Since the release of CU4 in May 2016, the Neuron ESB Product Team has been aggressively working on a number of enhancements to increase processing performance while reducing memory utilization when running sustained workloads using Neuron ESB. These enhancements included numerous memory optimizations, deadlock resolutions, object pooling implementations and in some cases, internal service refactoring.
In the course of these efforts, we conducted a number of sustained workload tests which we used to identify areas where memory leaks could occur or performance could degrade. Our goal was to normalize memory consumption, increase throughput as well as achieve performance homeostasis when running high concurrency workloads. Besides stabilizing performance and memory utilization, this work resulting in increasing endpoint throughput anywhere between a factor of 10 and 40. In addition to this work, significant modifications to the Neuron ESB Workflow engine were introduced to ensure the consistency and reliability of correlated workflow scenarios. This paper discusses several areas of focus:
- Neuron ESB Message Tracking (Auditing)
- Service Endpoints (Client Connectors i.e. Web hooks)
- Business Process Step Object Pooling
- Adapter Endpoint Object Pooling
- Adapter Endpoint Processing Threads
- Neuron ESB Logging and Literal Strings
- Performance Tuning
Although this document summarizes much of the work, full details can be found in the Neuron ESB Change Log, starting at build 3.5.4.920.
Neuron ESB Message Tracking (Auditing)
We increased overall message tracking capacity and scale for the Neuron ESB Message Auditing Service while reducing overall resource utilization. We did this through the implementation of a 2-prong approach:
- Changing the Audit Service from Singleton to Per Call
- Implementing Object Pooling for the Audit Process Step
Audit Service to Per Call
We changed the internal Audit Service implementation from a singleton instance to a per call service instance. This allows for greater scale out and eliminates blocking that could occur under high load. The immediate impact of this change is that the performance of the Auditing Service is now controlled by the Max Concurrent Instances setting located on the Server tab of the solution’s Zone settings page as shown below:
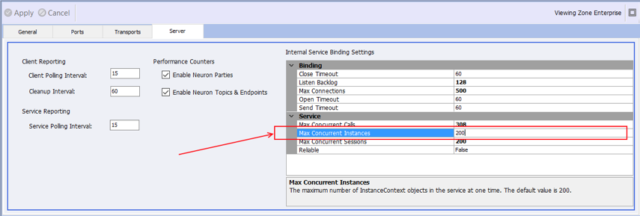
Assuming users are running machines with eight or more cores, the recommended value for this setting is 100 to 200. The higher this number, the more instances will be created at runtime when under load, and these instances will increase memory utilization. Users should always conduct performance testing against their specific workloads in an environment similar to their target production environment to determine the correct value for this setting.
Audit Process Step Object Pooling
Rather than use Topic-based Auditing, most organizations tend to implement Auditing by employing the Audit Process Step within Business Processes. This has several advantages:
- Allows customers to track the state of the message exactly where and when they want
- Allows customers to track either the entire message or just specific fragments of the message via XPATH statements
Quite often, the Audit Process Step is used in Business Processes attached to the On Publish event of Client Connectors (Service Endpoint that acts as a Web Hook). This is significant since Client Connectors are called by outside applications. Hence, under concurrent workloads, multiple instances of the Business Process will always be created and executed. In previous releases, the Audit Process Step used a single Audit Service “proxy” to the Neuron ESB Audit Service. This implementation could cause blocking, threading issues and even deadlocking under high concurrent loads. In this Performance Update, we changed the implementation of the Audit Process Step to optimize memory utilization and support object pooling. The Audit Process Step now creates and uses a thread safe pool of Audit Service “proxies”. This allows the Audit Process Step to more cleanly scale and perform in high concurrent workloads. The Audit Process Step has a new Pool Management category of properties, Maximum Instances and Pool Timeout. The two properties are displayed below:
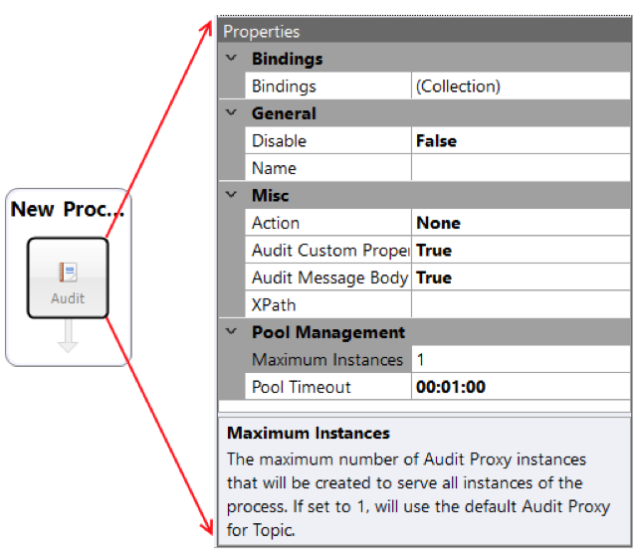
The Maximum Instances property is used to define the maximum upper limit of the number of Audit Proxy instances that could be created under high concurrent load. A new instance is created ONLY if an available proxy instance is not available in the pool at the time a call is made. Once an instance is created, it is added to the existing object pool. If there are no free instances available in the pool at the time of a call, the Audit Process step will wait the amount of time specified in the Pool Timeout property for an instance to be returned to the pool. If one is not free in the amount of time specified, a Timeout exception will be thrown back to the main Business Process.
For example, if the Maximum Instances property was set to 100, it does not necessarily mean that 100 instances of the Audit Service proxy will be created and placed in the pool. Generally, setting this property to any value above 50 can actually result in degraded performance under specific circumstances. Like all other things, users must test under expected workloads to determine the best settings for their solution. Setting this property to one reverts the Audit Process step to its previous behavior.
The new object pool for the Audit proxy comes in handy when organizations are doing concurrent requests against a Client Connector i.e. many threads coming in, when each thread executes an instance of the Business process. In those scenarios, it is important to understand how many concurrent requests will be received against the Client Connector. That number will typically be the value used to set the Maximum Instances property. The object pool will function to squeeze more performance out of the Audit Service when dealing with higher levels of concurrency.
If the Audit Proxy Process Step will not be executing in a concurrent environment (i.e. File Adapter, etc.), then the Pool Size should be set to one.
Service Endpoints (Client Connectors i.e. Web hooks)
Similar to the Neuron ESB Message Audit Service, the Neuron ESB Client Connector (i.e. Web Hook) implementation has been changed from a singleton instance to a per call service instance. This allows for greater scale out and eliminates blocking that could occur under high load. The immediate impact of this change is that the performance of a specific Client Connector is now controlled by the Max Concurrent Instances setting located on the Client Connector tab of the Service Endpoint as shown below:
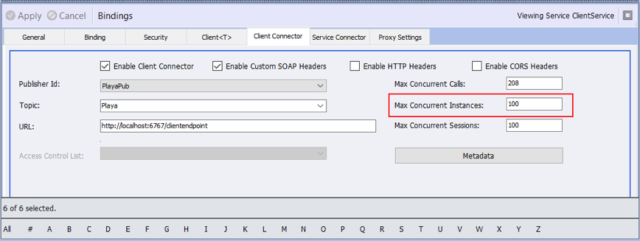
With this and several other internal modifications, performance and resource utilization were substantially enhanced. For example, in previous releases of Neuron ESB, the performance profile of a Client Connector processing concurrent requests would show an initial spike in the number of concurrent requests processed. However, over short period time, providing the workload of concurrent requests remained consistent, the number of concurrent requests processed would steadily drop while the private bytes consumed by the Neuron ESB host service would steadily increase.
Test Case
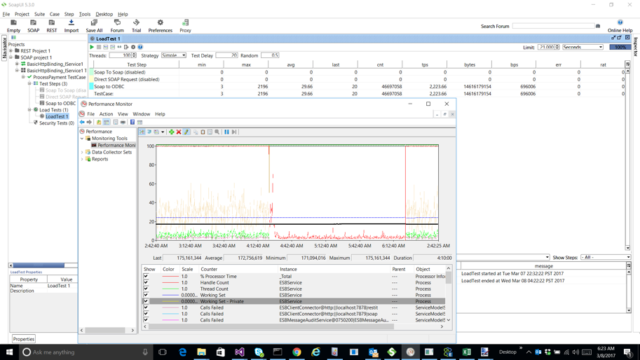
In this update, we increased concurrent processing while stabilizing and even reducing memory utilization. To test this, we built a simple solution that consisted of a SOAP based Client Connector running a Business Process that calls an Adapter Endpoint Process Step. The Adapter Endpoint Process Step queries a database using the Neuron ESB ODBC Adapter, returning the result of the query to the SOAP endpoint caller. All calls were made, and performance monitored using SOAP UI and the Microsoft Performance Monitor.
Specifically, SOAP UI was configured to run for approximately 6 hours, use 100 threads to represent concurrent requests, each with a 20-millisecond delay. The following results can be seen in the picture below:
- Private Bytes and Working Set memory of the ESB Service host runtime remained flat at approximately 200 MB
- The SOAP Client Connector processed over 2,200 TPS (i.e. concurrent requests per second)
- Each request had a 30 millisecond average response time
Business Process Step Object Pooling
Neuron ESB Business Processes are often used in concurrent environments, implementing business mediation logic against requests received via Neuron ESB Client Connectors or other multi-threaded endpoints or scenarios. There are several Process Steps similar to the Audit Process Step, which depend on sharing of resources under concurrent conditions to perform as expected. Besides performant, they must also be thread safe. They are:
- Service Endpoint – Allows users to call REST/SOAP Services (Service Endpoints) directly without having to route the request through the Neuron ESB Messaging Pub/Sub system
- Adapter Endpoint – Allows users to call Adapter Endpoints directly without having to route the request through the Neuron ESB Messaging Pub/Sub system
- Execute Process – Allows users to execute Business Processes within a Business Processes (functionally sub processes) for reusability.
In previous releases, all three Process Steps relied on a single resource model with locking. As with the Audit Process Step, their original implementations were prone to deadlocking, threading and memory utilization issues. Under sustained concurrent workloads, they all suffered performance degradation as well as increased memory resource utilization.
In this Performance Update, we changed the implementation of these Process Steps to optimize memory utilization and support object pooling, just as we did with the Audit Process Step, increasing both scale and performance in high concurrent workloads. These Process Steps inherit the new Pool Management category of properties of the Audit Process Step, Maximum Instances and Pool Timeout. Using the Adapter Endpoint Process Step as a model, the two properties are displayed below:
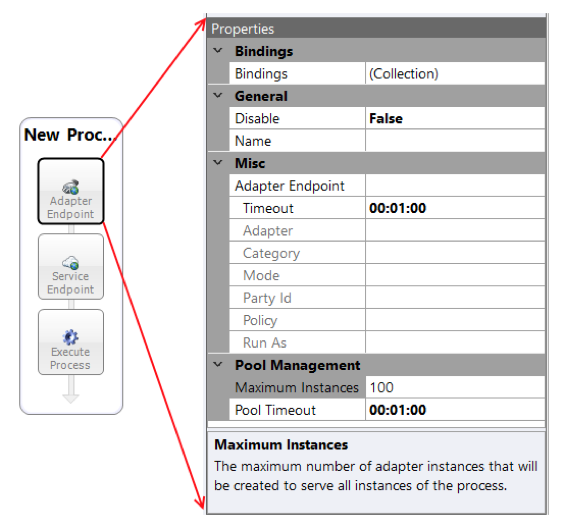
The Maximum Instances property is used to define the maximum upper limit of the number of object instances that could be created under high concurrent load. A new instance is created ONLY if an available object instance is not available in the pool at the time a call is made. Once an instance is created, it is added to the existing object pool. If there are no free instances available in the pool at the time of a call, the Process step will wait the amount of time specified in the Pool Timeout property for an instance to be returned to the pool. If one is not free in the amount of time specified, a Timeout exception will be thrown back to the main Business Process.
The same guidance provided for the Audit Process Step earlier in this document should be followed for these Process Steps as well. If the Process Steps will not be executing in a concurrent environment (i.e. File Adapter, etc.), then the Pool Size should be set to one.
Adapter Endpoint Object Pooling
Just as Adapter Endpoints can be called directly from any Business Process or Workflow, they can also be called indirectly through the Neuron ESB Messaging Pub/Sub system. When a message is published to a Topic, the underlying Publishing Service will route the message to all eligible subscribers. By default, an Adapter Endpoint is configured as a Subscriber to Topics by virtue of the Party it is associated with. Hence, publishing messages to Topics is an effective means of decoupling the publishing Party from its subscribing Parties. A change to one does not necessarily have to affect the other. However, there are performance implications when calling Adapter Endpoints via Neuron ESB Messaging.
- Latency and overhead of the Topic transport
- Adapter Endpoint Controller serialization
The first point, Latency and overhead of the Topic transport, can vary based on the underlying transport of the Topic, and its respective configuration. For instance, many of the Topic transports that Neuron ESB provides (i.e. TCP/Named Pipes/Peer/Rabbit MQ and MSMQ) can easily route and process on the order of thousands of messages per second with latency rates anywhere between 10 and a couple of hundred milliseconds. However, their performance, throughput and latency will vary based on their individual configuration. For instance, Rabbit MQ based Topics in Neuron ESB can sustain up to 10,000+ messages/per second end to end delivery if configured for NO Persistence and NO Transactions. However, if both are configured, that rate could go down to just a couple of thousand, depending on the performance of the underlying disk sub system and the type of Transaction configured. Yet, even those numbers would typically overwhelm many back end Line of Business systems that may be recipients to those messages. This moves us to the second point, the mechanism in which Adapter Endpoints receive the individual messages from the Topic transports, the Adapter Endpoint Controller.
By default, all Adapter Endpoints are subscribers to Topics by virtue of the Party they are configured with. Parties subscribing to Topics are all multi-threaded consumers, (with the exception of Rabbit MQ), that allows them to consume messages as fast as the Topic’s transport can deliver them. However, once the Party receives a message on a delivery thread, it passes it off to the Neuron ESB Adapter Endpoint Controller. The job of the Adapter Endpoint Controller is to load an instance of the Adapter Endpoint and pass the message to it for processing. However, the Adapter Endpoint Controller serializes all messages to one shared instance of an Adapter Endpoint, effectively negating throughput benefits of the underlying transport and the multi-threaded consumer model of the Party. The reason this behavior exists is to support Ordered Delivery. Unfortunately, there has never been a way to override this behavior, until now.
In this Performance Update, we have added a new “Pool Size” property located on the general tab of the Adapter Endpoints screen within the Neuron ESB Explorer (see below). This effectively allows users to configure an object pool of Adapter Endpoints, similar to what we provided for the Adapter Endpoint Process Step.
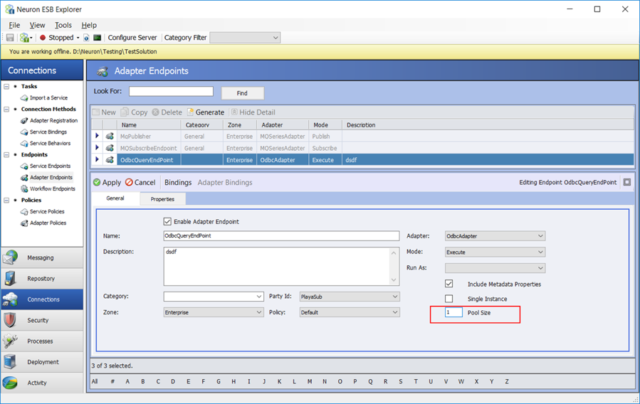
If this property is set to a default of one, the behavior will be consistent with previous releases of Neuron ESB, essentially serializing all calls to the Adapter Endpoint. The pool size number indicates the maximum number of adapter instances that Neuron ESB “could” create at runtime to process messages. For example, if the Pool Size was set to 250, but Neuron ESB was only sending in a few hundred request/sec, more than likely only a handful of adapter instances would need to be created to handle the throughput.
In previous releases, normal throughput for an Adapter endpoint was generally limited to a couple of hundred messages per second processed (depending on the adapter). By increasing the Pool Size property, that number can be increased to several thousand messages per second processed. If a Neuron ESB Adapter Endpoint is receiving more messages than the configured Pool Size can service, Neuron ESB will write out warnings in the Neuron Log file of the endpoint alerting users that Neuron ESB is occasionally waiting for an instance to become free to use i.e.
2017-03-26 20:29:24.822-07:00 [4] ALWAYS – ESB Trace Log – Machine: – Trace level: Error+Warning
2017-03-26 20:29:37.204-07:00 [168] WARN – Waiting to retrieve ‘OdbcQueryEndPoint’ adapter endpoint from collection because we’ve hit our pool size limit.
This is a good indicator that the Pool Size should be raised, or the Adapter Endpoint itself is too long running in its processing of a message.
An important note though. This setting will have marginal if any performance affect when the Adapter Endpoint receives messages over either a Rabbit MQ topic (which is a single threaded consumer model) or an MSMQ Topic where the MSMQ Transport configured for Ordered Delivery.
Overall, our internal testing of the refactoring of the Adapter Endpoint Controller produced some very good results. Our tests used the following scenarios:
- A request/reply use case using SOAP UI to send in a request to a Neuron ESB Client Connector configured for SOAP. The received request would be published to a TCP based Topic where a subscribing ODBC Adapter Endpoint (configured in Query mode) would process the request, query the database for the information and return that information as the reply message back to the calling client (i.e. SOAP UI). SOAP UI was configured for 100 threads with a 20-millisecond delay between calls to replicate 100 concurrent user requests.
- A multicast (one-way) use case using the Neuron ESB Test Client to submit 5,000,000 messages with a delay of 10 milliseconds between each 300 messages to a TCP based topic where a subscribing ODBC Adapter Endpoint (configured in Execute mode) would insert the message into a database.
All testing was conducted on a developer laptop running Windows 10, configured with eight cores, 32 gig of RAM. The database used for the tests was created in Microsoft SQL Server 2014 using the database script that Neuron ESB ships with it samples. No special configuration or tuning was performed.
We conducted three test runs of the first scenario, request/reply. The first was against the original CU4 release (pre 920) that did not have the refactored Adapter Endpoint Controller. The second was against the Performance Update, using a Pool Size of one. The third, also against the Performance Update, using a Pool Size of 100.
Request/Reply Scenario
Original CU4 release (pre 920)
We first conducted the request/reply test using the pre 920 build that did not include the changes in the Performance Update.
Results
As can be seen from the image below, after running this for more than an hour, simulating 100 concurrent requests, we were achieving approximately 51 requests/sec (TPS) with an average response time of almost 2 seconds. Through the duration of this testing we observed that initially, TPS peaked at the start of the test and then steadily decreased over the duration of the hour.
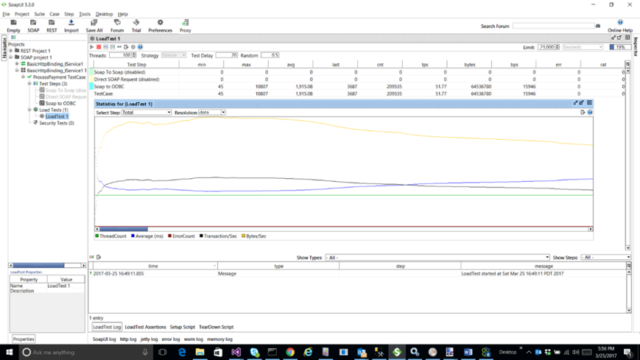
Performance Update – Pool Size of 1
We used this test to compare the new behavior with the pre 920 release behavior. We specifically set the Pool Size property to one to replicate the serialization behavior (Ordered Delivery) of the previous releases. As can be seen from the image below, we achieved substantially better and more stable results.
Results
We maintained a steady 198 request/sec (TPS) with an average response time of 489 milliseconds. Compare that with the previous release, which only resulted in 51 requests/sec (TPS) with an average response time of almost 2 seconds. Additionally, we saw no degradation in performance during the test run, as can be seen by the horizontal lines across the graph below.
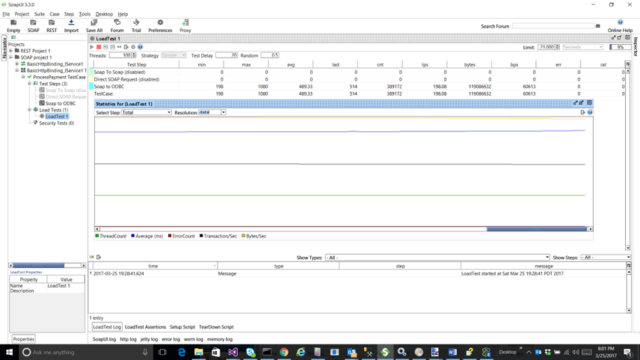
Performance Update – Pool Size of 100
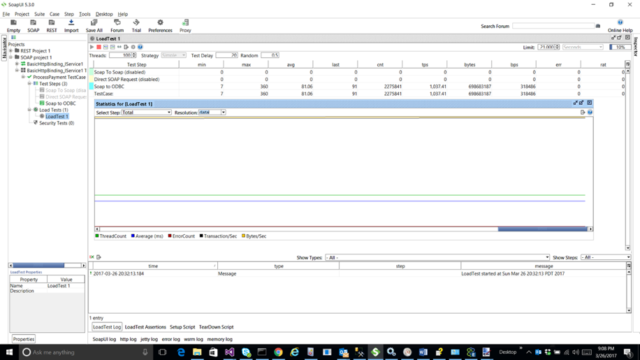
This test is similar to the previous one except the Pool Size parameter is set to 100. The Pool Size number indicates the maximum number of adapter instances that the Adapter Endpoint Controller “could” create to process messages. It does not mean that number of instances will be created every time. For example, the Pool Size is set to 250 but only 10 or 100 request/sec were being sent then probably only a handful of instances would ever get created. However, for this test, the performance profile changed quite dramatically once the Pool Size was set to 100, as can be seen in the SOAP UI screen shot below.
Results
We were able to maintain approx. 1,000 request/sec (TPS) with an average response time of 81 milliseconds. Compare that against a Pool Size of one where we saw 198 TPS with an average response time of 489 milliseconds. Additionally, memory and resource utilization remained flat for the entire test as can be seen by the horizontal lines in both the SOAP UI and Performance Monitor screenshots below.
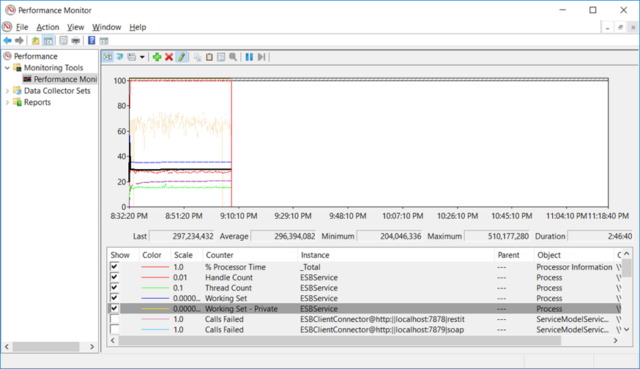
Final Results
| Test | TPS (Request/Sec) | Avg. Response (Milliseconds) |
| Original CU4 Release (pre 920) | 51 | 1,915 |
| Pool Size 1 | 198 | 489 |
| Pool Size 100 | 1037 | 81 |
Multicast (one-way) Scenario
Original CU4 release (pre 920)
We first conducted the multicast test using the pre 920 build that did not include the changes in the Performance Update. In this scenario, we used a Neuron ESB Test Client configured in bulk submit mode to send five million messages over a TCP topic which the ODBC adapter endpoint was subscribing to. The ODBC Adapter Endpoint would insert each message into a database table.
Results
As can be seen in the image of the Neuron ESB Test Client below, we were only able to achieve approximately 103 execute insert statements per second processed by the adapter endpoint. The test was terminated after processing more than one million messages.
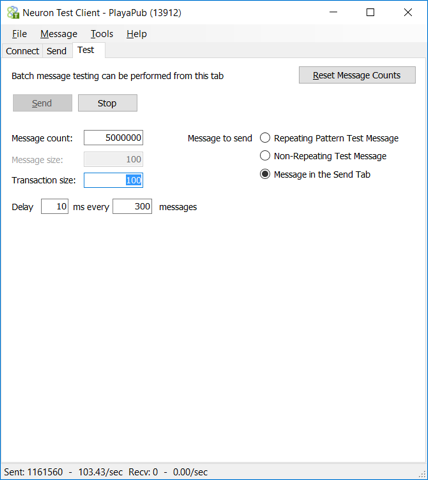
Additionally, we monitored the performance profile and number of calls using Performance Monitor. As can be seen in the image below, this confirmed the 103 TPS number we observed in the Neuron ESB Test Client. However, we also observed that the current performance profile was substantially erratic. The Adapter Endpoint could not keep up with what the Topic transport was capable of delivering due to the serializing nature of the Adapter Endpoint Controller. This caused backward pressure on the Topic transport (Calls Outstanding), which throttled the publishing performance of the Neuron ESB Test Client.
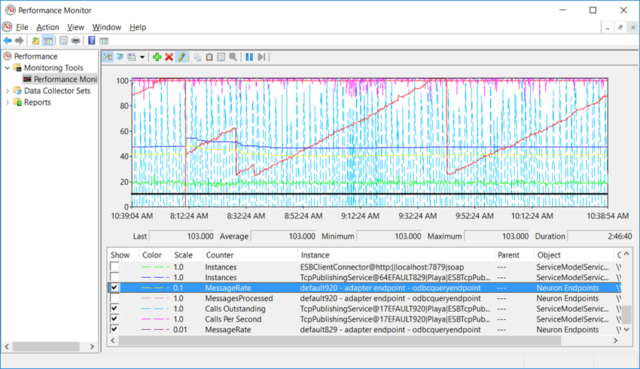
Performance Update – Pool Size of 250
This test is similar to the previous one except the Pool Size parameter is set to 250. For this test, just as we saw in the request-reply tests, the performance profile changed dramatically once the Pool Size was set to 250.
Results
As can be seen in the image of the Neuron ESB Test Client below, we were only able to achieve approximately 4,008 execute insert statements per second processed by the adapter endpoint. The test successfully processed all 5 million inserts without error.
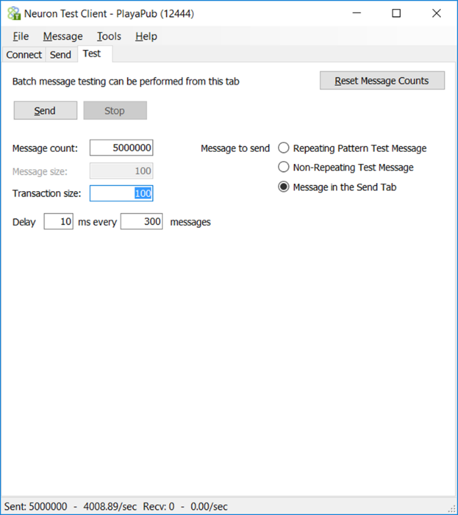
Additionally, we monitored the performance profile and number of calls using Performance Monitor. As can be seen in the image below, this confirmed the 4,008+ TPS number we observed in the Neuron ESB Test Client. This time however, we observed that the current performance profile was dramatically different from what we saw with the previous test. This one was stable and consistent demonstrating that the Adapter Endpoint had no issues keeping up with the requests it was receiving from the underlying Topic transport.
Final Results
| Test | TPS (Inserts/Sec) |
| Original CU4 Release (pre 920) | 103 |
| Pool Size 250 | 4008 |
Adapter Endpoint Processing Threads
We made several enhancements to the Neuron ESB Rabbit MQ Topic transport to address deadlocks scenarios as well as high CPU usage when processing dead letter messages. We also upgraded the version of the Rabbit MQ Client API to address known errors that could occur under load. However, more importantly, we added a feature that allows users to overcome the single threaded delivery nature of the Rabbit MQ transport.
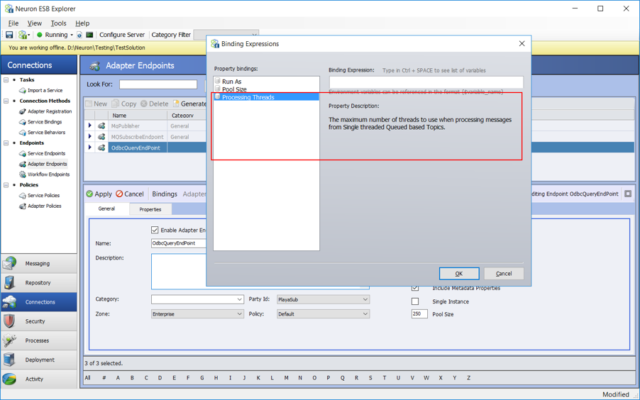
As noted in the previous section, the Rabbit MQ Topic Transport differed from the other Neuron ESB Topic transports in so far that is used a single threaded consumer model to deliver messages to the Neuron ESB Party. This negated the effectiveness of the new Adapter Endpoint Object Pooling feature when messages are received from a Rabbit MQ Topic. To overcome this, we added a new feature to Adapter Endpoints, specifically for the Rabbit MQ transport, called “Processing Threads”. Using the Processing Threads property users can define how many threads (from the .NET Thread Pool) should handle consuming the messages from the Rabbit MQ transport. Functionally, making the Rabbit MQ Topic transport a multi-threaded consumer model.
A “Processing Threads” property has been added to Adapter Endpoints and is accessible either by using an Environmental Variable to set the property (as shown below):
Alternatively, by manually editing the underlying XML file that represents the Adapter Endpoint as shown in the fragment below:
<?xml version="1.0"?>
<ESBEndpoint xmlns:xsd="https://www.w3.org/2001/XMLSchema" xmlns:xsi="https://www.w3.org/2001/XMLSchema-instance">
<Id>07dfa54f-a1d1-4405-8063-3a5c17f218cb</Id>…
<PoolSize>250</PoolSize>
<ProessingThreads>30</ProessingThreads>
</ESBEndpoint>The “Processing Threads” value is one by default. This provides the behavior found in previous releases of Neuron ESB. However, where throughput could not be increased by using the Pool Size property for Ordered Delivery Queued Topics (i.e. Rabbit MQ or MSMQ set for Ordered Delivery), throughput can be substantially increased for these Topic transports (similar to using the Pool Size property for non-Queued Topics) by raising the value of this property. This property should NOT be used if receiving messages from non-Queued Topics like TCP, Peer or Named Pipes, or if Ordered Delivery of the messages to the Adapter Endpoint is a requirement. A good example where users may want to set this property to a high value is when receiving messages from a Rabbit MQ Topic as Rabbit MQ only supports ordered delivery of messages.
Neuron ESB Logging and Literal Strings
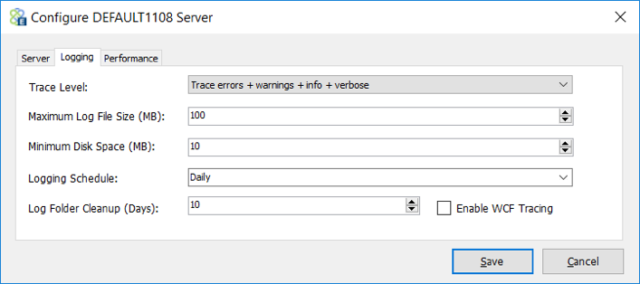
As part of our efforts to normalize memory utilization and clean up we spent considerable time refactoring how and when we create strings within the runtime. String creation is unavoidable as users can define different logging levels for the Neuron ESB Runtime by accessing the Configure Server user interface and selecting the preferred logging level as shown in the picture below:
However, in previous releases, we were creating a considerable number of literal strings regardless of the tracing level selected by the user. We saw that in very large solutions that ran considerable workloads, this could result in 10s of thousands if not hundreds of thousands of string objects in memory. In addition, the vast majority would be pinned in the common language runtime’s intern pool. The common language runtime (CLR) automatically maintains a table, called the intern pool, which contains a single instance of each unique literal string constant declared in a program. The intern pool actually resides on the Large Object Heap. .NET automatically performs string interning for all explicitly declared string literals at compile time.
Although the intern pool conserves string storage, interning strings has two unfortunate side effects. First, the memory allocated for interned String objects is not likely to be released until the Neuron ESB service terminates. Second, the memory used by the String objects must still be allocated, even though the memory will eventually be garbage collected.
Our goal was to first optimize “how” we create strings, followed by modifying “when” we create strings. This resulted in substantial changes in how we performed logging internally. Now, when users choose the Errors or Warnings logging level, substantially fewer resources will be allocated to string objects and memory allocation then when the Verbose logging level is selected.
The consequence of this work introduced new logging flags and options that users can employ in their own custom solutions to ensure that strings are only created at runtime rather than compile time. Having effective logging utilities assists developers in incorporating diagnostics into their solution that can assist in troubleshooting issues that occur at runtime. To this end, we added new logging options in both the Business Process and Workflow Designers when developers are using the C# workflow activities or process steps.
When using Workflow, developers will find a new “Log” object that they can use to log diagnostics information directly to the Neuron ESB Log files. The “Log” object provides developers the ability to check the logging level configured for the runtime before writing to log, preventing unnecessary literal string creation and memory utilization. For instance, the Log object has the following properties:
- IsDebugEnabled
- IsWarnEnabled
- IsInfoEnabled
- IsErrorEnabled
For example, in the Workflow Designer within a C# activity custom logging could look like this now:
if(Log.IsDebugEnabled)
Log.Debug("only run this statement if 'Verbose' logging is enabled");
if(Log.IsInfoEnabled)
Log.Info("only run this statement if 'Info' logging is enabled");
if(Log.IsWarningEnabled)
Log.Warning("only run this statement if 'Warning' logging is enabled");
if(Log.IsErrorEnabled)
Log.Error("only run this statement if 'Errors' logging is enabled");A very similar API was added to the Process Designer. For example, in the Business Process Designer within a C# activity custom logging could look like this now:
if(context.Instance.IsDebugEnabled)
context.Instance.TraceInformation("only run this statement if 'Verbose' logging is enabled");
if(context.Instance.IsInfoEnabled)
context.Instance.TraceInformation("only run this statement if 'Info' logging is enabled");
if(context.Instance.IsWarningEnabled)
context.Instance.TraceInformation("only run this statement if 'Warning' logging is enabled");
if(context.Instance.IsErrorEnabled)
context.Instance.TraceInformation("only run this statement if 'Errors' logging is enabled");These same properties were also added to the Neuron ESB Adapter Framework classes. For example, adapter writers can check the logging level before creating their strings:
if (base.IsDebugEnabled)
RaiseAdapterInfo(ErrorLevel.Verbose, "only run this statement if 'Verbose' logging is enabled");Performance Tuning
Neuron ESB is a platform used to develop complex integration solutions. To that end, every solution can vary in its workloads and performance characteristics. Therefore, it is essential that every solution be thoroughly tested against their expected workloads in a controlled environment before deploying to a final production environment. Neuron ESB contains a number of elements that users can tune to moderate, enhance and/or throttle workloads in an attempt to achieve the workload’s expected performance profile.
.NET Thread Overrides
One of the easiest things to change is how the Neuron ESB runtime interacts with the .NET thread pool. On startup, the Neuron ESB runtime and hosting environments will use threads from the .NET thread pool to start up internal services, Topics, Workflow Endpoints and individual endpoints like Adapters and Services. Generally, the .NET framework creates a Worker and IO thread per CPU/core, spinning up more automatically on demand. For example, if a machine were configured with eight cores/CPUs, there would be eight IO and Worker threads available to the process on startup. Usually it takes about ½ a second or so to spin up a new thread. If there were a need for several hundred, this would add latency on the initial request/response times. In the case of Neuron ESB, starting up an endpoint typically requires a dedicated thread. Hence, the more endpoints and topics defined in a Neuron ESB solution, the longer it will take to startup the solution.
If a solution expected “Bursts” of activity or a solution needed to start up faster, users should consider using the Neuron ESB thread pool override option that exists in the Configure Server dialog box as shown below. By using the override option, users can pre create these threads on startup so that the solution starts up faster and the system is ready to handle bursts of activity.
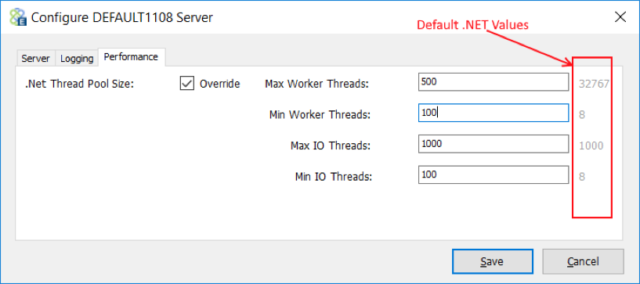
Two things directly affect the effectiveness of this option. The first is the number of cores/CPUs configured for the machine. The second is the number of Neuron ESB Endpoints and Topics defined in a solution.
For example, the fewer cores/CPUs configured for a machine, the less effective raising the Min Worker Threads and Min IO Threads will be since more threads will require more time slicing and context switching. Hence, for an 8-core machine, setting the value to 50, 100 or even 200 could be effective, depending on the complexity of the solution. However, raising the Min Worker and Min IO threads higher would more than likely degrade performance and cause timeouts due to the length of time it would take to spin up that many more threads as well as the context switching that would result. In addition, every new thread requires memory. More threads will result in a larger working set of memory being allocated to the Neuron ESB host process.
This is a useful tuning option for large solutions or those solutions that expect sudden bursts of activity. However, it must be tested and tuned specific to the target machine that it expects to be deployed to.
Database Connections and Sessions
Neuron ESB uses a Microsoft SQL Server database for several things, Workflow Tracking, Message Auditing as well as for a number of High Availability functions including the Single Instance option available on Service and Adapter Endpoints. This option ensures that only one instance of an endpoint will be active in a Neuron ESB server farm at any one time. If that endpoint goes down, another endpoint instance will automatically be started on the next free Neuron ESB machine.
Under heavy and sustained workflows, it was common to see many active sessions against the Neuron ESB database. An active session represents a connection to the database, even if the connection is not being actively used. For example, the connection may exist in the Connection Pool yet it will appear as an active session against the Microsoft SQL Server. By default, .NET allocates a Connection Pool at the app domain level, not the process level.
This was problematic in previous releases of Neuron ESB as endpoints were establishing connections to the database directly if configured for Single Instance mode. For example, if a solution had several hundred endpoints configured in Single Instance mode, it would result in several hundred active sessions being reported by the Microsoft SQL Server database. Those active sessions were not active connections but rather connections existing in the Connection Pool, but all consumed memory and resources on the Microsoft SQL Server.
We made several optimizations to reduce the number of active sessions/connections that Neuron ESB maintains against its database when connection pooling is enabled (which is by default). Among other things, we eliminated the per-endpoint Connection Pooling, which was occurring in previous builds. This eliminated the active sessions that were being allocated and reported for every endpoint within a solution. For tuning purposes, users should configure the Connection Pooling parameters of the Neuron ESB database to accommodate the level of Message Auditing that their solution may require. Those parameters are accessed by clicking the Edit button on the database definition within the Neuron ESB Explorer as shown in the picture below.
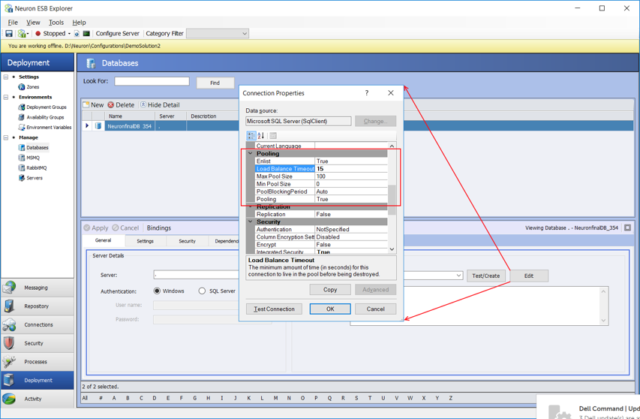
In addition, the “Load Balance Timeout” connection string parameter for the Neuron ESB database should be changed from the default of 0 to 15 to 60 seconds to ensure that connections that have not been used are removed from the pool. This ensures that in active connections are released from the Microsoft SQL Server.
Zone Settings
There are other important tuning parameters that should be modified based on the solution and the workloads the solution is expected to sustain. These are the Internal Server Bindings Settings located on the Server tab of the Solution’s Zone as shown below:
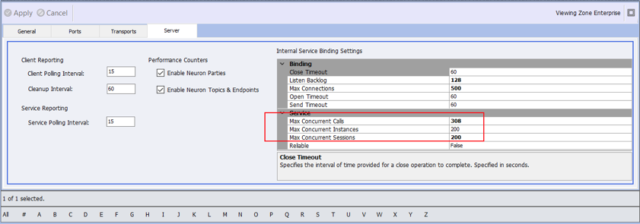
The three important settings to modify are Max Concurrent Calls, Max Concurrent Instances and Max Concurrent Sessions. All of the Internal Service Binding Settings directly affect Neuron ESB internal services, such as the Configuration, Auditing, Management and Control and should be configured to reflect the machine that the solution is being deployed to. Hence, these settings must be modified per deployment environment.
NOTE: These same three parameters exist on the Network Properties page of all TCP, Named Pipes and MSMQ based Topics. They also exist on the Client Connector tab of all Service Endpoints.
Generally, if there are enough .NET threads spun up in advance and the Maximum settings are sufficient, users should not have to extend the Open or Send Timeouts beyond 60 seconds. Once the Performance Update is installed, we suggest the Internal Service Binding Settings depicted below as general ones that should be used. The final settings should be determined through testing and using Performance Monitor to record the maximum values used by the solution. However, the settings below should be safe and effective for 90+% of customer scenarios.
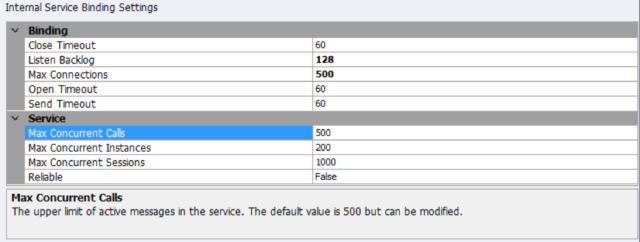
Maximum Concurrent Instances
Exclusively the Neuron ESB Message Audit Service uses the Maximum (i.e. Max”) Concurrent Instances parameter of the Internal Service Binding Settings. No other internal Neuron ESB service is affected by this setting.
Assuming users are running machines with eight or more cores, the recommended value for this setting is 100 to 200. The higher this number, the more instances are created at runtime when under load, and these instances will increase the memory allocated to the Neuron ESB runtime host. Users should always conduct performance testing against their specific workloads in an environment similar to their target production environment to determine the correct value for this setting.
Maximum Concurrent Sessions
In previous versions, Neuron ESB Parties and Endpoints maintained persistent connections (i.e. Sessions) to Neuron’s internal Control, Management and Configuration services. Increasing numbers of endpoints added to a solution could substantially increase the number of sessions required to be configured at the Zone level (i.e. Max Concurrent Sessions). In very large solutions, we have seen this number approach several thousand. If the value of the Max Concurrent Sessions was not configured high enough, endpoints would time out attempting to connect at startup or new endpoints could be blocked from connecting and users could experience errors similar to the ones below being reported in the Neuron ESB log files and Neuron ESB Event Log:
Event Info: The Child Service for ‘ServiceConnector_170’ failed to Start. The open operation did not complete within the allotted timeout of 00:01:00. The time allotted to this operation may have been a portion of a longer timeout.
Exception: The open operation did not complete within the allotted timeout of 00:01:00. The time allotted to this operation may have been a portion of a longer timeout.
Inner Exception: The socket transfer timed out after 00:00:59.9980005. You have exceeded the timeout set on your binding. The time allotted to this operation may have been a portion of a longer timeout.
Inner Exception: A connection attempt failed because the connected party did not properly respond after a period of time, or established connection failed because connected host has failed to respond
Or
Event Info: Service Connector ‘ServiceConnector_49’ failed to start. Unable to connect ‘Subscriber1’ Party to the Neuron Configuration Service at ‘net.tcp://localhost:50000/ESBConfigurationService/’. The open operation did not complete within the allotted timeout of 00:02:00. The time allotted to this operation may have been a portion of a longer timeout.
Additionally, this was also the root cause of timeout exceptions experienced by users when attempting to connect to a remote instance of Neuron ESB using either the Neuron ESB Explore or Test Client.
In the Performance Update, we removed persistent sessions. This resulted in a significant decrease in the number of sessions created against Neuron ESB internal services and dramatically reduced the incidences of blocking or timeouts when starting up or connecting to the Neuron ESB server.
As a general rule of thumb, we recommend that the Max Concurrent Sessions be set to a value equal to the sum of the total number of Adapter Endpoints, Service Endpoints, Topics and Workflow Endpoints + 50%. Unlike the Max Concurrent Instances setting, this setting does not allocate memory up front, but acts mostly as a restriction gateway.
Maximum Concurrent Calls
The optimum Maximum (i.e. “Max”) Concurrent Calls setting should be determined by adding the values of the following calculations:
- The total number of Adapter Endpoints, Service Endpoints and Topics defined in the solution divided by 4.
- The total number of concurrent workflows, which will be executing at runtime divided by 4.
- The total number of concurrent Message Audit requests made by the solution at runtime.
For example, given a Neuron ESB Solution with the following configuration and workload expectations, would require a minimum Max Concurrent Calls setting of 525:
- Total of 400 Adapter Endpoints, Service Endpoints and Topics = 100
- 100 concurrent workflows executing = 25
- 400 concurrent Message Audit requests made by the system = 400.
NOTE: Every connected Neuron ESB Party makes a connection to the internal services and establishes a session.
Lastly, adding a buffer onto the final number can be a best practice as the Max Concurrent Calls setting does not allocate memory up front, but acts mostly as a restriction gateway.
Measuring Performance Metrics
To determine the optimum values for the performance related settings in a Neuron Solution it is critical to simulate the expected peak workload within an environment that closely resembles (i.e. resources such as CPU, memory, OS and disk configuration) the target production environment. During testing, it is essential that a reliable means is used to measure and document the performance profile of the workload against the solution. The Windows Performance Monitor is a very common tool used for this purpose. Windows Performance Monitor is a Microsoft Management Console (MMC) snap-in that provides a graphical interface for customizing Data Collector Sets and Event Trace Sessions. It allows users to view in near real time resource information for the Windows Management Instrumentation (WMI) Performance Counters that applications expose.
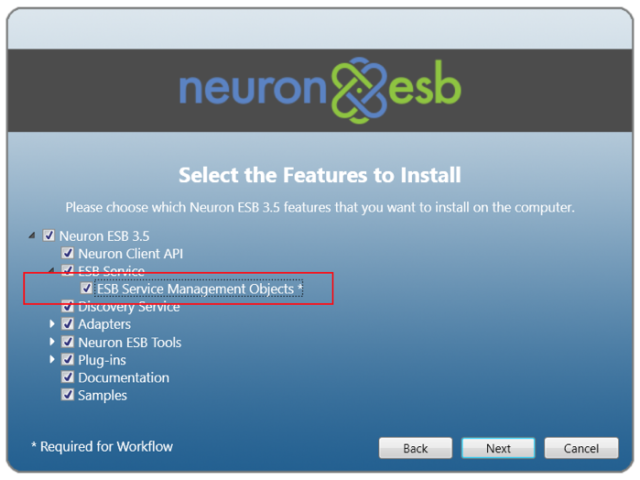
Neuron ESB can expose all of its Endpoints, Topics and Parties using WMI events and Performance Counters. To fully enable Neuron ESB WMI Performance Counters two things must be done. First, the “ESB Service Management Objects” feature must be selected during the installation of Neuron as shown below:
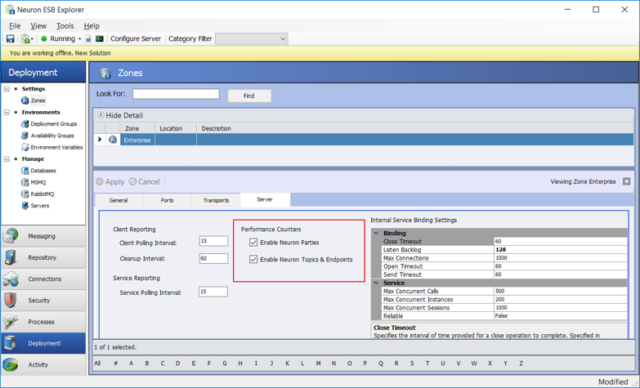
Second, the Performance Counters options must be enabled on the Server tab of the Zone within the Neuron ESB Solution.
When these options are enabled, the following Neuron ESB WMI Performance Counters will be available for selection and monitoring within Performance Monitor as shown below:
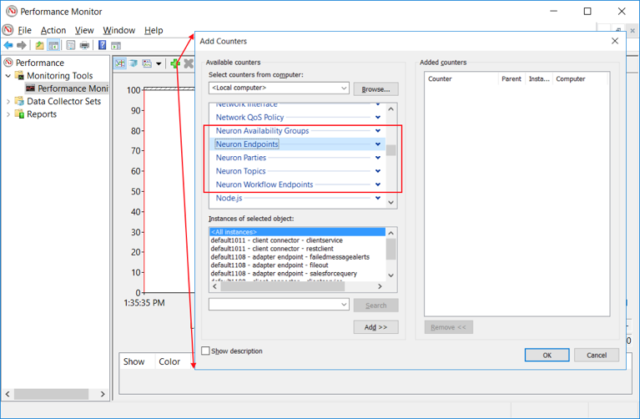
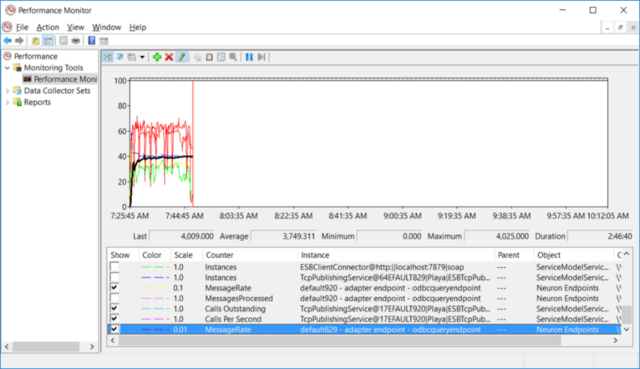
All of the Neuron ESB Performance Counters expose a similar set of objects that can be measured for every instance of that object. For example, if Neuron Endpoints is expanded, any or all of the following counters can be selected for any or all of the individual endpoints:
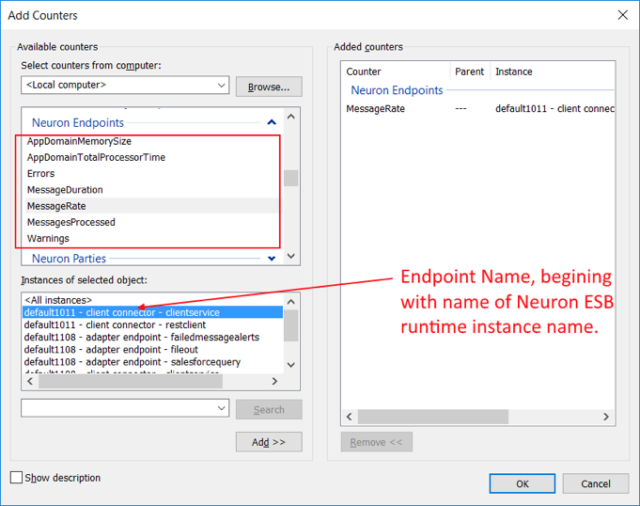
The object instance of the Neuron ESB entity to measure follows a simple naming convention i.e. Runtime Instance Name – Type of Endpoint – Name of Endpoint.
The Neuron ESB WMI Performance Counters can be useful to measure the number of requests or messages being processed at any point in time or over a period of time (i.e. messages per second) for any Neuron ESB Entity.
However, to determine the correct values for Max Concurrent Sessions, Max Concurrent Instances and Max Concurrent Calls, the “ServiceModelService 4.0.0.0” counter needs to be selected. This exposes a number of Windows Communication Foundation (WCF) specific objects that can be monitored, measured and collected at runtime. More importantly, it provides a way of measuring Maximum percentage of Sessions, Instances and Calls Per Second used at runtime as shown below:
More information about WCF specific Performance Counters can be found here: https://docs.microsoft.com/en-us/dotnet/framework/wcf/diagnostics/performance-counters/.
Although the number of Instances and Calls at any time can be measured and recorded, there is no way to measure the number of current Sessions using these Performance Counters. Only the Percent of the Max Concurrent Sessions can be measured. But combined, these will provide users with the numbers necessary to tune the parameters correctly.
To determine the best value for the Max Concurrent Sessions, Instances and Calls settings found in the Zone settings, users must select the Neuron ESB Internal Services that these settings govern, specifically:
- Message Audit Service
- Configuration Service
- Control Service
- Management Service
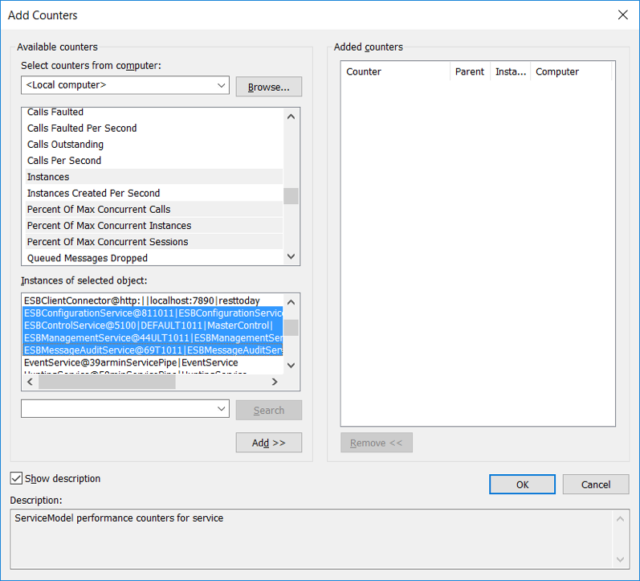
The Neuron ESB Internal Services can be selected under the “Instances of selected object” section of the Performance Monitor’s Add Counters dialog box. The naming convention for these are as follows:
| Instance Name | Description |
| ESBConfigurationService@* | Represents the Neuron ESB Configuration Service |
| ESBControlService@* | Represents the Neuron ESB Control Service |
| ESBManagementService@* | Represents the Neuron ESB Management Service |
| ESBMessageAuditService@* | Represents the Neuron ESB Message Audit Service |
Additionally, Client Connectors, TCP and Named Pipes based Topics can be measured using the ServiceModelService Performance Counters.
| Instance Name | Description |
| ESBClientConnector@* | Represents a Neuron ESB Client Connector (web hook) |
| NamedPipePublishingService@* | Represents a Neuron ESB Named Pipes-based Topic |
| TcpPublishingService@ | Represents a Neuron ESB TCP-based Topic |
| PubSubClient@ | Represents a Neuron ESB Party connected to a TCP/Named Pipes Topic |
Once the proper counters and endpoint instances are selected within Performance Monitor, their Maximum values should be recorded when testing the solution against its peak expected workload. That should provide a good estimate for the correct values to set the parameters to.
For Neuron ESB Client Connectors, their respective settings for Max Concurrent Calls, Max Concurrent Instances and Sessions are located on the Client Connector tab of the Service Endpoint. Since these are all Instance based, setting the Maximum Concurrent Instances value no higher than 100 or 200 (depending on machine resources) is recommended.
About the Author
Marty has almost 30 years of experience in the software development industry. He joined Peregrine Connect after six years as a Regional Program Manager in the Connected Systems Division at Microsoft. His responsibilities there included building out Microsoft’s BizTalk Server product integration business, managing a team of SOA/ESB/BPM field specialists and building strategic partner alliances. Marty created the Microsoft Virtual Technical Specialist program and owned the development of Microsoft’s Enterprise Service Bus Toolkit.
Read more about Peregrine Connect

-
Rabbit MQ Topics
Introduction Due to the open-source nature of RabbitMQ and constant updates, it is...
-
Port Sharing
One of Neuron ESB’s scalability features is the ability to install multiple...

-
The Integration Journey to...
The Integration Journey to Digital Transformation with Peregrine Connect
-
Saving Time and Money by...
Neuron ESB Application Integration and Web Service Platform: A Real-World Example...

-
Neo PLM
-
Loomis Case Study
Loomis Chooses Peregrine Connect as Their No/Low-Code Integration Platform:...

-

Decision Test Data Mapping
- Use decisions to drive the execution of...
-
Map Testing
Learn how to utilize FlightPath's testing functions...