use for communicating with the Odbc data source. The ellipsis button will launch the Connection String Builder UI. |
| Connection Timeout | Required. Default is 15 seconds. The number of seconds required for the connection attempt to timeout. Default is 15 seconds. | |
| Command Timeout | Required. Default is 30 seconds. The number of seconds required for the Command execution to timeout. Default is 30 seconds. | |
| Command Type | Required if Use Parameter Mapper is true. The method to use to make a database call. StoredProcedure or Text can be selected. | |
| Command | Required if Use Parameter Mapper is true. Either the SQL Text Statement or Stored Procedure in ODBC Call Syntax. | |
| XPATH | Optional if Use Parameter Mapper is true. Only required if specifying Parameters using the Parameter Mapper UI. An XPath expression to select a section of the ESB Message for use in the parameter mappings. | |
| Parameters | Optional if Use Parameter Mapper is true. Launches the Parameter Mapper UI. A list of command parameters and their mappings. |
Table Query
| Category: | Storage |
| Class: | EsbMessageQueryPipelineStep |
| Namespace: | Neuron.Esb.Pipelines |
| Assembly: | Neuron.Esb.Pipelines.dll |
Description:
The Table Query Process Step supports as query (i.e. Request/Response) type of message pattern against any Microsoft SQL Server database.
The Table Query Process Step provides a Parameter Mapped configuration model. The Parameter Mapped based model allows users to work directly with existing XML messages, Neuron ESB Message headers and custom properties to map values within them directly to SQL parameters for the call as shown below:
The Parameter Mapped based model allows developers to work with any existing message or meta-data without the need for creating specially formatted documents or template mapping.
Besides the different configuration models, the Table Query Process Step supports calling either Microsoft SQL Server Stored Procedures or Dynamic SQL.
The Table Query Process Step provides the Connection Properties user interface (UI) to assist users in constructing SQL connection strings. This can be launched by clicking the ellipsis button located on the Connection String property in the Process Steps property grid:
All connection strings built using the Connection Properties UI are stored as encrypted strings.
Clicking the Test Connection button will use the settings to connect to the Microsoft SQL Server database as shown below:
Parameter Mapping
The Table Query process step uses a Parameter Mapper, which offers users the ability to decouple the SQL operation from the incoming Neuron ESB Message body format. The following four properties control how the parameter mapping is executed:
- Command Type Can be set to either Text or Stored Procedure. The Text option allows dynamic SQL statements to be entered in the Command property. If set to Stored Procedure, the name of the Stored Procedure to execute must be set in the Command property.
- Command Must contain the dynamic SQL or name of the Stored Procedure to execute. This must be entered in the Microsoft SQL Server SQL Syntax.
- Xpath An optional XPATH 1.0 statement. Allows users to select a specific part of the incoming message to be used by the Parameter Mapper. This is only required when the SelectionType property within the QueryParameter Collection Editor is set to either Element, Attribute or OuterXml. It can optionally be used when the Selection Type is set to Xpath as well.
- Parameters This is required if parameters are required to be passed. Clicking the ellipsis button launches the QueryParameter Collection Editor which allows users to specify the Parameters within a graphical UI as displayed below.
Each Parameter entry can have the following properties:
- DefaultValue Optional. The value that would be used for the parameter if no other value was specified in the SelectionType property or found in the message. This can also be used to hard code values for Parameters if SelectionType is set to None.
- ParameterName Required. The name of the parameter passed in the SQL command.
- SelectionType Required. Specifies how to find/select the parameter value from the message. Options are None, Element, Attribute, OuterXml, XPath, MessageHeader, and MessageProperty.
- SelectionValue Optional. Specifies the selector value. This value is dependent on the SelectionType and is used as an argument to the method in the selection type. Literal strings do NOT need to be enclosed in quotes.
The SelectionType property provides the capability to decouple the SQL operation from the incoming Neuron ESB Message body. This property allows users to hard code parameter values, use any part of an incoming message as well as use any Neuron ESB Message or Header property as the value for a parameter. This property in concert with the SelectionValue property provides the mapping between the parameter and value. For Example:
- SelectionType is equal to None:
The value can be hard code by entering the value into the DefaultValue property - SelectionType is equal to Element:
The name of the element must be provided in the SelectionValue property. This will be retrieved from the XML Node (innertext property) returned by the XPATH 1.0 property in the property grid. - SelectionType is equal to Attribute:
The name of the attribute must be provided in the SelectionValue property. The Attribute value will be retrieved from the Attributes collection of the XML Node returned by the XPATH 1.0 property in the property grid. - SelectionType is equal to OuterXml:
The SelectionValue property is not used. This will return the OuterXml property of the XML Node returned by the XPATH 1.0 property in the property grid. - SelectionType is equal to XPath:
An XPATH 1.0 statement must be entered in the SelectionValue property. It will be evaluated against either the underlying Neuron ESB message body, or the XML Node returned by the XPATH 1.0 property in the property grid (if one was provided). - SelectionType is equal to MessageHeader:
A valid Neuron ESB Message Header property must be provided in the SelectionValue property (e.g. Action, Topic, MessageId, etc.). The Message Header values are case sensitive. - SelectionType is equal to MessageProperty:
A valid Neuron ESB custom Message property must be provided in the SelectionValue property. This is case sensitive and must be in the format prefix.propertyname (no double quotes).
In the following example, the Property Mapper is used to map a custom Neuron ESB Message property to a SQL Parameter. The custom Property can be set either using the Set Property Process Step:
Or by using the following C# code within a C# Code Process Step:
context.Data.SetProperty("mw","OrderID","1234");
Within the QueryParameter Collection Editor, the SelectionType property of each Parameter is set to MessageProperty and the SelectionValue property is set to the name of the custom property as displayed below:
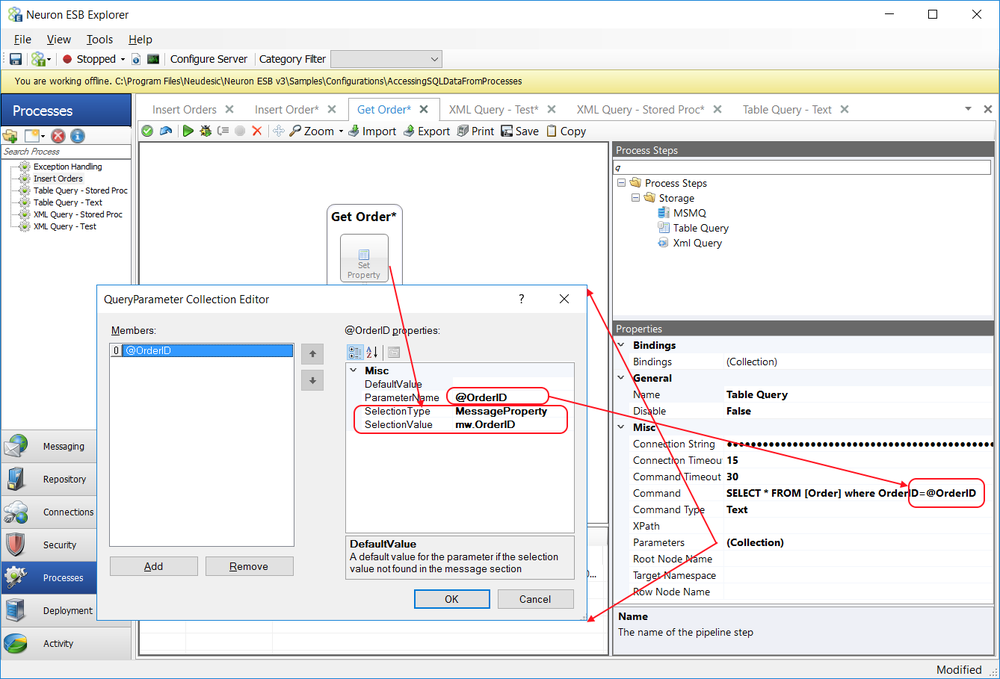
In the next example, the following message is set as the Neuron ESB Message body:
<GetOrder> <OrderID>1235</OrderID> </GetOrder>
The Xpath property in the Property Mapper section of the property grid contains the XPATH 1.0 statement GetOrder, which returns the following child element to the Property Mapper for the QueryParameters Collection Editor to process:
<OrderID>1235</OrderID>
Within the QueryParameters Collection Editor, the SelectionType property is set to Element and the SelectionValue property is set to the XPATH 1.0 statement OrderID as displayed below. This ensures that the innertext property of the OrderID element is used as the Parameter value:
When executed, the Table Query Process Step returns the following default XML message:
<QueryResult> <Row> <OrderID>1235</OrderID> <OrderDate>2009-04-22T00:00:00</OrderDate> <OrderAmount>110.0000</OrderAmount> </Row> </QueryResult>
Data Types
The Table Query Process Step passes all parameters to the Microsoft SQL Server as strings, which are interpreted as varchar data types. If the Dynamic SQL or Stored Procedure being called requires parameters of a different type (i.e. int, bool, etc.) Microsoft SQL Server will automatically attempt to do an implicit conversion between the parameter values and the target data types.
Currently there is no support for passing Null values and working with Binary data types.
Dynamic Configuration
Directly preceding the Table Process Step could be a Set Property Process Step or a Code Step. If a Code Step was used, the following custom properties could be used:
context.Data.SetProperty("sql","ConnectionString",
" ")
The sql.ConnectionString property can be used to dynamically set the ConnectionString design-time property at runtime, effectively changing the target database and server to execute against.
The sql property can be accessed directly from the Neuron ESB Message object using the GetProperty() or GetProperties() methods. All Neuron ESB Message properties can also be set using the Set Property Process Step.
New dynamic property
The Command property of this step can be dynamically configured at runtime using the ‘sql.Command’ custom message property.
| Process Step | Custom Property (i.e. prefix.name) | Design-time Property |
| Table Query | sql.ConnectionString | ConnectionString |
Design Time Properties
| Name | Dynamic | Description |
| Name | User provided name for the Process Step. Will replace default name of Step when placed on the Design Canvas. | |
| Disable | Boolean flag to determine whether the step should be executed at runtime or design time. NOTE: Also available from the right-click context menu. | |
| Bindings | Launches the Binding Expressions dialog for specifying Environment Variables. | |
| Connection String | YES | Required. The ODBC connection string to use for communicating with the Odbc data source. The ellipsis button will launch the Connection String Builder UI. |
| Connection Timeout | Required. Default is 15 seconds. The number of seconds required for the connection attempt to timeout. Default is 15 seconds. | |
| Command Timeout | Required. Default is 30 seconds. The number of seconds required for the Command execution to timeout. Default is 30 seconds. | |
| Command Type | Required if Use Parameter Mapper is true. The method to use to make a database call. StoredProcedure or Text can be selected. | |
| Command | Required if Use Parameter Mapper is true. Either the SQL Text Statement or Stored Procedure in ODBC Call Syntax. | |
| XPATH | Optional if Use Parameter Mapper is true. Only required if specifying Parameters using the Parameter Mapper UI. An XPath expression to select a section of the ESB Message for use in the parameter mappings. | |
| Parameters | Optional if Use Parameter Mapper is true. Launches the Parameter Mapper UI. A list of command parameters and their mappings. | |
| Root Node Name | Optional. Root name for returned XML document. Default is QueryResult | |
| Row Node Name | Optional. Row name for returned XML Document. Default is Row | |
| Target Namespace | Optional. Target Namespace for returned XML document |
Websphere MQ

| Category: | Storage |
| Class: | CustomProcessStep |
| Namespace: | Neuron.Esb.Pipelines.WebSphereMQ |
| Assembly: | Neuron.Esb.Pipelines.dll |
Description:
Websphere MQ is IBM’s very popular messaging system that is used by many Enterprises. Its cross-platform between Windows, IBM’s many offerings like Mainframe, Midrange AS 400 and Linux servers. This process step allows querying of Websphere MQ messages or publishing messages to Websphere MQ. It permits read or browse by either top message, by message id or correlation id.
This step has all the same capabilities of the existing Neuron ESB WebSphere MQ adapter (including the same “wmq” message prefix). However, this process step also allows users to Query a queue to return either the first message in the queue or a message by its message id or correlation id property. When in Query mode, the message can be either read (removing the message permanently from the queue) or browsed (returning the message and its properties while leaving the original message on the queue i.e. peek). When querying by either Message Id or Correlation Id, their respective properties must be set on the inbound message before the query like:
context.Data.SetProperty("wmq","MQMD.MsgId", "323456"); context.Data.SetProperty("wmq","MQMD.CorrelId", "xyz323456");
This step includes ability to configure either Username and Password or SSL. SSL requires that the binding property be set to Client. This makes the process step consistent with the MQSeries Adapter.
Design Time Properties
| Name | Dynamic | Description |
| Name | User provided name for the Process Step. Will replace default name of Step when placed on the Design Canvas. | |
| Disable | Boolean flag to determine whether the step should be executed at runtime or design time. NOTE: Also available from the right-click context menu. | |
| Bindings | Launches the Binding Expressions dialog for specifying Environment Variables. | |
| Mode | Query or Send mode, Send mode will send the message body to the Queue or Topic. Query will allow the user to either retrieve the first message from the queue/topic or query the message by either message id or correlation id | |
| Binding Option | Determines whether the MQ Series Server API or Client side API is used for communication. “Server” and “Bindings” binding requires that MQ Series Server is installed on the same machine the Neuron adapter is running on. “Bindings” will use IPC communication to the local machine. | |
| Queue Manager | Name of Queue Manager to either query a message from, or send messages to. Located on Queue Machine. | |
| Queue | Name of Queue to either publish messages, from or send messages to. Located on Queue Manager. This will not list any queue starting with “System”, “AMQ” or “MQAL”. | |
| Transactional | Ensures that messages are received from or to MQ Series transactionally. Default is no transaction. | |
| Translation Options | Controls how to translate encoded messages received from MQ Series Queue. Default is to not translate. If set to CharacterSet then a coded character set ID must be entered in the CCSID field | |
| CCSID | Default value is 1208. Applies when Translation Option is Characterset | |
| MQ Convert | MQ Convert option. Directs MQSeries to Convert message from source code set when performing MQGET. MQ Format must not be set to NONE. | |
| Use Security | If set to true, pass a username and password to MQSeries Queue Manager | |
| Credentials | Name of the Credential to use to authenticate against the MQSeries Queue Manager. Must be of type username/password. | |
| Use SSL | If true, enter SSL Specific information to access MQSeries Queue Manager. | |
| Certificate Label | The label used to find the Certificate within the certificate repository. This is case sensitive. | |
| Cipher Spec | The name of the SSL Cipher to use. NONE =0, TLS_RSA_WITH_AES_128_CBC_SHA256 = 0x003C, TLS_RSA_WITH_AES_256_CBC_SHA256 = 0x003D, TLS_RSA_WITH_AES_128_CBC_SHA = 0x002F, TLS_RSA_WITH_AES_256_CBC_SHA = 0x0035, TLS_RSA_WITH_AES_128_GCM_SHA256 = 0x009C, TLS_RSA_WITH_AES_256_GCM_SHA384 = 0x009D, ECDHE_ECDSA_AES_128_CBC_SHA256 = 0xC025, ECDHE_ECDSA_AES_256_CBC_SHA384 = 0xC026, ECDHE_ECDSA_AES_128_GCM_SHA256 = 0xC02D, ECDHE_ECDSA_AES_256_GCM_SHA384 = 0xC02E, ECDHE_RSA_AES_128_CBC_SHA256 = 0xC027, ECDHE_RSA_AES_256_CBC_SHA384 = 0xC028, ECDHE_RSA_AES_128_GCM_SHA256 = 0xC02F, // version 9.05 or greater required ECDHE_RSA_AES_256_GCM_SHA384 = 0xC030 // version 9.05 or greater required | |
| Key Repository | Name of the certificate key repository to use | |
| Peer Name | Optional. Used to check the Distinguished Name (DN) of the certificate from the peer queue manager. Must be distinguished name pattern such as ‘CN=QMGR’, OU=IBM, OU=WEBSPHERE’ | |
| Send Mode Properties: | ||
| MQ Format | MQ Format for Message. Used for sending messages from .NET client to MQ Series. Default is MQFMT_STRING. | |
| Default CCSID | The Character Set that the CCSID header will be set to for the incoming message. If ‘Default’ the CCSID of the Queue Manager will be used. ASCII is US-ASCII(437), UTF8 is 1208 and Unicode is 1200 | |
| Persistence | Three Options, None, Persistent and DefinedByQueue Set Persistence of message. Default is to use the persistence defined on the Queue. | |
| Query Mode Properties | ||
| MQ Get Version | Version of MQ Message to get | |
| Wait Interval | Wait Interval (milliseconds). Amount of time to wait for message to arrive in the Queue to retrieve. Default is 500 milliseconds. | |
| Operation | Allows users to either do a destructive read or browse. When set to ‘Read’, the message will be permanently read and removed from the queue. When set to ‘Browse’ the message will be read from the queue, but the message will remain the queue available for subsequent reads. | |
| Get Option | If set to ‘None’, the first message is retrieved. If set to ‘MessageId’ or ‘CorrelationId’, then the message is retrieved using those respective properties, the value of which must be passed as ‘wmq’ custom message properties i.e. ‘MQMD.MsgId’ or ‘MQMD.CorrelId’ |
Xml Query
| Category: | Storage |
| Class: | EsbMessageXmlQueryPipelineStep |
| Namespace: | Neuron.Esb.Pipelines |
| Assembly: | Neuron.Esb.Pipelines.dll |
Description:
The Xml Query Process Step supports as query (i.e. Request/Response) type of message pattern against any Microsoft SQL Server database. The Xml Query Process Step differs from the Table Query Process Step as it is designed to leverage the SQL FOR XML clause, which provides the ability to aggregate the relational row set returned by theSELECTstatement into XML.
The Xml Query Process Step provides a Parameter Mapped configuration model. The Parameter Mapped based model allows users to work directly with existing XML messages, Neuron ESB Message headers and custom properties to map values within them directly to SQL parameters for the call as shown below:
The Parameter Mapped based model allows developers to work with any existing message or meta-data without the need for creating specially formatted documents or template mapping.
Besides the different configuration models, the Xml Query Process Step supports calling either Microsoft SQL Server Stored Procedures or Dynamic SQL.
The Xml Query Process Step provides the Connection Properties user interface (UI) to assist users in constructing SQL connection strings. This can be launched by clicking the ellipsis button located on the Connection String property in the Process Steps property grid:
All connection strings built using the Connection Properties UI are stored as encrypted strings.
Clicking the Test Connection button will use the settings to connect to the Microsoft SQL Server database as shown below:
Parameter Mapping
The Xml Query process step uses a Parameter Mapper, which offers users the ability to decouple the SQL operation from the incoming Neuron ESB Message body format. The following four properties control how the parameter mapping is executed:
- Command Type Can be set to either Text or Stored Procedure. The Text option allows dynamic SQL statements to be entered in the Command property. If set to Stored Procedure, the name of the Stored Procedure to execute must be set in the Command property.
- Command Must contain the dynamic SQL or name of the Stored Procedure to execute. This must be entered in the Microsoft SQL Server SQL Syntax. If this is Text, it must be appended with a FOR XML clause. If a Stored Procedure is used, it must return a result set generated by a FOR XML clause.
- Xpath An optional XPATH 1.0 statement. Allows users to select a specific part of the incoming message to be used by the Parameter Mapper. This is only required when the SelectionType property within the QueryParameter Collection Editor is set to either Element, Attribute or OuterXml. It can optionally be used when the Selection Type is set to Xpath as well.
- Parameters This is required if parameters are required to be passed. Clicking the ellipsis button launches the QueryParameter Collection Editor which allows users to specify the Parameters within a graphical UI as displayed below.
Each Parameter entry can have the following properties:
- DefaultValue Optional. The value that would be used for the parameter if no other value was specified in the SelectionType property or found in the message. This can also be used to hard code values for Parameters if SelectionType is set to None.
- ParameterName Required. The name of the parameter passed in the SQL command.
- SelectionType Required. Specifies how to find/select the parameter value from the message. Options are None, Element, Attribute, OuterXml, XPath, MessageHeader, and MessageProperty.
- SelectionValue Optional. Specifies the selector value. This value is dependent on the SelectionType and is used as an argument to the method in the selection type. Literal strings do NOT need to be enclosed in quotes.
The SelectionType property provides the capability to decouple the SQL operation from the incoming Neuron ESB Message body. This property allows users to hard code parameter values, use any part of an incoming message as well as use any Neuron ESB Message or Header property as the value for a parameter. This property in concert with the SelectionValue property provides the mapping between the parameter and value. For Example:
- SelectionType is equal to None:
The value can be hard code by entering the value into the DefaultValue property - SelectionType is equal to Element:
The name of the element must be provided in the SelectionValue property. This will be retrieved from the XML Node (innertext property) returned by the XPATH 1.0 property in the property grid. - SelectionType is equal to Attribute:
The name of the attribute must be provided in the SelectionValue property. The Attribute value will be retrieved from the Attributes collection of the XML Node returned by the XPATH 1.0 property in the property grid. - SelectionType is equal to OuterXml:
The SelectionValue property is not used. This will return the OuterXml property of the XML Node returned by the XPATH 1.0 property in the property grid. - SelectionType is equal to XPath:
An XPATH 1.0 statement must be entered in the SelectionValue property. It will be evaluated against either the underlying Neuron ESB message body, or the XML Node returned by the XPATH 1.0 property in the property grid (if one was provided). - SelectionType is equal to MessageHeader:
A valid Neuron ESB Message Header property must be provided in the SelectionValue property (e.g. Action, Topic, MessageId, etc.). The Message Header values are case sensitive. - SelectionType is equal to MessageProperty:
A valid Neuron ESB custom Message property must be provided in the SelectionValue property. This is case sensitive and must be in the format prefix.propertyname (no double quotes).
In the following example, the Property Mapper is not used as the following FOR XML statement is used in the Command property:
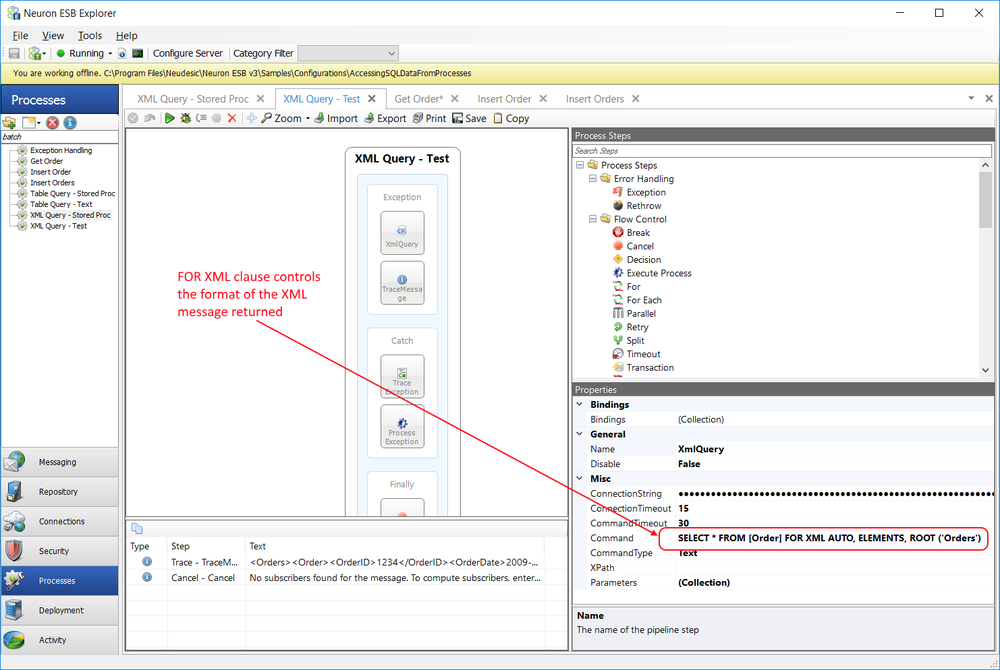
The FOR XML clause controls the format of the XML message returned as shown below:
<Orders> <Order> <OrderID>1234</OrderID> <OrderDate>2009-04-22T00:00:00</OrderDate> <OrderAmount>100.0000</OrderAmount> </Order> <Order> <OrderID>1235</OrderID> <OrderDate>2009-04-22T00:00:00</OrderDate> <OrderAmount>110.0000</OrderAmount> </Order> </Orders>
In the next example, the following message is set as the Neuron ESB Message body:
<GetOrder> <OrderID>1235</OrderID> </GetOrder>
The Xpath property in the Property Mapper section of the property grid contains the XPATH 1.0 statement GetOrder, which returns the following child element to the Property Mapper for the QueryParameters Collection Editor to process:
<OrderID>1235</OrderID>
Within the QueryParameters Collection Editor, the SelectionType property is set to XPath and the SelectionValue property is set to the XPATH 1.0 statement OrderID/text()as displayed below. This ensures that the text property of the OrderID element is used as the Parameter value:
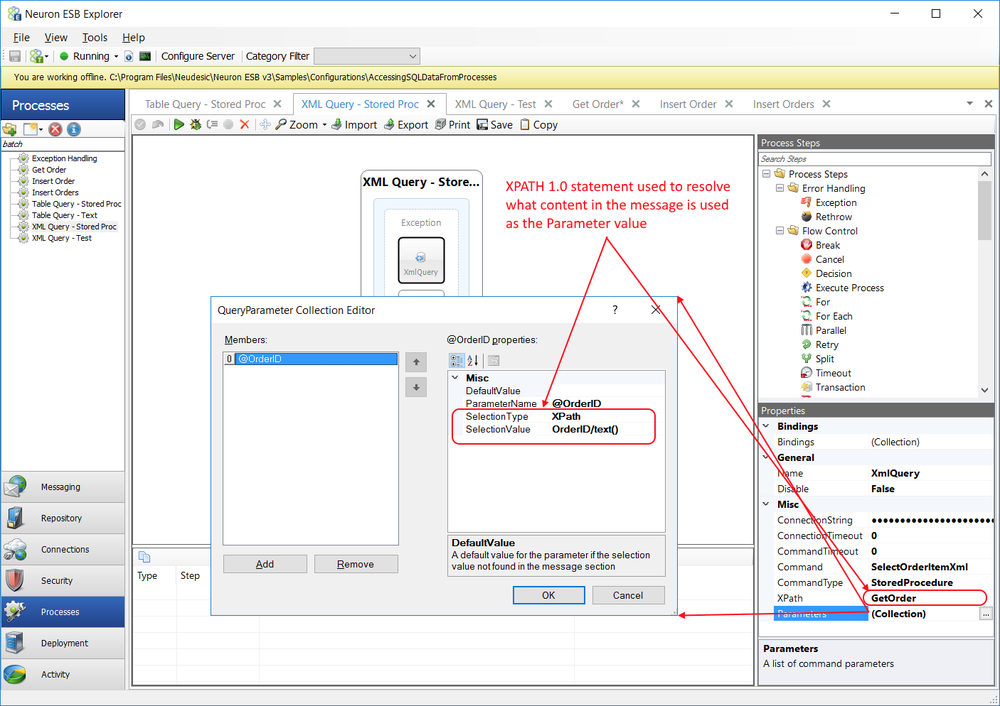
When executed, the Xml Query Process Step returns the following default XML message:
<Order> <OrderID>1235</OrderID> <OrderDate>2009-04-22T00:00:00</OrderDate> <OrderAmount>110.0000</OrderAmount> </Order>
Data Types
The Xml Query Process Step passes all parameters to the Microsoft SQL Server as strings, which are interpreted as varchar data types. If the Dynamic SQL or Stored Procedure being called requires parameters of a different type (i.e. int, bool, etc.) Microsoft SQL Server will automatically attempt to do an implicit conversion between the parameter values and the target data types.
Currently there is no support for passing Null values and working with Binary data types.
Dynamic Configuration
Directly preceding the Xml Process Step could be a Set Property Process Step or a Code Step. If a Code Step was used, the following custom properties could be used:
context.Data.SetProperty("sql","ConnectionString"," ");
The sql.ConnectionString property can be used to dynamically set the ConnectionString design-time property at runtime, effectively changing the target database and server to execute against.
The sql property can be accessed directly from the Neuron ESB Message object using the GetProperty() or GetProperties() methods. All Neuron ESB Message properties can also be set using the Set Property Process Step.
New dynamic property
The Command property of this step can be dynamically configured at runtime using the ‘sql.Command’ custom message property.
| Process Step | Custom Property (i.e. prefix.name) | Design-time Property |
| Xml Query | sql.ConnectionString | ConnectionString |
Design Time Properties
| Name | Dynamic | Description |
| Name | User provided name for the Process Step. Will replace default name of Step when placed on the Design Canvas. | |
| Disable | Boolean flag to determine whether the step should be executed at runtime or design time. NOTE: Also available from the right-click context menu. | |
| Bindings | Launches the Binding Expressions dialog for specifying Environment Variables. | |
| Connection String | YES | Required. The ODBC connection string to use for communicating with the Odbc data source. The ellipsis button will launch the Connection String Builder UI. |
| Connection Timeout | Required. Default is 15 seconds. The number of seconds required for the connection attempt to timeout. Default is 15 seconds. | |
| Command Timeout | Required. Default is 30 seconds. The number of seconds required for the Command execution to timeout. Default is 30 seconds. | |
| Command Type | Required if Use Parameter Mapper is true. The method to use to make a database call. StoredProcedure or Text can be selected. | |
| Command | Required if Use Parameter Mapper is true. Either the SQL Text Statement or Stored Procedure in ODBC Call Syntax. | |
| XPATH | Optional if Use Parameter Mapper is true. Only required if specifying Parameters using the Parameter Mapper UI. An XPath expression to select a section of the ESB Message for use in the parameter mappings. | |
| Parameters | Optional if Use Parameter Mapper is true. Launches the Parameter Mapper UI. A list of command parameters and their mappings. |
XML
Excel to XML
| Category: | Message |
| Class: | ExcelToXmlPipelineStep |
| Namespace: | Neuron.Esb.Pipelines |
| Assembly: | Neuron.Esb.Pipelines.dll |
Description:
The Excel to XML Process Step is used to convert an Excel Worksheet within an Excel Workbook file into an XML formatted message. This can be done for Worksheets/Workbook files created with pre 2007 and post 2007 editions of Microsoft Excel. Once converted to XML, the file can be processed using any Process Step or C# Code. The Excel to XML Process Step uses a combination of design time properties as well as the structure of the Excel Worksheet to determine the final XML format (i.e. Root node name, Row node name, XML element names, namespace etc.), allowing the user granular control over the output structure of the XML.
For example, the following Spreadsheet has a worksheet named DATA. This worksheet has defined column headers (first row):
Within the design properties of the Excel to XML Process Step, the Root Node Name property is set to Payments and the Row Node Name property is set to Record. If an Adapter Endpoint consumes the file, executing the Process Step, the following XML Message (only displaying a fragment below) will be created and set as the Body of the Neuron ESB Message:
<Payments> <Record> <STUDY_NO>D6898</STUDY_NO> <COUNTRY_CODE>USA</COUNTRY_CODE> <RANK_NO>1</RANK_NO> <CREDIT>3880</CREDIT> <LAST_NAME>Medlock</LAST_NAME> <FIRST_NAME>John</FIRST_NAME> <REFERENCE_NO>001</REFERENCE_NO> <ORG_NAME>PPD Development, LP</ORG_NAME> <ORG_ADDRESS>7551 Metro Center Drive Cuite 200</ORG_ADDRESS> <CITY>Bustin</CITY> <STATE>TX</STATE> <ZIP>78744</ZIP> <PAYEE>PPD Development, LP</PAYEE> <PAYMENT>815200.05</PAYMENT> <PAYMENT_DATE>2017-07-15T00:00:00-07:00</PAYMENT_DATE> <CORRECTION>No</CORRECTION> <PAYMENT_TYPE>CC</PAYMENT_TYPE> </Record> <Record> <STUDY_NO>D6898</STUDY_NO> <COUNTRY_CODE>USA</COUNTRY_CODE>
Each row in the original spreadsheet will be represented as a repeating Record element within the Payments root. Each original column header name is converted to an XML element containing the value of the cell. Once the Excel Worksheet is converted to XML, the Split Process Step can be used to split the XML file into its constituent records (rows), allowing them to be processed individually.
The Excel to XML Process Step has a number of features to allow customization of the XML output, making post processing of the output less troublesome. Some of these features include:
- Support for SQL WHERE clauses
- Support for excluding NULL field values
- Support for Adding Row Numbers
- Support for generating an XSD Schema
- Support for limiting the number of rows returned
Features
SQL WHERE clauses
When the Excel to XML Process Step translates an incoming Excel Worksheet to XML it can use an ANSI compliant SQL WHERE clause (including AND/OR) to restrict how many and exactly what rows in the Worksheet will be included in the XML output. To include a restriction, the Column(s) Constraint design time property must be configured with the body of a WHERE clause and must NOT be enclosed in quotes. The body of the WHERE clause must refer to the Excel Worksheet column header names as field names. For example, in the screen shot of the Excel Workbook earlier in this document, the second column header is labeled COUNTRY_CODE. If a user needs to ensure that ONLY rows that have the value of USA or US in this column are included in the XML output, the following WHERE clause could be entered into the design time property:
Country_Code = 'US' OR Country_Code = 'USA'
The labels representing the field names in the body of the WHERE clause are not case sensitive. All text comparisons must be enclosed single quotes. This provides users the ability to selectively choose which rows, based on their cell values in a Worksheet should be translated to an XML output.
Excluding NULL field values
The Exclude NULL Fields design time property is used to allow users the flexibility to either include or exclude the XML element representing a field within a row included in the final XML output document. This can make further document operations such as mapping and schema validation less problematic and more predictable. For instance, in the screen shot of the Excel Workbook earlier in this document, the third column header is labeled RANK_NO. If a value is missing for this cell in a row and the Exclude NULL Fields property is set to false, the XML output for the row would appear as follows.
<Payments> <Record> <STUDY_NO>D6898</STUDY_NO> <COUNTRY_CODE>USA</COUNTRY_CODE> <strong style="font-weight: bold;"> <em style="font-style: italic;"> <RANK_NO></RANK_NO> </em> </strong> <CREDIT>6894</CREDIT> <LAST_NAME>Jones</LAST_NAME> <FIRST_NAME>Mark</FIRST_NAME> <REFERENCE_NO>001</REFERENCE_NO> <ORG_NAME>CNBL Clinical Pharmacology Center</ORG_NAME> <ORG_ADDRESS>800 East Baltimore Ave., 4th Floor</ORG_ADDRESS> <CITY>Baltimore</CITY> <STATE>MD</STATE> <ZIP>21201</ZIP> <PAYEE>CNBL Clinical Pharmacology Center</PAYEE> <PAYMENT>368489.92</PAYMENT> <PAYMENT_DATE>2017-07-15T00:00:00-07:00</PAYMENT_DATE> <CORRECTION>No</CORRECTION> <PAYMENT_TYPE>CC</PAYMENT_TYPE> </Record> </Payments>
However, if the value of the Exclude NULL Fields property is set to true, the same document would appear without the RANK_NO element as shown below:
<Payments> <Record> <STUDY_NO>D6898</STUDY_NO> <COUNTRY_CODE>USA</COUNTRY_CODE> <CREDIT>6894</CREDIT> <LAST_NAME>Jones</LAST_NAME> <FIRST_NAME>Mark</FIRST_NAME> <REFERENCE_NO>001</REFERENCE_NO> <ORG_NAME>CNBL Clinical Pharmacology Center</ORG_NAME> <ORG_ADDRESS>800 East Baltimore Ave., 4th Floor</ORG_ADDRESS> <CITY>Baltimore</CITY> <STATE>MD</STATE> <ZIP>21201</ZIP> <PAYEE>CNBL Clinical Pharmacology Center</PAYEE> <PAYMENT>368489.92</PAYMENT> <PAYMENT_DATE>2017-07-15T00:00:00-07:00</PAYMENT_DATE> <CORRECTION>No</CORRECTION> <PAYMENT_TYPE>CC</PAYMENT_TYPE> </Record> </Payments>
Adding Row NumbersThe Excel to XML Process Step will convert an Excel Worksheet, which may contain hundreds, thousands, tens of thousands, or more rows into an XML document. Consequently, the Process Step is usually used in concert with the Split Process Step to decompose the output XML document into its constituent records so that each row can be processed as an individual message. The Split Process Step allows processing to occur either synchronously (i.e. ForEach) or asynchronously. In all cases, errors may arise when processing the individual rows. If an error occurs, the user can handle the error while allowing other rows to continue processing. In many cases, it may be preferable to report which row in the originating Excel Worksheet generated the error.
The Add Row Numbers design time property, if set to True, auto generates row numbers during the internal conversion process. An XML element named, _RowNumber, will be appended as a column to each row within the XML document, its value will represent the row number within the original Excel Worksheet as shown below:
<Payments> <Record> <STUDY_NO>D6898</STUDY_NO> <COUNTRY_CODE>USA</COUNTRY_CODE> <RANK_NO>1</RANK_NO> <CREDIT>3880</CREDIT> <LAST_NAME>Henry</LAST_NAME> <FIRST_NAME>John</FIRST_NAME> <ORG_NAME>RD Development, LP</ORG_NAME> <ORG_ADDRESS>8551 Center Drive Floor 200</ORG_ADDRESS> <CITY>Bustin</CITY> <STATE>TX</STATE> <ZIP>78994</ZIP> <PAYEE>RD Development, LP</PAYEE> <PAYMENT>815200.05</PAYMENT> <PAYMENT_DATE>2017-07-15T00:00:00-07:00</PAYMENT_DATE> <CORRECTION>No</CORRECTION> <PAYMENT_TYPE>CC</PAYMENT_TYPE> <strong style="font-weight: bold;"> <em style="font-style: italic;"> <_RowNumber>1</_RowNumber> </em> </strong> </Record> <Record> <STUDY_NO>D6898</STUDY_NO> <COUNTRY_CODE>USA</COUNTRY_CODE> <RANK_NO>1</RANK_NO> <CREDIT>6894</CREDIT> <LAST_NAME>Jones</LAST_NAME> <FIRST_NAME>Mark</FIRST_NAME> <REFERENCE_NO>001</REFERENCE_NO> <ORG_NAME>NBC Clinical Pharmacology Center</ORG_NAME> <ORG_ADDRESS>700 East Baltimore Street 4th Floor</ORG_ADDRESS> <CITY>Baltimore</CITY> <STATE>MD</STATE> <ZIP>23201</ZIP> <PAYEE>NBC Clinical Pharmacology Center </PAYEE> <PAYMENT>368489.92</PAYMENT> <PAYMENT_DATE>2017-07-15T00:00:00-07:00</PAYMENT_DATE> <CORRECTION>No</CORRECTION> <PAYMENT_TYPE>CC</PAYMENT_TYPE> <_RowNumber>2</_RowNumber> </Record> </Payments>
The row number in concert with the Neuron ESB custom message property, exceltoxml.RowsReturned can be used to enhance exception messages when any particular row within the document generates an error during processing as the sample below demonstrates:
// Retrieve the row number from within the XML document
var rowNumber = 0;
var node =
context.Data.ToXmlDocument().SelectSingleNode("//_RowNumber");
if(node != null)
rowNumber = int.Parse(node.InnerText);
// Retrieve the properties populated by the Excel to XML Step
var rowCount = int.Parse(context.Data.GetProperty("exceltoxml",
"RowsReturned","0"));
var workSheet = context.Data.GetProperty("exceltoxml",
"WorkSheet","");
var filename = context.Data.GetProperty("exceltoxml",
"Filename","");
// Get current exception
var ex = (System.Exception)context.Properties["CurrentException"];
// Create a new error message that tells the user what exact
// row in the original spreadsheet caused the error
var errorMessage = String.Format(
System.Globalization.CultureInfo.InvariantCulture,
"The Payment Process failed processing row {0} of a
{1} " +
"in the '{2}' Worksheet from the Excel Workbook, "
+ "'{3}'.{4}{4}Error Message: {5}",
rowNumber,
rowCount,
workSheet,
filename,
Environment.NewLine,
ex.Message);
// Reset the exception object
context.Properties["CurrentException"] = new
System.Exception(errorMessage);
Generating an XSD Schema
The Include Schema design time property can be used to generate an XSD Schema that represents the XML output of the Excel to XML Process Step. This can be useful validating the output within the Business Process at runtime or in other parts of the system using the Validate Schema Process Step.
When the Include Schema design time property is set to True, an XSD Schema will be pre pended to the output XML as shown below:
<?xml version="1.0" encoding="utf-16"?> <xs:schema id="Payments" xmlns="" xmlns:xs="https://www.w3.org/2001/XMLSchema" xmlns:msdata="urn:schemas-microsoft-com:xml-msdata"> <xs:element name="Payments"> <xs:complexType> <xs:choice minOccurs="0" maxOccurs="unbounded"> <xs:element name="Record"> <xs:complexType> <xs:sequence> <xs:element name="STUDY_NO" minOccurs="0"> <xs:simpleType> <xs:restriction base="xs:string"> <xs:maxLength value="510"/> </xs:restriction> </xs:simpleType> </xs:element> <xs:element name="COUNTRY_CODE" minOccurs="0"> <xs:simpleType> <xs:restriction base="xs:string"> <xs:maxLength value="510"/> </xs:restriction> </xs:simpleType> </xs:element> <xs:element name="RANK_NO" type="xs:double" minOccurs="0"/> <xs:element name="CREDIT" type="xs:double" minOccurs="0"/> <xs:element name="LAST_NAME" minOccurs="0"> <xs:simpleType> <xs:restriction base="xs:string"> <xs:maxLength value="510"/> </xs:restriction> </xs:simpleType> </xs:element> <xs:element name="FIRST_NAME" minOccurs="0"> <xs:simpleType> <xs:restriction base="xs:string"> <xs:maxLength value="510"/> </xs:restriction> </xs:simpleType> </xs:element> <xs:element name="REFERENCE_NO" minOccurs="0"> <xs:simpleType> <xs:restriction base="xs:string"> <xs:maxLength value="510"/> </xs:restriction> </xs:simpleType> </xs:element> <xs:element name="ORG_NAME" minOccurs="0"> <xs:simpleType> <xs:restriction base="xs:string"> <xs:maxLength value="510"/> </xs:restriction> </xs:simpleType> </xs:element> <xs:element name="ORG_ADDRESS" minOccurs="0"> <xs:simpleType> <xs:restriction base="xs:string"> <xs:maxLength value="510"/> </xs:restriction> </xs:simpleType> </xs:element> <xs:element name="CITY" minOccurs="0"> <xs:simpleType> <xs:restriction base="xs:string"> <xs:maxLength value="510"/> </xs:restriction> </xs:simpleType> </xs:element> <xs:element name="STATE" minOccurs="0"> <xs:simpleType> <xs:restriction base="xs:string"> <xs:maxLength value="510"/> </xs:restriction> </xs:simpleType> </xs:element> <xs:element name="ZIP" minOccurs="0"> <xs:simpleType> <xs:restriction base="xs:string"> <xs:maxLength value="510"/> </xs:restriction> </xs:simpleType> </xs:element> <xs:element name="PAYEE" minOccurs="0"> <xs:simpleType> <xs:restriction base="xs:string"> <xs:maxLength value="510"/> </xs:restriction> </xs:simpleType> </xs:element> <xs:element name="PAYMENT" type="xs:double" minOccurs="0"/> <xs:element name="PAYMENT_DATE" type="xs:dateTime" minOccurs="0"/> <xs:element name="CORRECTION" minOccurs="0"> <xs:simpleType> <xs:restriction base="xs:string"> <xs:maxLength value="510"/> </xs:restriction> </xs:simpleType> </xs:element> <xs:element name="PAYMENT_TYPE" minOccurs="0"> <xs:simpleType> <xs:restriction base="xs:string"> <xs:maxLength value="510"/> </xs:restriction> </xs:simpleType> </xs:element> <xs:element name="_RowNumber" type="xs:int" minOccurs="0"/> </xs:sequence> </xs:complexType> </xs:element> </xs:choice> </xs:complexType> </xs:element> </xs:schema> <Payments> <Record> <STUDY_NO>D6898</STUDY_NO> <COUNTRY_CODE>USA</COUNTRY_CODE> <RANK_NO>1</RANK_NO> <CREDIT>3880</CREDIT> <LAST_NAME>Jones</LAST_NAME> <FIRST_NAME>John</FIRST_NAME> <REFERENCE_NO>001</REFERENCE_NO> <ORG_NAME>RD Development, LP</ORG_NAME> <ORG_ADDRESS>878 Turner Center Drive</ORG_ADDRESS> <CITY>Bustin</CITY> <STATE>TX</STATE> <ZIP>79744</ZIP> <PAYEE>RD Development, LP </PAYEE> <PAYMENT>815200.05</PAYMENT> <PAYMENT_DATE>2017-07-15T00:00:00-07:00</PAYMENT_DATE> <CORRECTION>No</CORRECTION> <PAYMENT_TYPE>CC</PAYMENT_TYPE> <_RowNumber>1</_RowNumber> </Record> <Record> <STUDY_NO>D6898</STUDY_NO> <COUNTRY_CODE>USA</COUNTRY_CODE> <RANK_NO/> <CREDIT>6894</CREDIT> <LAST_NAME>Jones</LAST_NAME> <FIRST_NAME>Mark</FIRST_NAME> <REFERENCE_NO>001</REFERENCE_NO> <ORG_NAME>NBC Clinical Pharmacology Center</ORG_NAME> <ORG_ADDRESS>900 East Baltimore Street</ORG_ADDRESS> <CITY>Baltimore</CITY> <STATE>MD</STATE> <ZIP>21301</ZIP> <PAYEE>NBC Clinical Pharmacology Center </PAYEE> <PAYMENT>368489.92</PAYMENT> <PAYMENT_DATE>2017-07-15T00:00:00-07:00</PAYMENT_DATE> <CORRECTION>No</CORRECTION> <PAYMENT_TYPE>CC</PAYMENT_TYPE> <_RowNumber>2</_RowNumber> </Record> </Payments>
This property should only be set to True during development to retrieve the XSD Schema, if one is needed. Usually this would be done by running a test within the Business Process Designer, capturing the output using a Trace Process Step or Audit Process Step, and then copying the XSD portion into the Neuron ESB Schema Repository.
For batch processing scenarios, it is usually desirable to validate the individual records separately from the original XML message (batch message). In those cases, the XSD Schema can be broken into two schemas, one designed to Validate the batch envelope, the other to validate the individual records. For example, the XSD Schema to validate the batch envelope would look like the following, using the ANY XSD Schema element to handle the records (highlighted in bold):
<?xml version="1.0" encoding="UTF-8"?> <xs:schema id="Payments" xmlns:msdata="urn:schemas-microsoft-com:xml-msdata" xmlns:xs="https://www.w3.org/2001/XMLSchema"> <xs:element name="Payments"> <xs:complexType> <xs:choice maxOccurs="unbounded" minOccurs="1"> <xs:element name="Record"> <strong style="font-weight: bold;"> <em style="font-style: italic;"> <xs:complexType> <xs:sequence maxOccurs="unbounded" minOccurs="0"> <xs:any processContents="skip"></xs:any> </xs:sequence> </xs:complexType> </em> </strong> </xs:element> </xs:choice> </xs:complexType> </xs:element> </xs:schema>
Whereas the XSD Schema for validating individual records would appear as:
<?xml version="1.0" encoding="UTF-8"?> <xs:schema id="Payments" xmlns:msdata="urn:schemas-microsoft-com:xml-msdata" xmlns:xs="https://www.w3.org/2001/XMLSchema"> <xs:element name="Record"> <xs:complexType> <xs:choice maxOccurs="unbounded" minOccurs="0"> <xs:sequence> <xs:element minOccurs="0" name="STUDY_NO"> <xs:simpleType> <xs:restriction base="xs:string"> <xs:maxLength value="510"></xs:maxLength> </xs:restriction> </xs:simpleType> </xs:element> <xs:element minOccurs="0" name="COUNTRY_CODE"> <xs:simpleType> <xs:restriction base="xs:string"> <xs:maxLength value="510"></xs:maxLength> </xs:restriction> </xs:simpleType> </xs:element> <xs:element minOccurs="0" name="RANK_NO" type="xs:double"></xs:element> <xs:element minOccurs="0" name="CREDIT" type="xs:double"></xs:element> <xs:element minOccurs="0" name="LAST_NAME"> <xs:simpleType> <xs:restriction base="xs:string"> <xs:maxLength value="510"></xs:maxLength> </xs:restriction> </xs:simpleType> </xs:element> <xs:element minOccurs="0" name="FIRST_NAME"> <xs:simpleType> <xs:restriction base="xs:string"> <xs:maxLength value="510"></xs:maxLength> </xs:restriction> </xs:simpleType> </xs:element> <xs:element minOccurs="0" name="REFERENCE_NO"> <xs:simpleType> <xs:restriction base="xs:string"> <xs:maxLength value="510"></xs:maxLength> </xs:restriction> </xs:simpleType> </xs:element> <xs:element minOccurs="0" name="ORG_NAME"> <xs:simpleType> <xs:restriction base="xs:string"> <xs:maxLength value="510"></xs:maxLength> </xs:restriction> </xs:simpleType> </xs:element> <xs:element minOccurs="0" name="ORG_ADDRESS"> <xs:simpleType> <xs:restriction base="xs:string"> <xs:maxLength value="510"></xs:maxLength> </xs:restriction> </xs:simpleType> </xs:element> <xs:element minOccurs="0" name="CITY"> <xs:simpleType> <xs:restriction base="xs:string"> <xs:maxLength value="510"></xs:maxLength> </xs:restriction> </xs:simpleType> </xs:element> <xs:element minOccurs="0" name="STATE"> <xs:simpleType> <xs:restriction base="xs:string"> <xs:maxLength value="510"></xs:maxLength> </xs:restriction> </xs:simpleType> </xs:element> <xs:element minOccurs="0" name="ZIP"> <xs:simpleType> <xs:restriction base="xs:string"> <xs:maxLength value="510"></xs:maxLength> </xs:restriction> </xs:simpleType> </xs:element> <xs:element minOccurs="0" name="PAYEE"> <xs:simpleType> <xs:restriction base="xs:string"> <xs:maxLength value="510"></xs:maxLength> </xs:restriction> </xs:simpleType> </xs:element> <xs:element minOccurs="0" name="PAYMENT" type="xs:double"></xs:element> <xs:element minOccurs="0" name="PAYMENT_DATE" type="xs:dateTime"></xs:element> <xs:element minOccurs="0" name="CORRECTION"> <xs:simpleType> <xs:restriction base="xs:string"> <xs:maxLength value="510"></xs:maxLength> </xs:restriction> </xs:simpleType> </xs:element> <xs:element minOccurs="0" name="PAYMENT_TYPE"> <xs:simpleType> <xs:restriction base="xs:string"> <xs:maxLength value="510"></xs:maxLength> </xs:restriction> </xs:simpleType> </xs:element> <xs:element minOccurs="0" name="_RowNumber" type="xs:int"></xs:element> </xs:sequence> </xs:choice> </xs:complexType> </xs:element> </xs:schema>
Number of rows returned
The Number of Rows design time property controls the number of records/rows that will be returned in the XML output retrieved from the original Excel Worksheet after the WHERE clause (if provided) is evaluated. By default, the value of the property is -1, which would return all the rows after the WHERE clause is evaluated.
Post Processing
The Excel to XML will produce the output XML, setting it as the body of the existing Neuron ESB Message. With that, it will also set a number of custom message properties (listed in the table below) that can be used at runtime, providing meta data to the operations that may be performed on the XML. This includes the name of the Excel Worksheet, the file name of the Excel Workbook, the number of rows actually included in the XML from the Worksheet as well as information about the data structure of the XML (i.e. namespace, root node name, row record name).
The prefix for all Excel to XML custom message properties it exceltoxml and they can be accessed directly from the Neuron ESB Message object using the GetProperty() or GetProperties() methods. All Neuron ESB Message properties can also be set using the Set Property Process Step.
Neuron ESB Message Properties
| Process Step | Processing | Custom Property (i.e. prefix.name) | Description |
| Excel to XML | Pre/Post | exceltoxml.Filename | Optional. The user can set this. This should represent the name of the original Excel file that is processed by the Excel to XML Process Step. If a File, SFTP, FTPS or FTP adapter originally consumed the Excel file, this property will be populated by their respective Filename property. If the value is not provided by the user or the adapters, it will be set with the temporary file that neuron ESB generates during processing. This is purely for informational purposes. |
| Post | exceltoxml.WorkSheet | Read-only. Will contain the name of the Worksheet processed by the Process Step. Directly mapped to the Excel Worksheet design time property | |
| Post | exceltoxml.TargetNamespace | Read-only. Will contain the name of the Target Namespace value used to generate the XML output. Directly mapped to the TargetNamespace design time property. If not provided at design time, it will be populated with the default value of the underlying Dataset objects Namespace property. | |
| Post | exceltoxml.RootName | Read-only. Will contain the name of the Root Node value used to generate the XML output. Directly mapped to the Root Node Name design time property. | |
| Post | exceltoxml.RowName | Read-only. Will contain the name of the Row Node value used to generate the XML output. Directly mapped to the Row Node Name design time property. If not provided at design time, it will be populated with the default value of the underlying Dataset objects TableName property | |
| Post | exceltoxml.RowsReturned | Read-only. The number of rows returned in the XML Output |
Dynamic Configuration
The Excel to XML Step provides the Filename property that can be set at runtime to provide a user with the name of the Excel Workbook that sourced the final output XML. This is strictly informational and is not used by the Process Step. If this is not provided, the Process Step will auto populate this property with the Filename custom message property populated by either the File, FTP, FTPS or SFTP adapter endpoint (assuming that the Excel file was originally consumed through one of them). If these properties do not exist on the existing Neuron ESB Message, than the temporary file name used to process the Excel Worksheet will be used.
The Filename property can be set within a C# Code Step.
context.Data.SetProperty("exceltoxml", "Filename", "Payments.xls");
| Process Step | Custom Property (i.e. prefix.name) | Design-time Property |
| Excel to XML | exceltoxml.Filename | N/A |
Installation Requirements
The Excel to XML Process Step uses ODBC to translate Microsoft Excel documents into XML. To use this Process Step, the Microsoft Access Database Engine Redistributable must be installed. This in turn will install the necessary Microsoft Excel ODBC drivers that the Process Step uses.
The Microsoft Access Database Engine Redistributable is available in 64 and 32 bit installations and can be downloaded using the following link:
https://www.microsoft.com/en-us/download/details.aspx?id=13255
Once installed, open the ODBC Data Source Administrator utility to validate that the drivers have been installed. The ODBC Data Source Administrator comes in both a 32 and 64-bit version. Displayed below is the 32 bit version:
There are no other dependencies.
Design Time Properties
| Name | Dynamic | Description |
| Name | User provided name for the Process Step. Will replace default name of Step when placed on the Design Canvas. | |
| Disable | Boolean flag to determine whether the step should be executed at runtime or design time.
NOTE: Also available from the right-click context menu.
| |
| Bindings | Launches the Binding Expressions dialog for specifying Environment Variables. | |
| Excel 2007 or Greater | Required. True or False. Default value is False. Used to indicate which version of Microsoft Excel the Worksheet to be processed was produced from. | |
| Excel Worksheet | Required. Name of the Excel Worksheet to return data from and convert to XML. If this is not supplied, the first Excel Worksheet within the Excel Workbook will be used. | |
| Column(s) Constraint | Optional. ANSI SQL style ‘WHERE’ Clause i.e. ‘Site_No > 0 OR Country_Code = ‘USA”. Must not include ‘WHERE’ and must not be enclosed in quotes. | |
| Exclude NULL Fields | Required. True or False. Default value is False. Set to ‘True’ to exclude a Field within a row from the XML document if the value of that field equals NULL. | |
| Add Row Numbers | Required. True or False. Default value is False. True to add row numbers. Appends a new Field within each row in the XML document containing the row position. Row numbering starts at 1. | |
| Target Namespace | Optional. Target Namespace used for returned XML document. | |
| Root Node Name | Required. Name of the Root XML element node that will enclose all rows. | |
| Row Node Name | Optional. Name of the XML element that will contain all the fields of the row. | |
| Include Schema | Required. True or False. Default value is False. If set to True, an XSD Schema will be prepended to the output XML. | |
| Number of Rows | Required. Default value is -1. -1 indicates a return of all Rows that meet the Column Constraint WHERE clause (if provided). |
Sample
In the Sample below, the process demonstrates the use of the Excel to XML Process Step to receive an incoming binary Excel Spreadsheet, convert it to XML, validate and then batch split it so that each individual record can be processed on its own thread, increasing concurrency and throughput. The Split Process Step is configured to perform an Asynchronous Split using 20 threads. If an exception occurs processing any record, it is caught and the information regarding the exception as well as the Worksheet and row number that caused the error is reported in Neuron ESB Failed Messages Report.
The parent Process, Payment Batch Processing, is responsible for converting the Excel Worksheet into XML. The XML batch message is validated against an XSD Schema generated by the Process Step. The Execute Process Step is then used to call a child Process, Payment Processor, which captures some meta data and then uses the Split Process Step, allowing each individual record to be processed on a dedicated thread and validated by an XSD Schema. It is in this Process where individual record exceptions can be caught and reported.
The Payment Batch Processing Process can be tested in the Business Process Designer by clicking the Test button on the toolbar, launching the Edit Test Message form (displayed below). The Load File toolbar button can be used to select the Excel Worksheet to load into the dialog. Additionally, the exceltoxml.Filename custom Neuron ESB Message property is populated with the name of the Excel Workbook, so its value can be used later in the Process.
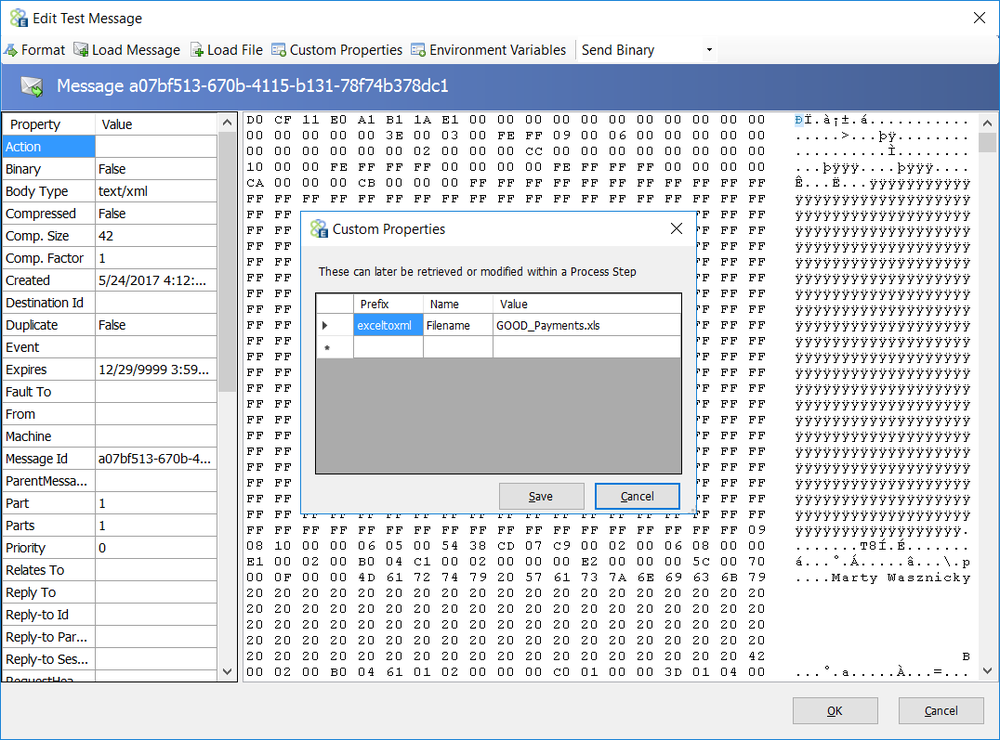
If an error occurs during the processing of a record, it would be captured and reported to the Failed Messages report by using the Audit Step. By enriching the exception with the existing metadata populated by the Excel to XML Process Step, a more valuable error message will be captured and displayed to the user as indicted in the screen shot of the Failed Message Viewer below:
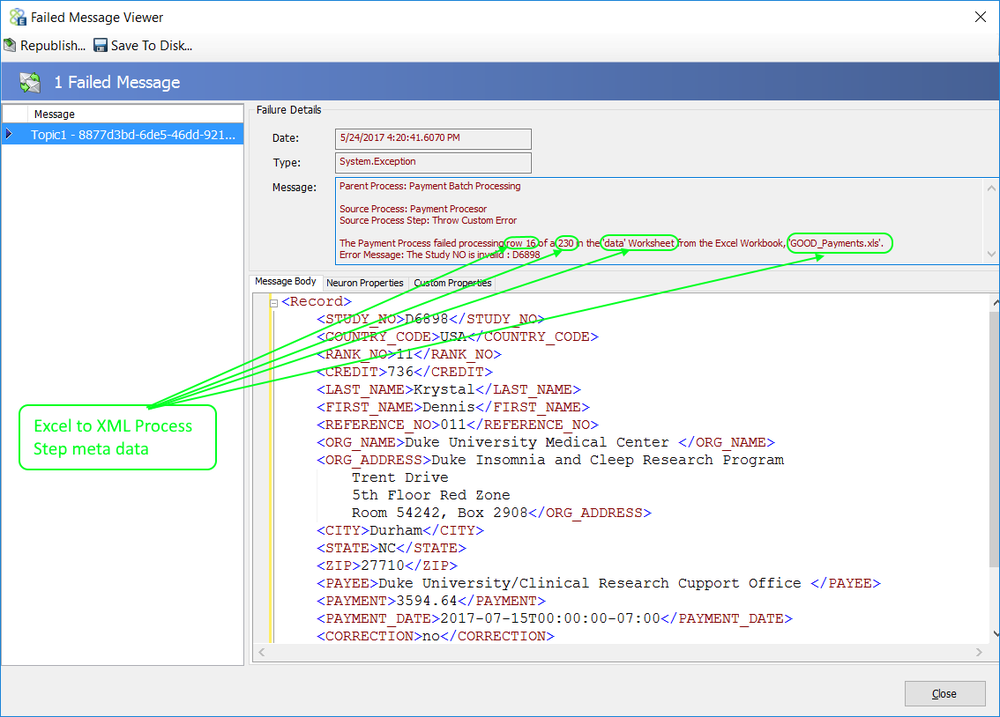
Flat File to Xml
| Category: | Message |
| Class: | FlatFileParserStep |
| Namespace: | Neuron.Esb.Pipelines |
| Assembly: | Neuron.Esb.Pipelines.dll |
Description:
The Flat File to Xml Process Step is a flat file parser that is used to convert single record format flat files into XML or JSON. The supported flat files must have the following attributes:
- Fixed-width or delimited. The following delimiters are supported:
- Comma
- Tab
- Vertical Bar (otherwise known as Pipe-Delimited)
- Semicolon
- Custom string (any combination of characters)
- All records in the flat file must conform to the same definition. The only exception to this are leading records and trailing records, which can be ignored.
Fixed width and delimited files are commonly received through File, FTP, FTPS, SFTP interfaces or Queuing technologies like IBM MQSeries when integrating external business partners or legacy systems. Once received, this information often needs to be processed and de-composed to update other systems or participate in various business-processing scenarios. The Flat File to Xml Process Step is used to translate and normalize this information into an XML structure that can be easily consumed by participating systems.
The Flat File to Xml Step launches a Wizard that walks a user through creating a Flat File Definition. The Definition contains all the instructions and properties that are used by the Flat File Parser (runtime engine) to translate incoming files to XML structures (i.e. type of delimiter, field names, lines to process, width size, data types, etc.). Although XML is the default document output type, JSON can be produced instead by modifying the Output Document Type property in the Steps property grid. The following is an example of a comma delimited file where the column names are included as the first row:
COMPANY,VENDOR,INVOICE,DIST-SEQ-NBR,ORIG-TRAN-AMT 0060, 1012091,614581478 ,0,000000005062.07 0060, 1012091,614581478 ,0,000000000363.11 0060, 1012091,614581478 ,0,000000000174.41 0060, 1012091,614581478 ,0,000000000262.07 0060, 1012091,614581478 ,0,000000000031.34 0001, 1001137,139364 ,0,000000000255.58 0001, 1001137,139364 ,0,000000000016.46
Using the Flat File Wizard, a Definition can be created that will convert the data above into the normalized XML Structure shown below:
<Payments xmlns="https://www.ordersrus.com/payments"> <Invoice> <COMPANY>0060</COMPANY> <VENDOR>1012091</VENDOR> <INVOICE>614581478</INVOICE> <DIST_SEQ_NBR>0</DIST_SEQ_NBR> <ORIG_TRAN_AMT>5062.07</ORIG_TRAN_AMT> </Invoice> <Invoice> <COMPANY>0060</COMPANY> <VENDOR>1012091</VENDOR> <INVOICE>614581478</INVOICE> <DIST_SEQ_NBR>0</DIST_SEQ_NBR> <ORIG_TRAN_AMT>363.11</ORIG_TRAN_AMT> </Invoice> </Payments>
If JSON is selected for the Output Document Type, the following will be produced:
{
"Payments": {
"@xmlns": "https://payments.org/invoices",
"Invoice": [
{
"COMPANY": "60",
"VENDOR": "1012091",
"INVOICE": "614581478",
"DIST_SEQ_NBR": "0",
"ORIG_TRAN_AMT": "5062.07"
},
{
"COMPANY": "60",
"VENDOR": "1012091",
"INVOICE": "614581478",
"DIST_SEQ_NBR": "0",
"ORIG_TRAN_AMT": "363.11"
}
]
}
}
Optionally, based on user selected options the following XSD Schema can be generated for the XML Structure in case XSD Schema validation is required in the Business Process:
<xs:schema attributeFormDefault="qualified" elementFormDefault="qualified" id="Payments" targetNamespace="https://www.ordersrus.com/payments" xmlns="https://www.ordersrus.com/payments" xmlns:msdata="urn:schemas-microsoft-com:xml-msdata" xmlns:mstns="https://www.ordersrus.com/payments" xmlns:xs="https://www.w3.org/2001/XMLSchema"> <xs:element name="Payments"> <xs:complexType> <xs:choice maxOccurs="unbounded" minOccurs="0"> <xs:element name="Invoice"> <xs:complexType> <xs:sequence> <xs:element minOccurs="0" name="COMPANY" type="xs:string"></xs:element> <xs:element minOccurs="0" name="VENDOR" type="xs:int"></xs:element> <xs:element minOccurs="0" name="INVOICE" type="xs:int"></xs:element> <xs:element minOccurs="0" name="DIST_SEQ_NBR" type="xs:int"></xs:element> <xs:element minOccurs="0" name="ORIG_TRAN_AMT" type="xs:double"></xs:element> </xs:sequence> </xs:complexType> </xs:element> </xs:choice> </xs:complexType> </xs:element> </xs:schema>
Creating a Flat File Definition
The Flat File to Xml Step includes a wizard that assists users in creating the Flat File Definition. The Definition cannot be created without using the wizard. Definitions can be created either from scratch or by using a sample Flat File. Sample Flat Files can be imported into the Neuron ESB Text Document Repository located by navigating to Repository->Documents->Text Documents within the Neuron ESB Explorer or, can be retrieved directly from the file system. Once created, the definition is stored as a set of hidden properties of the Flat File to Xml Process Step.
Launching the Flat File Wizard
To start the wizard, right-click on the Flat File to Xml Process Step in the Business Process Designer and select Flat File Wizard right click context menu as shown below:
The wizard can also be started by double clicking on the icon with the computers mouse. This will display the following Welcome page of the wizard:
Clicking the Next button will navigate the user to the Flat File Type page of the wizard:
Flat File Types
The Flat File Wizard is designed to work with Fixed Width or Delimited (including CSV) flat files. The primary difference between working with both is that the user must define exactly where the column breaks are located with Fixed Width formatted files.
Fixed Width
Fixed Width Flat Files are different from Delimited Flat Files in so far that a set number of spaces or tabs separates each column, limiting each field in length. There is no requirement that the distance between each column in a Flat File be the same. Below are some examples of Fixed Width Flat Files that can be parsed by the wizard, the first without column names, the second that includes column names as the first row:
Jim Glynn someone_j@example.com Coho Winery 555-0109 Maria Campbell someone_d@example.com Fabrikam Inc. 555-0103 Nancy Anderson someone_c@example.com Adventure Works 555-0102 Patrick Sands someone_k@example.com Alpine Ski House 555-0110 Paul Cannon someone_h@example.com Alpine Ski House 555-0107
With column names:
Name Address City StZip PhoneNumber Joe Hare 21515 NE Alder Crest Dr. Redmond WA98053425-941-0457 Josh Hare 11317 165th Ct. NE Redmond WA98052425-869-1050
On the Flat File Type page, select the Fixed Width option and click the Next button to display the Fixed Width Flat File page of the wizard as displayed below:
The Fixed Width Flat File page displays options for creating a user defined Flat File Definition or, creating a Flat File Definition by using a sample document loaded directly from the file system or from the Neuron ESB Explorers Text Documents Repository. In the following example, well load the sample document directly from the repository:
As seen in the previous screen shot, the sample file is loaded from the repository by, selecting the Repository radio button and selecting a document from the list. The selected document is used to populate the lower preview pane with the first 10 rows.
Some flat files include column header names in the first line/row. If the flat file includes column headers, check the box for First Row Contains Column Names. Also, if the Flat File Parser needs to ignore any of the leading or trailing rows, indicate how many of each row to ignore. This would generally be used if the flat file contained headers or footers.
When parsing a fixed width file column break locations must be provided. To set a column break, click anywhere in the preview pane and a vertical line will appear. Click the line again and it will disappear. Note you dont have to click on the ruler above the preview pane, just click inside the preview pane:
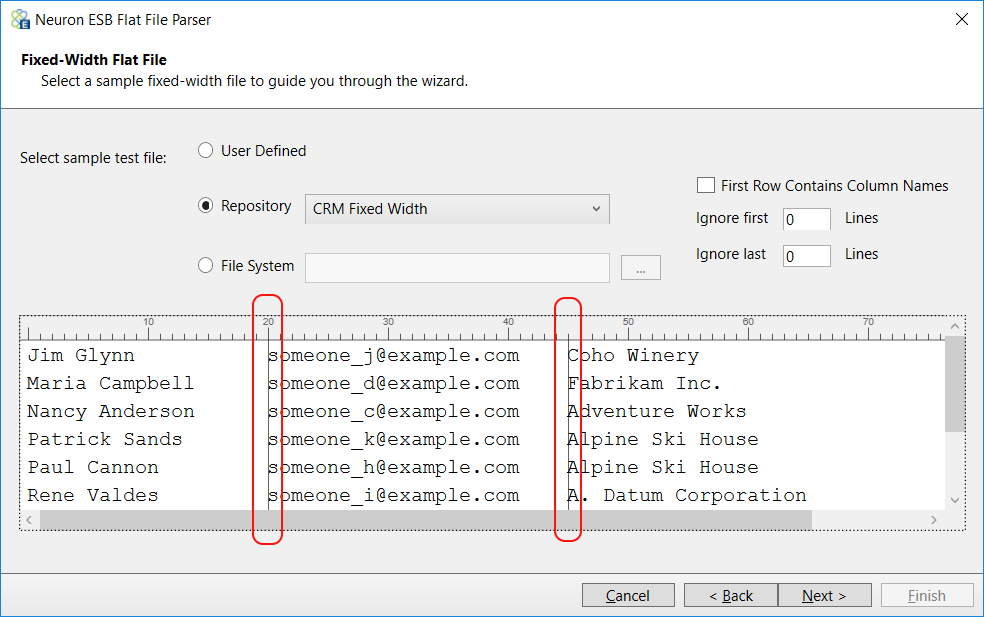
Once the columns are set, clicking the Next button will navigate the user to the Column Details page of the wizard. This page can be used to either create column names or rename existing default column names. If column names were not already provided in the sample and the First Row Contains Names option was not checked, column names will be auto created for the sample in the format of Field1, Field2, Field3, and so on. This page also allows users to define Trim options, Optional Fields and Data Types. As entries are made, the changes will be visible in the preview pane. When parsing Fixed Width files, this page can be used to adjust the Start Index and Width of each column. In the image below, Field1 is renamed to Name, Field2 to EmailAddress, Field3 to CompanyName and Field4 to Phone:
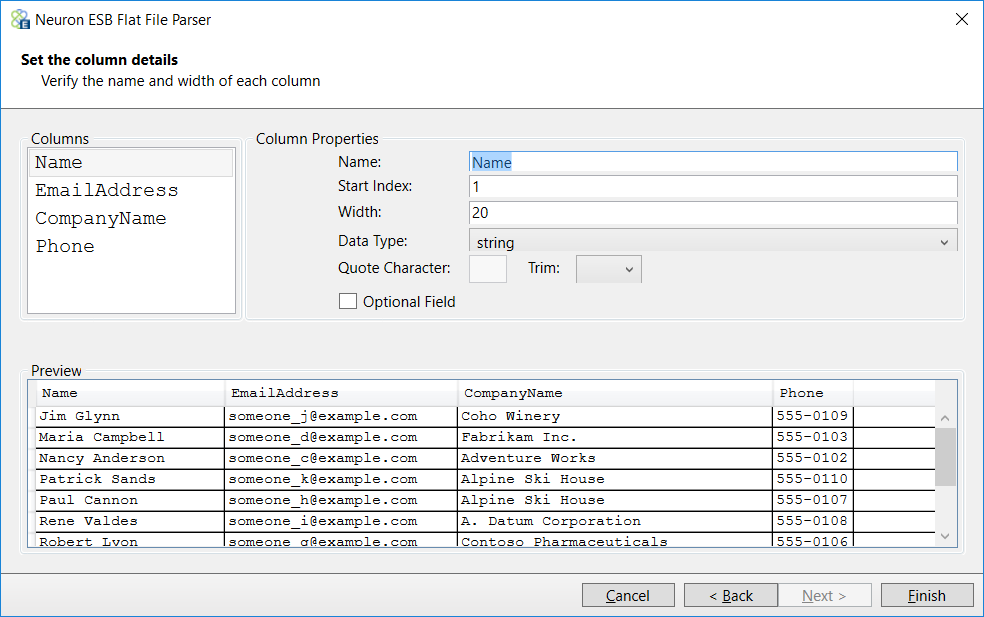
When creating a Flat File Definition using sample documents, the Start Index and Width properties of each column is automatically calculated when column breaks are set on the preceding Fixed Width Flat File page of the wizard. Users should only have to set these properties if the User Defined option is selected.
After finishing the wizard (clicking the Finish button), the Flat File Definition is stored as a Process Step property. The wizard can be launched and rerun again to view or edit the existing Flat File Definition.
To finalize the structure of the xml that the Flat File Parser will produce when processing the flat file, the Root Element Name, Row Element Name and Namespace can be modified in the Process Steps property page as shown below:
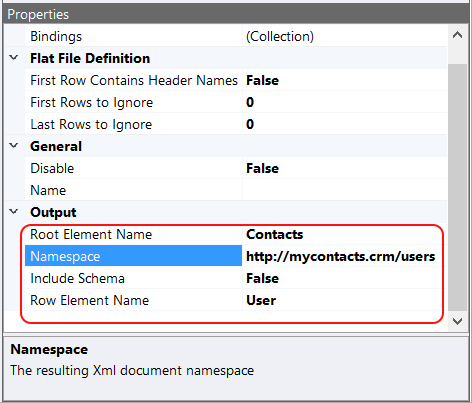
The Flat File Definition can be tested using the Business Process Designer, which will produce the following output in the Trace window:
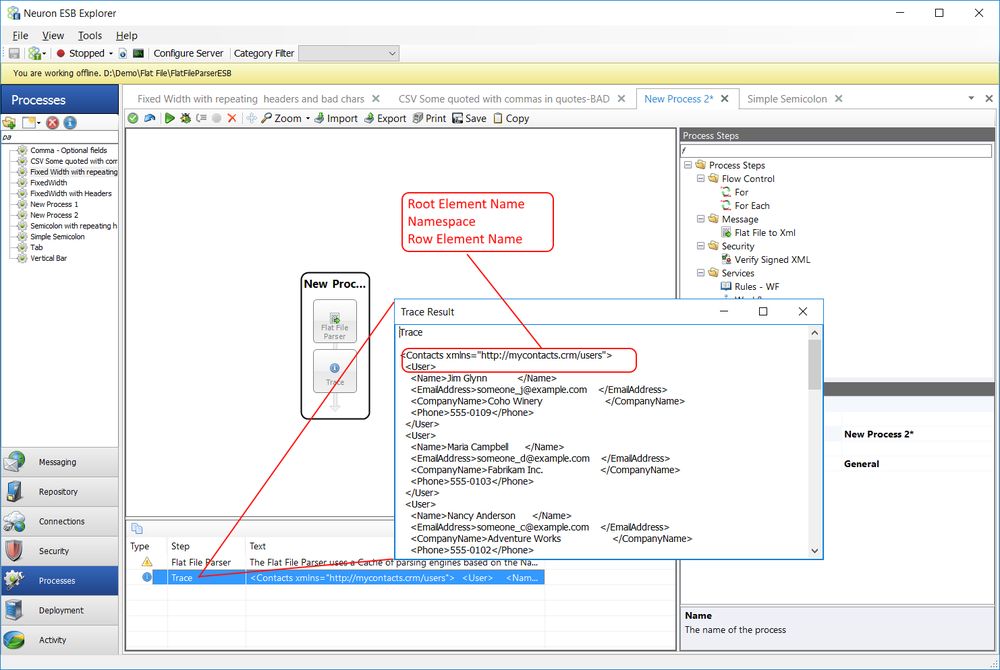
Delimited
The Flat File to XML Wizard can process CSV and Delimited files by choosing the Delimited option on the Flat File Type page of the wizard. The difference between CSV and Delimited files are:
- CSV filesinclude both a delimiter and an optional enclosing character.
- A delimiter separates the data fields. It is usually a comma, but can also be a pipe, a tab, or any single value character.
- An enclosing character occurs at the beginning and the end of a value. It is called a Quote Character (because it is usually double quotes), but also supports other characters.
- Delimited filesonly have a delimiter; an enclosing character is not used.
Compared to Fixed Width Flat Filesthat use spaces to force every field to the same width, aDelimited/CSV filehas the advantage of allowing field values of any length.
The Flat File Type page allows users to either Comma, Tab, Semicolon, Vertical Bar (Pipe) or a custom defined set of characters as field delimiters. Below are some examples of Delimited Flat Files that can be parsed by the wizard:
Using Vertical Bar as delimiter:
Joe Hare|24415 NW Alder Crest Dr.|Redmond|WA|98053|425-789-0457 Josh Hare|14417 145th Ct. NE|Redmond|WA|98052|425-456-1050
Using Semicolon as delimiter:
Joe Hare;24415 NW Alder Crest Dr.;Redmond;;98053;425-789-0457 Josh Hare;14417 145th Ct. NE;Redmond;;98052;425-456-1050
With Quote Character:
20080,1014631,Heritage Electrical Services,07/19/2016,1607182,830.00,USD,200800001,800054,07/19/2016 01053,1003276,Massglass & Door Facilities Ma,08/01/2016,221286,436.25,USD,010530006,800070,08/22/2016 20102,1013681,"FIVE STAR REFRIGERATION, INC",07/29/2016,2910, "1,786.86",USD,201020002,800062,07/29/2016
With column names and Quote Character:
COMPANY,VENDOR,INVOICE,DIST-SEQ-NBR,ORIG-TRAN-AMT 0060, 1012091,614581478 ,0,"000000005,062.07" 0060, 1012091,614581478 ,0,"000000000363.11" 0060, 1012091,614581478 ,0,"000000000174.41" 0060, 1012091,614581478 ,0,"000000067,262.07" 0060, 1012091,614581478 ,0,"000000000031.34" 0001, 1001137,139364 ,0,"000000002,255.58" 0001, 1001137,139364 ,0,"000000000016.46"
On the Flat File Type page, select the Delimiter option and click the Next button to display the Delimiter Flat File page of the wizard as displayed below:
The Delimited Flat File page displays options for creating a user defined Flat File Definition or, creating a Flat File Definition by using a sample document loaded directly from the file system or from the Neuron ESB Explorers Text Documents Repository. In the following example, well load a sample document directly from the repository which includes column names and quoted fields:
Unlike working with Fixed Width Flat Files, column break lines do need to be set. Using the sample above, column names are included, requiring that the First Row Contains Column Names to be checked. What is also visible is that the ORIG-TRAN-AMT column values are enclosed in double quotes (Quote Character). After all the options have been selected, clicking on the Next button would display the following warning:
This indicates that the wizard has detected more delimiters in a row than there are column names. To resolve this, the wizard has to be directed to use a Quoted Character for the fifth column, ORIG-TRAN-AMT. This can be accomplished by temporarily selecting the User Defined option, followed by clicking the Next button. Depending on what was selected, either the column names listed in the sample file will be listed or generic field names (i.e. Field1, Field2, etc.):
Once the Column Details page appears, click on either Field5 or the ORIG_TRAN_AMT column (depending on what is visible) and enter a double quote in the Quote Character text box and hit enter, followed by clicking the Back button. This will display the Delimited Flat File page of the Wizard. The sample file and options previously selected should be visible. Lastly, navigate back to the Column Details page by hitting Next. The Column Details preview should be displayed correctly, without generating the warning message previously encountered as shown below:
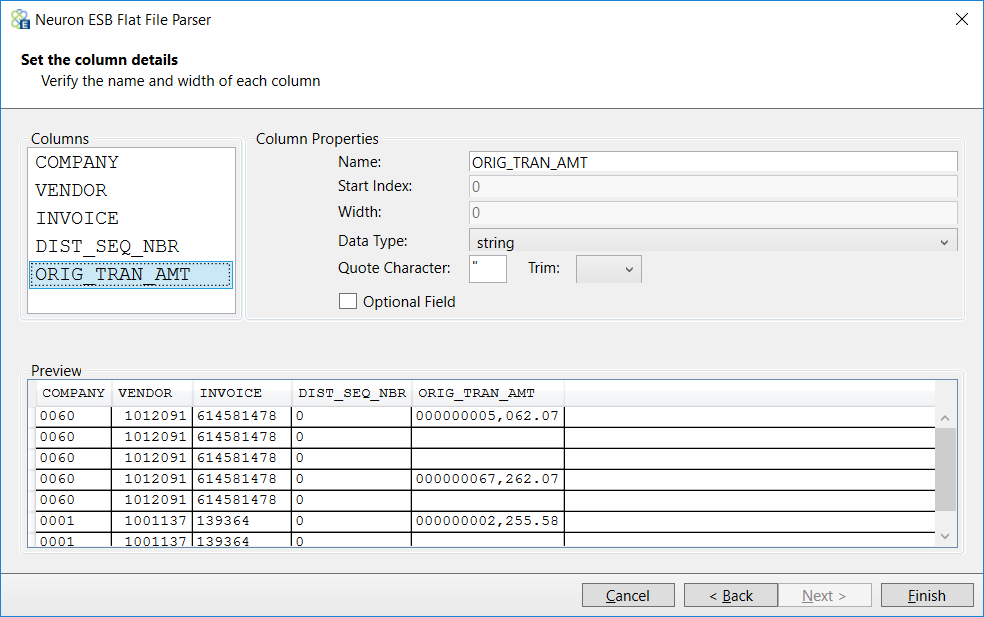
Similar to the Fixed Width process, If column names were not provided in the sample or this was a user defined Flat File Definition, column names can be created or renamed. This page allows users to define Trim options, Optional Fields and Data Types. As entries are made, the changes will be visible in the preview pane. Unlike Fixed Width flat files, the Start Index and Width properties are disabled when processing Delimited files.
Delimited Flat File Definitions can be tested in the Business Process Designer just like Fixed Width Flat File Definitions.
To finalize the structure of the xml that the Flat File Parser will produce when processing the flat file, the Root Element Name, Row Element Name and Namespace can be modified in the Process Steps property page as shown below:
The Flat File Definition can be tested using the Business Process Designer, which will produce the following XML output:
<Payments xmlns="https://payments.org/invoices"> <Invoice> <COMPANY>0060</COMPANY> <VENDOR>1012091</VENDOR> <INVOICE>614581478</INVOICE> <DIST_SEQ_NBR>0</DIST_SEQ_NBR> <ORIG_TRAN_AMT>000000005,062.07</ORIG_TRAN_AMT> </Invoice> <Invoice> <COMPANY>0060</COMPANY> <VENDOR>1012091</VENDOR> <INVOICE>614581478</INVOICE> <DIST_SEQ_NBR>0</DIST_SEQ_NBR> <ORIG_TRAN_AMT>000000000363.11</ORIG_TRAN_AMT> </Invoice> </Payments>
User Defined Definitions
The User Defined option can be selected on the Flat File (Delimiter or Fixed Width) wizard page when a sample document is not available to use to create or validate a Flat File Definition.
This option can also be useful when creating Flat File Definitions for flat files with optional fields or for delimited flat files with quoted fields and the quoted field will contain the delimiter. For example, using a flat comma-separated file with these three fields: 1234,Neuron,Neudesic, LLC. If a sample file with this data is used, the Flat File Parser will read that as four fields. To create a Flat File Definition that can parse the data correct, select the User Defined option as shown below:
Clicking on the Next button will display the Column Details page where column names can be manually entered using the right-click context menu of the Columns list box. Select Add to manually add the fields as shown below:
After adding the first column, the right-click context menu provides the following options:
- Delete
- Add Before Selected Row
- Add After Selected Row
Once all the columns and their properties have been defined, clicking the Finish button will save the Flat File Definition. This can be tested normally like the previous samples within this document.
Schema Generation
The Include Schema design time property can be used to generate an XSD Schema that represents the XML output of the Flat File to Xml Process Step. This can be useful validating the output within the Business Process at runtime or in other parts of the system using the Validate Schema Process Step.
This property should only be set to True during development to retrieve the XSD Schema, if one is needed. Usually this would be done by running a test within the Business Process Designer, capturing the output using a Trace Process Step or Audit Process Step, and then copying the XSD portion into the Neuron ESB Schema Repository.
There are several elements of the Flat File Definition that control the output of the XSD Schema and XML. The remainder of this section will based on the flat file sample used in the Fixed Width section above:
COMPANY,VENDOR,INVOICE,DIST-SEQ-NBR,ORIG-TRAN-AMT 0060, 1012091,614581478 ,0,"000000005,062.07" 0060, 1012091,614581478 ,0,"000000000363.11" 0060, 1012091,614581478 ,0,"000000000174.41" 0060, 1012091,614581478 ,0,"000000067,262.07" 0060, 1012091,614581478 ,0,"000000000031.34" 0001, 1001137,139364 ,0,"000000002,255.58" 0001, 1001137,139364 ,0,"000000000016.46"
In an earlier section of the document, the sample above was used to generate a Flat File Definition. To finalize the structure of the xml that the Flat File Parser would produce when processing the flat file, the Root Element Name, Row Element Name and Namespace can be modified in the Process Steps property page as shown below:
Using the modified properties, the Flat File Definition produced the following XML output:

However, by default all the columns were set to use the string datatype, even though some were integers and doubles. Additionally, some fields had an extra trailing space. In the following example, the columns are modified changing some to integers and doubles, while trimming the spaces off others. The Data Type drop down list located on the Column Details page of the Wizard is populated with the basic data types defined in the .NET Framework. As shown below the columns have been reset to specifically to the following:
| Column Name | OLD Data Type | NEW Data Type | Trim Option |
| COMPANY | string | int | NONE |
| VENDOR | string | int | NONE |
| INVOICE | string | string | BOTH |
| DIST_SEQ_NBR | string | int | NONE |
| ORIG_TRAN_AMT | string | double | NONE |
This will result in the following output XML:

When the Include Schema design time property is set to True, an XSD Schema will be pre-pended to the output XML. The XSD Schema representing the xml will look like this.
<xs:schema attributeFormDefault="qualified" elementFormDefault="qualified" id="Payments" targetNamespace="https://payments.org/invoices" xmlns="https://payments.org/invoices" xmlns:msdata="urn:schemas-microsoft-com:xml-msdata" xmlns:mstns="https://payments.org/invoices" xmlns:xs="https://www.w3.org/2001/XMLSchema"> <xs:element name="Payments"> <xs:complexType> <xs:choice maxOccurs="unbounded" minOccurs="0"> <xs:element name="Invoice"> <xs:complexType> <xs:sequence> <xs:element minOccurs="0" name="COMPANY" type="xs:int"></xs:element> <xs:element minOccurs="0" name="VENDOR" type="xs:int"></xs:element> <xs:element minOccurs="0" name="INVOICE" type="xs:string"></xs:element> <xs:element minOccurs="0" name="DIST_SEQ_NBR" type="xs:int"></xs:element> <xs:element minOccurs="0" name="ORIG_TRAN_AMT" type="xs:double"></xs:element> </xs:sequence> </xs:complexType> </xs:element> </xs:choice> </xs:complexType> </xs:element> </xs:schema>
At runtime, the Flat File Parser will use the data types represented in the XSD Schema above to validate the incoming data during the parsing process.
Optional Fields
The Column Details page of the wizard provides an Optional Field check box. This is used to indicate that a column may not be present in the data being parsed. If a column is marked as an Optional Field in a Flat File Definition, all columns that follow it must also be marked as Optional Fields. For instance, in the previous sample there are a COMPANY, VENDOR, INVOICE, DIST_SEQ_NBR and ORIG_TRAN_AMT columns. Below is a modified source file for that sample:
COMPANY,VENDOR,INVOICE,DIST-SEQ-NBR,ORIG-TRAN-AMT 0060, 1012091,614581478 ,0 0060, 1012091,614581478 ,6 0060, 1012091,614581478 , 0060, 1012091,614581478 ,0 0060, 1012091,614581478 ,0 0001, 1001137,139364 ,0 0001, 1001137,139364 ,0
As indicated in the sample above, the delimiter (,) for the ORIG_TRAN_AMT column is missing. If the ORIG_TRAN_AMT column is not marked as an Optional Field, the following error will be reported by the Flat File Parser:
Delimiter ‘,’ not found after field ‘DIST_SEQ_NBR’ (the record has less fields, the delimiter is wrong or the next field must be marked as optional).
However, if the column is marked as an Optional Field, the following xml output will be generated with a default value used for the ORIG_TRAN_AMT column:
<Payments xmlns="https://www.ordersrus.com/payments"> <Invoice> <COMPANY>0060</COMPANY> <VENDOR>1012091</VENDOR> <INVOICE>614581478</INVOICE> <DIST_SEQ_NBR>0</DIST_SEQ_NBR> <ORIG_TRAN_AMT>0</ORIG_TRAN_AMT> </Invoice> <Invoice> <COMPANY>0060</COMPANY> <VENDOR>1012091</VENDOR> <INVOICE>614581478</INVOICE> <DIST_SEQ_NBR>6</DIST_SEQ_NBR> <ORIG_TRAN_AMT>0</ORIG_TRAN_AMT> </Invoice> </Payments>
Alternatively, if a delimiter for the ORIG_TRAN_AMT column is in place as shown below, then the field does not need to be marked as optional as the default value for its assigned data type will be used to populate the field in the XML output. In the case of a string data type and empty field element will be used. Lastly, missing field values in preceding columns will be replaced with their default data type values in the output xml.
COMPANY,VENDOR,INVOICE,DIST-SEQ-NBR,ORIG-TRAN-AMT 0060, 1012091,614581478 ,0, 0060, 1012091,614581478 ,6, 0060, 1012091,614581478 ,, 0060, 1012091,614581478 ,0, 0060, 1012091,614581478 ,0, 0001, 1001137,139364 ,0, 0001, 1001137,139364 ,0,
Engine Caching
The Flat File to Xml Process Step uses a cache of parsing engines based on the Name property of the Process Step. Therefore, the Name property of the Process Step must always be set if there is more than one Flat File to Xml Process Step being used in the same Business Process. If a Name is not provided, the following warning will be written to the Neuron ESB Log files
The current Flat File Parser Process Step does not have a value for its name property. If there is only one Flat File Parser process Step on the ‘New Process 1*’ Business Process then the correct parsing engine will be used. If there are more than one, and they are configured to use different Flat File Parsing definitions, the wrong engine will be used to parse incoming files. Please ensure that each Flat File Parser Process Step is assigned a unique name
The prefix for all Flat File to Xml custom message properties it flatfile and they can be accessed directly from the Neuron ESB Message object using the GetProperty() or GetProperties() methods. All Neuron ESB Message properties can also be set using the Set Property Process Step.
Neuron ESB Message Properties
| Process Step | Environment | Custom Property (i.e. prefix.name) | Description |
| Flat File to Xml | Runtime | flatfile.FirstRowHeaders | Directly maps to the First Row Contains Header Names property |
| Runtime | flatfile.FirstLinesToIgnore | Directly maps to the First Rows to Ignore property | |
| Runtime | flatfile.LastLinesToIgnore | Directly maps to the Last Rows to Ignore property | |
| Runtime | flatfile.RowsReturned | Read-only. The number of rows returned in the XML Output |
Dynamic Configuration
The Flat File to Xml Step allows for dynamically setting the First Row Contains Header Names, First Rows to Ignore and Last Rows to Ignore properties within a C# Process Step or by using the Set Property Process Step.
context.Data.SetProperty("flatfile", "FirstLinesToIgnore", "2");
| Process Step | Custom Property (i.e. prefix.name) | Design-time Property |
| Flat File to Xml | flatfile.FirstRowHeaders | Directly maps to the First Row Contains Header Names property |
| flatfile.FirstLinesToIgnore | Directly maps to the First Rows to Ignore property | |
| flatfile.LastLinesToIgnore | Directly maps to the Last Rows to Ignore property |
Design Time Properties
| Name | Dynamic | Description |
| Name | User provided name for the Process Step. Will replace default name of Step when placed on the Design Canvas. If more than one Flat File to Xml Process Step is used within a Business Process, a unique Name must be provided. | |
| Disable | Boolean flag to determine whether the step should be executed at runtime or design time. NOTE: Also available from the right-click context menu. | |
| Bindings | Launches the Binding Expressions dialog for specifying Environment Variables. Only the Root Element Name, Namespace and Row Element Name are bindable properties | |
| First Row Contains Header Names | YES | Required. Default is False. This is auto populated by the Flat File Wizards First Row Contains Column Names checkbox |
| First Rows to Ignore | YES | Required. Default is zero. This is auto populated by the Flat File Wizards Ignore first text box value. |
| Last Rows to Ignore | YES | Required. Default is zero. This is auto populated by the Flat File Wizards Ignore last text box value. |
| Root Element Name | Optional. Name of the Root XML element node that will enclose all rows. | |
| Namespace | Optional. Target Namespace used for returned XML document. | |
| Row Element Name | Optional. Name of the XML element that will contain all the fields of the row. | |
| Include Schema | Required. True or False. Default value is False. If set to True, an XSD Schema will be prepended to the output XML. | |
| Output Document Type | Type of output document to produce, XML or JSON. Default is XML |
Transform XSLT
| Category: | XML |
| Class: | EsbMessageBodyXslTransformPipelineStep |
| Namespace: | Neuron.Esb.Pipelines |
| Assembly: | Neuron.Esb.Pipelines.dll |
Description:
The Transform – XSLT Process Step can be used to validate an incoming Neuron ESB Message body against any XSLT/XSL document.
https://msdn.microsoft.com/en-us/library/ms759096(v=vs.85).aspx
There are two main ways of selecting an XSLT/XSL document for the Transform XSLT Process Step to use for runtime transformation, either:
- XSLT name reference
- XSLT documents
XSLT Name Reference
XSLT name reference is perhaps the most convenient and the more performant. The XSLT Name design time property displays a drop down box populated with all the XSLT/XSL documents stored in the Neuron ESB XSL Repository (navigate to Repository->Transformations->XSL Transformations in the Neuron ESB Explorer). Users can select any XSLT/XSL document from the dropdown list. When this drop down box is used, it essentially creates a link between the contents of the repository and the Process step. This means if the repository content changes, the Process Step will load the new XSLT/XSL document changes once the hosting endpoint recycles, refreshes its configuration. Using the XSLT Name design time property, the XslCompiledTransform object that will be created for runtime transformation will be cached between calls.
XSLT Documents
The other way to select XSLT/XSL documents is through the TransformXML design time property. There is an ellipsis button on the design time property, which launches the XSLT Editor as shown below:
The XSLT Editor allows users to do one of three things:
- Add the contents of an XSLT/XSL document directly into the Editor
- Select an XSLT/XSL document from the file system (e.g. Select File->Open menu)
- Import an XSLT/XSL document from the Neuron ESB XSLT Repository (e.g. Select File->Import menu)
Each option functionally will return a static copy of the XSLT/XSL document into the Editor window. When using the Import option, the Import Document form will appear containing a searchable list box of all the XSLT/XSLs stored in the existing Neuron ESB XSL Repository (see below). Users can select an XSLT/XSL, which will copy its contents into the editor.
Using the TransformXml design-time property decouples the process step from the repository. For instance, if the XSLT/XSL contents changes in the repository after the process step has been configured, the process step will always continue to run the XSLT/XSL that was copied into the editor.
XSL Include Support
The Transform – XSLT process step supports file based locations for XSL/XSLTs that contain include references (i.e. <xsl:include href=”inlines”/>):
<xsl:stylesheet xmlns:xsl="https://www.w3.org/1999/XSL/Transform" version="1.0" xmlns="https://www.w3.org/1999/xhtml"> <xsl:include href="C:\transforms\PaymentToOrder"/> <xsl:template match="chapter"> <html> <xsl:apply-templates/> </html> </xsl:template> </xsl:stylesheet>
At runtime, if there is a Transform XSLT Step, the href attribute for includes would be resolved to file based locations. However, the Transform XSLT Process Step also supports resolving href locations referencing the Neuron ESB XSL Repository by using the esb prefix as shown in the example below:
<xsl:stylesheet xmlns:xsl="https://www.w3.org/1999/XSL/Transform" version="1.0" xmlns="https://www.w3.org/1999/xhtml"> <xsl:include href="esb:PaymentToOrder"/> <xsl:template match="chapter"> <html> <xsl:apply-templates/> </html> </xsl:template> </xsl:stylesheet>
At runtime, if the href attribute starts with esb: Neuron ESB will look for the XLST/XLS in the configurations XSL Repository. The name following the esb: must be the name of the XSLT/XSL document in the Neuron ESB Repository.
XLST/XSL Parameters
The Transform XSLT supports XSL Parameters in XSLT/XSL documents. Either this can be statically set using the XsltParameter Collection Editor or, they can be dynamically set at runtime using values from Neuron ESB Message custom properties, Environmental Variables or XPATH 1.0 expressions evaluated against the incoming message. The Parameters design-time property has an ellipsis button that launches the XsltParameter Collection Editor, which allows users to add one or more Parameters. The Add button is clicked to create a Parameter entry as shown below:
Each Parameter entry has three properties:
- Name
- NamespaceUri
- Value
The name property is required and must be set with the name of the Parameter as it appears in the XSL/XSLT document. In the following example, discount is the name of the Parameter:
<xsl:stylesheet version="1.0" xmlns:xsl="https://www.w3.org/1999/XSL/Transform"> <p> <strong style="font-weight: bold;"> <em style="font-style: italic;"> <xsl:param name="discount"></xsl:param> </em> </strong> </p> <xsl:template match="/"> <order><xsl:variable name="sub-total" select="sum(//price)"></xsl:variable> <total> <xsl:value-of select="$sub-total"></xsl:value-of> </total> 15% discount if paid by: <xsl:value-of select="$discount"></xsl:value-of></order> </xsl:template> </xsl:stylesheet>
The NamespaceUri property is optional and must contain the namespace of the parameter, if one is present. There is none in the previous example, so it can remain blank.
The value property can be set with either a static value or a dynamic value that is evaluated at runtime. For example, if a static date (i.e. 10/1/2017) was used for the value, then the user can set the value at design time as shown below:
Using the following XML source document:
<order> <book ISBN="10-861003-324"> <title>The Handmaid's Tale</title> <price>19.95</price> </book> <cd ISBN="2-3631-4"> <title>Americana</title> <price>16.95</price> </cd> </order>
The following XML output would be produced, reflecting the inclusion of the static value:
<order><total>36.9</total> 15% discount if paid by: 10/1/2017</order>
However, values can be dynamically resolved if the appropriate syntax is entered into the Value property. To use a custom Neuron ESB Message property, the following syntax must be used as the Value property:
- {property:<prefix>.<name>}
- In the following example, the static value is replaced with a custom Neuron ESB Message property using the syntax, {property:mw.prop} (minus the double quotes), as shown below:
- In a C# Code Step directly preceding the Transform XSLT step, the following C# code is used to set the property to a different date value:
context.Data.SetProperty("mw","prop","9/1/2016");
Using the custom Neuron ESB Message property the value of the Parameter is evaluated at runtime, producing the following XML output:
<order><total>36.9</total> 15% discount if paid by: 9/1/2016</order>
- To use an Environment Variable, the following syntax must be used as the Value property:
- {env:<name>}
- If there is an Environment Variable MachineName set to MJONES01, then using {env:MachineName} (minus the double quotes) will result in the parameter having the value MJONES01.
- To use an XPATH 1.0 expression that evaluates against the incoming Neuron ESB Message body, the following syntax must be used as the Value property:
- {xpath:<xpath-expression>}
- For example, if the incoming source XML looked like the following:
<person> <firstname>Michael</firstname> <lastname>Jones</lastname> </person>
- Using {xpath:/person/firstname} will result in the value Michael for the Parameter value.
Dynamic Configuration
Directly preceding the Transform – XSLT Process Step could be a Set Property Process Step or a Code Step. If a Code Step was used, the following custom properties could be used:
context.Data.SetProperty("neuron","xslt","
<xsl:stylesheet xmlns:xsl="ht/>");
context.Data.SetProperty("neuron ","xsltName","paymentToOrder");
The neuron.xslt property can be used to dynamically set the raw contents of the XSLT document to use for runtime transformation. This can be useful if the contents of the XSLT document is being loaded programmatically from an external location. Whereas the neuron.xsltName property can be used to dynamically set the name of the XSLT document stored in the Neuron ESB XSLT Repository that the Transform – XSLT Process Step should use for runtime transformation. This essentially provides the Process Step with a pointer to an XSLT document. If the latter property is used, the name will be resolved and its XSLT content will be retrieved from the configuration, an XslCompiledTransform object will be created and cached.
The neuron property can be accessed directly from the Neuron ESB Message object using the GetProperty() or GetProperties() methods. All Neuron ESB Message properties can also be set using the Set Property Process Step.
| Process Step | Custom Property (i.e. prefix.name) | Design-time Property |
| Transform – XSLT | neuron.xslt | N/A |
| neuron.xsltName | XSLT Names |
Design Time Properties
| Name | Dynamic | Description |
| Name | User provided name for the Process Step. Will replace default name of Step when placed on the Design Canvas. | |
| Disable | Boolean flag to determine whether the step should be executed at runtime or design time. NOTE: Also available from the right-click context menu. | |
| Bindings | Launches the Binding Expressions dialog for specifying Environment Variables. | |
| EnableDocumentFunction | Required. Default is false. Indicating whether to enable support for the XSLT document() function. | |
| EnableScript | Required. Default is false. Indicating whether to enable support for embedded script blocks. | |
| TransformXml | YES | Optional. Launches the XSLT Transform Editor that allows users to either 1.) Manually enter or copy XSLT directly into the editor, 2.) Select an XSLT document from an external disk location, which will copy the body into the editor, 3.) Import an XSLT document body from the Neuron ESB Repository into the editor. |
| Parameters | Required ONLY if XSLT Parameters are required by the XSLT selected by the user. Launches the XsltParameter Collection Editor. Users can enter one or more parameters, each one is defined by a name, namespace uri and value property. | |
| Referenced Schema Location | This allows to configure the process step to retrieve the XSLTs from an external file share. If this XSLT contains any import directives , this is the location they will be searched for when only a filename or a relative path is provided as the Schema location in the XSLT. f this is left blank, the xslt location will be resolved based on the Neuron ESB Instance that is hosting this solution. This property can be overridden globally by setting the appSetting key, “XsltFilesLocation”, to the location. | |
| Referenced Schema Location | This allows to configure the process step to retrieve the XSLTs from an external file share. If this XSLT contains any import directives , this is the location they will be searched for when only a filename or a relative path is provided as the Schema location in the XSLT. f this is left blank, the xslt location will be resolved based on the Neuron ESB Instance that is hosting this solution. This property can be overridden globally by setting the appSetting key, “XsltFilesLocation”, to the location. | |
| XSLT Name | YES | Optional. Drop down list of all XSLT documents stored in the Neuron ESB Repository. Users can select an XSLT name from the list. At runtime, its XSLT body is retrieved by name from the Repository. An XslCompiledTransform object is created and cached for runtime transformation. |
Validate Schema
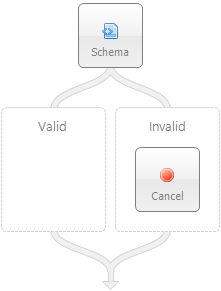
| Category: | XML |
| Class: | EsbMessageSchemaValidationPipelineStep |
| Namespace: | Neuron.Esb.Pipelines |
| Assembly: | Neuron.Esb.Pipelines.dll |
Description:
The Validate Schema Process Step can be used to validate an incoming Neuron ESB Message body against a set of XSD schemas.
The Validate-Schema Process step is a composite step that has two branches (Execution Blocks) where other process steps can be placed. One branch (named Valid) is followed if the validation is successful and the other branch (named Invalid) is followed if the validation fails. The Invalid branch defaults to having a single Cancel Process step but it can be removed and other steps can be placed in that branch for execution.
There are two main ways of selecting one or more XSD Schemas for the Validate Schema Process Step to use for runtime validation, either:
- Schema name reference
- Schema documents
Schema Name Reference
Schema name reference is perhaps the most convenient and the more performant. The Schema Names design time property displays a drop down box populated with all the XSD Schemas stored in the Neuron ESB Schema Repository (navigate to Repository->Data Contracts->XML Schemas in the Neuron ESB Explorer). Users can multi select from the dropdown list by holding control button while clicking with the mouse. When this drop down box is used, it essentially creates a link between the contents of the repository and the Validate Schema Process step. This means if the repository content changes, Validate Schema Process Step will load the new XSD Schema changes once the hosting endpoint recycles, refreshes its configuration. Using the Schema Names design time property, the XmlReaderSettings object that will be created for runtime validation will be cached between calls.
Schema Documents
The other way to select schemas is through the Schemas design time property. There is an ellipsis button on the design time property, which launches the NeuronSchemasCollectionItem Collection Editor. The Collection Editor (displayed below) is used to select one or more XSD Schemas that the Validate Schema Process Step will use at runtime to validate incoming messages. Unlike the Schema Names property, this does not create a pointer/reference to the XSD Schemas stored in the Neuron ESB Schema Repository:
:
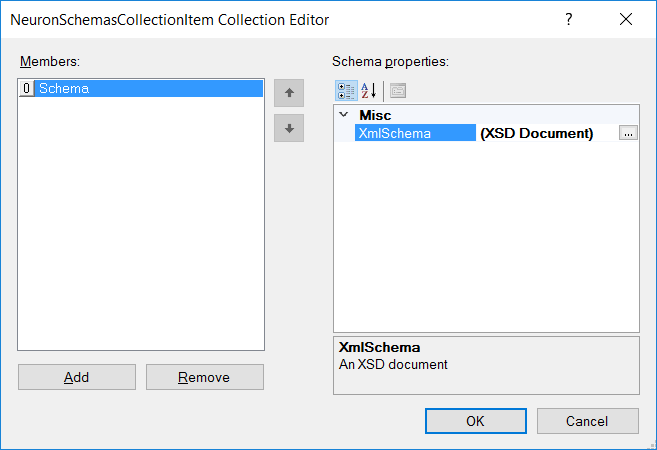
The Collection Editor allows users to add one or more XSD Schemas. The Add button is clicked to create a Schema entry. Next to the Schema entry is an ellipsis button, which when clicked will launch the XSD Editor as shown below:
The XSD Editor allows users to do one of three things:
- Add the contents of an XSD Schema directly into the Editor
- Select an XSD Schema document from the file system (e.g. Select File->Open menu)
- Import an XSD from the Neuron ESB Schema Repository (e.g. Select File->Import menu)
Each option functionally will return a static copy of the XSD Schema document into the Editor window. When using the Import option, the Import Document form will appear containing a searchable list box of all the XSDs stored in the existing Neuron ESB Schema Repository (see below). Users can select a schema, which will copy its contents into the editor.
Using the Schema design-time property decouples the process step from the repository. For instance, if the schema contents changes in the repository after the process step has been configured, the process step will always continue to run the schema that was copied into the editor.
When multiple XSD Schemas are selected, the runtime validation process will search through the list of Schemas to find one that matches the incoming message to validate against. If one cannot be found, control will flow to the Invalid Branch of the Process Step.
Schema Import Support
The Validate – Schema process step supports file based locations for the schemaLocation attribute for schemas that contain import or include references. For example, when a WSDL is downloaded, the schemas included in that WSDL uses will often import from a different schema, using a schemaLocation attribute to direct the schema parser on where to find it, as shown below:
<xsd:schema elementFormDefault="qualified" targetNamespace="urn:partner.soap.sforce.com" xmlns="https://www.w3.org/2001/XMLSchema" xmlns:ens="urn:sobject.partner.soap.sforce.com" xmlns:tns="urn:partner.soap.sforce.com" xmlns:xsd="https://www.w3.org/2001/XMLSchema"> <xsd:import namespace="urn:sobject.partner.soap.sforce.com" schemaLocation="C:\SchemaS\Account_sObject"></xsd:import>
At runtime, if there were a Validate-Schema process step, the import (or include) would be resolved to the local file system. However, the Validate Schema Process Step also supports resolving schema locations referencing the Neuron ESB Schema Repository by using the esb prefix as shown in the example below:
<xsd:schema elementFormDefault="qualified" targetNamespace="urn:partner.soap.sforce.com" xmlns="https://www.w3.org/2001/XMLSchema" xmlns:ens="urn:sobject.partner.soap.sforce.com" xmlns:tns="urn:partner.soap.sforce.com" xmlns:xsd="https://www.w3.org/2001/XMLSchema"> <xsd:import namespace="urn:sobject.partner.soap.sforce.com" schemaLocation="esb:Account_sObject"></xsd:import>
At runtime, if the schemaLocation attribute starts with esb: Neuron ESB will look for the schema in the configurations Schema Repository. The name following the esb: must be the name of the XSD Schema in the Neuron ESB Repository.
Dynamic Configuration
Directly preceding the Validate – Schema Process Step could be a Set Property Process Step or a Code Step. If a Code Step was used, the following custom properties could be used:
context.Data.SetProperty("neuron","schema",
"<xs:schema id=Payments/>");
context.Data.SetProperty("neuron ","schemaNames",
"SourceSchema;PaymentSchema");
The neuron.schema property can be used to dynamically set the raw contents of the XSD Schema document to use for runtime validation. This can be useful if the contents of the XSD Schema are being loaded programmatically from an external location. Whereas the neuron.schemaNames property can be used to dynamically set the name (or set of names) of the XSD Schema(s) stored in the Neuron ESB Schema Repository that the Validate Schema Process Step should use for runtime validation. This essentially provides the Validate Schema Process Step with a pointer to a set of schemas. If the latter property is used, their names will be resolved and their XSD content will be retrieved from the configuration, an XmlReaderSettings object will be created and cached.
The neuron property can be accessed directly from the Neuron ESB Message object using the GetProperty() or GetProperties() methods. All Neuron ESB Message properties can also be set using the Set Property Process Step.
| Process Step | Custom Property (i.e. prefix.name) | Design-time Property |
| Validate – Schema | neuron.schema | N/A |
| neuron.schemaNames | Schema Names |
Design Time Properties
| Name | Dynamic | Description |
| Name | User provided name for the Process Step. Will replace default name of Step when placed on the Design Canvas. | |
| Disable | Boolean flag to determine whether the step should be executed at runtime or design time. NOTE: Also available from the right-click context menu. | |
| Bindings | Launches the Binding Expressions dialog for specifying Environment Variables. | |
| Schemas | YES* | Optional. If the Schema Names property is not populated, then this is required. Launches the NeuronSchemasCollectionItem Collection Editor. This is used to select one or more XSD Schemas that the Validate Schema Process Step will use at runtime to validate incoming messages. Unlike the Schema Names property, this does not create a pointer/reference to the XSD Schemas stored in the Neuron ESB Schema Repository. After XSD schemas are added using this property, they will not be affected by any change in existing XSD Schemas within the Neuron ESB Schema Repository. The XmlReaderSettings object is not cached for runtime execution. |
| AllowXmlAttributes | Required. Default is false. Indicating whether to allow xml:* attributes even if they are not defined in the schema. The attributes will be validated based on their data type. This property is based on the Xml Validation Flag: https://msdn.microsoft.com/en-us/library/system.xml.schema.xmlschemavalidationflags(v=vs.110).aspx. | |
| ProcessSchemaLocation | Required. Default is false. Indicating whether to Process schema location hints (xsi:schemaLocation, xsi:noNamespaceSchemaLocation) encountered during validation. This property is based on the Xml Validation Flag: https://msdn.microsoft.com/en-us/library/system.xml.schema.xmlschemavalidationflags(v=vs.110).aspx. It is recommended that this be set to True. | |
| ProccessIdentityConstraints | Required. Default is false. Indicating whether to process identity constraints (xs:ID, xs:IDREF, xs:key, xs:keyref, xs:unique) encountered during validation. This property is based on the Xml Validation Flag: https://msdn.microsoft.com/en-us/library/system.xml.schema.xmlschemavalidationflags(v=vs.110).aspx. It is recommended that this be set to True. | |
| ProcessInlineSchema | Required. Default is false. Indicating whether to process inline schemas encountered during validation. This property is based on the Xml Validation Flag: https://msdn.microsoft.com/en-us/library/system.xml.schema.xmlschemavalidationflags(v=vs.110).aspx. It is recommended that this be set to True. | |
| Schema Names | YES | Optional. If the Schemas property is not populated, then this is required. Drop down list of all XSD schemas stored in the Neuron ESB Repository. Users can select one or more from the list. They are stored as a semicolon delimited string. At runtime, their XSD values are retrieved by name from the Repository. An XmlReaderSettings object is created and cached for runtime validation. |