Neuron ESB has always supported Microsoft Failover Cluster Services as one way to obtain high availability on the Microsoft platform. This is especially useful when working with durable data stores like databases or queues.
Recently, we noticed operational issues with our current support, mostly related to the Client Access Point name (sometimes called the virtual Netbios name) within the Neuron ESB related clustered Role. In short, we were still defaulting to the underlying host name rather than the Client Access Point name for most operational functions. Though this had little impact on the run-time environment, it caused confusion for the operational environment.
For example, in an Active/Passive Microsoft Failover Cluster, the two underlying physical host machines would have specific Netbios names assigned to them (in our example, lets assume NeuronDev01 and NeuronDev02). Within Failover Cluster Manager a Role could be created that includes the Disk resources, the Neuron ESB Service, Neuron ESB Discovery Service, MSMQ and the MSDTC. A Client Access Point (we called ours NeuronServer) would be added that represents the Netbios name for these resources. In effect a Role represents a virtual machine environment (without a dedicated OS :)).
One reason for placing all of these resources into the same Role is to ensure all transactions between the Neuron ESB run-time and MSMQ are local in nature, rather than remote due to the use of the MDTC. It should be noted however that transactions are optional for Neuron ESB MSMQ based Topics. Also, Neuron ESB supports Rabbit MQ based Topics as well, which do not necessarily require Microsoft Failover Cluster Services for high availability.
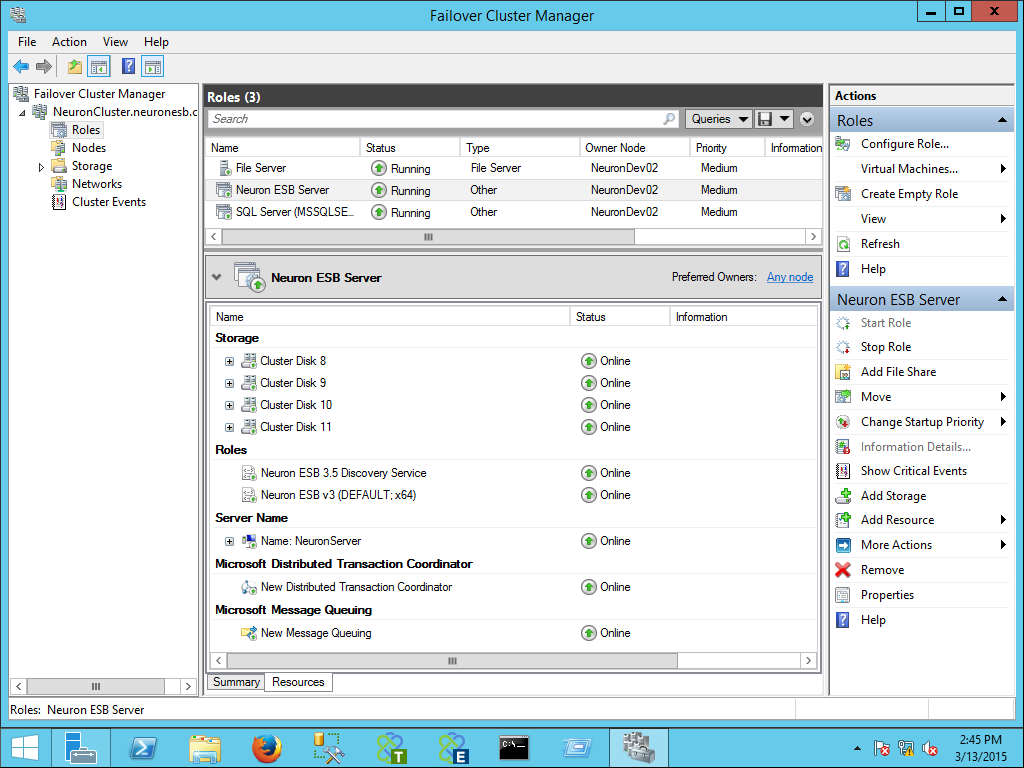
Once the Client Access Point name is created, the Role can be started on one of the available host machines and broadcast on the network as a virtual machine with the Netbios name of NeuronServer. NeuronServer now becomes the Netbios name that all external resources would use to request any service of Neuron ESB. Operations would also use this same Netbios name to monitor the cluster. If for any reason the underlying host machine failed, all the resources defined in the Role (including the Client Access Point name) would simply role over to the other host machine, start up and run as NeuronServer again.
Besides not working as well as we could have with the Client Access Point name, we did find a few of the newer features within Neuron ESB that did not work correctly in a clustered Role, specifically our built in MSMQ management features, Workflow and some Endpoint Health management features.
The Neuron ESB 3.5 QFE 31 patch should be considered a must have if running Neuron ESB as a Generic Application within a Microsoft Failover Cluster Services’ defined role. Some of the more specific issues addressed in this QFE related to clustered are:
- Endpoint Health – The ability to stop and restart Topics and Endpoint services did not work if the Neuron ESB runtime was configured as a clustered Generic Application.
- Endpoint Health – Host Name column did not reflect the Client Access Point name of the resource group (Role) in which the Neuron ESB Service run-time belongs to.
- Workflow – Workflow Availability Groups did not recognize the Client Access Point name in the machines tab of the Deployment Group and start up as expected.
- RESTful Operational Services – REST calls to get /neuronesb/api/v1/runtime would return the host name rather than the Client Access Point name.
- Auditing Reporting – Message History and Failed Message reports would reflect the host name in the Machine column rather than the Client Access Point name.
- Active Sessions Reporting – The host name would be reflected in the Machine column rather than the Client Access Point name.
- WS-Discovery – The host name rather than the Client Access Point name would be announced and displayed in the Connect dialogs of the Neuron ESB Explorer and Neuron ESB Test Clients.
- MSMQ Management – The message count function of the Neuron ESB Explorer’s MSMQ Management screen would always return zero for clustered, remote MSMQ queues.
- MSMQ Management – Editing and saving messages back to their underlying queue would fail for clustered, remote MSMQ queues.
- Workflow Tracking – The host name would be reflected in the Machine column rather than the Client Access Point name.
- WMI EndpointStateChangeEvent – This event was not firing for the Client Access Point name after manually registering the event.
- Endpoint Health – Rate and Items columns for workflow endpoints may not increment at run-time.
- Neuron Logging – Microsoft Failover Cluster Server events were being captured in the Availability Group neuron log files
- Neuron Logging – The host name would be reflected in the log files rather than the Client Access Point name.
Since we already had the engine cracked open so to speak, we decided to get some additional fixes in this as well. All the details of what is included in the Neuron ESB 3.5 QFE 31 patch and how to install it can be found in the following KB article:
Neuron ESB 3.5 QFE 31 KB Article
I think my team did some really great work on this one!
About the Author
Marty has almost 30 years of experience in the software development industry. He joined Peregrine Connect after six years as a Regional Program Manager in the Connected Systems Division at Microsoft. His responsibilities there included building out Microsoft’s BizTalk Server product integration business, managing a team of SOA/ESB/BPM field specialists and building strategic partner alliances. Marty created the Microsoft Virtual Technical Specialist program and owned the development of Microsoft’s Enterprise Service Bus Toolkit.
Read more about Peregrine Connect

-
Rabbit MQ Topics
Introduction Due to the open-source nature of RabbitMQ and constant updates, it is...
-
Port Sharing
One of Neuron ESB’s scalability features is the ability to install multiple...

-
The Integration Journey to...
The Integration Journey to Digital Transformation with Peregrine Connect
-
Saving Time and Money by...
Neuron ESB Application Integration and Web Service Platform: A Real-World Example...

-
Neo PLM
-
Loomis Case Study
Loomis Chooses Peregrine Connect as Their No/Low-Code Integration Platform:...

-

Decision Test Data Mapping
- Use decisions to drive the execution of...
-
Map Testing
Learn how to utilize FlightPath's testing functions...